







前面几节我们讨论了SVM原理、求解线性分类下SVM的SMO方法。本节将分析SVM处理非线性分类的相关问题。
一般的非线性分类如下左所示(后面我们将实战下面这种情况):
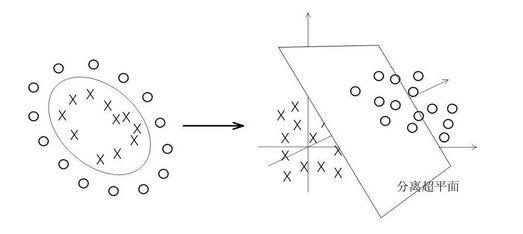
可以看到在原始空间中你想用一个直线分类面划分开来是不可能了,除非圆。而当你把数据点映射一下成右图所示的情况后,现在数据点明显看上去是线性可分的,那么在这个空间上的数据点我们再用前面的SVM算法去处理,就可以得到每个数据点的分类情况了,而这个分类情况也是我们在低维空间的情况。也就是说,单纯的SVM是不能处理非线性问题的,说白了只能处理线性问题,但是来了非线性样本怎么办呢?我们是在样本上做的文章,我把非线性样本变成线性样本,再去把变化后的线性样本拿去分类,经过这么一圈,就达到了把非线性样本分开的目的,所以只看开头和结尾的话发现,SVM竟然可以分非线性问题,其实呢还是分的线性问题。
现在的问题是如何找到这个映射关系对吧,就比如上面那个情况,我们可以人为计算出这种映射,比如一个样本点是用坐标表示的(x1,x2),它有个类标签,假设为1,那么把这个点映射到三维中变成 (x21,2√x1x2,x22) 。对每个点我都这么去映射,假设一个原始点样本集是这样的:
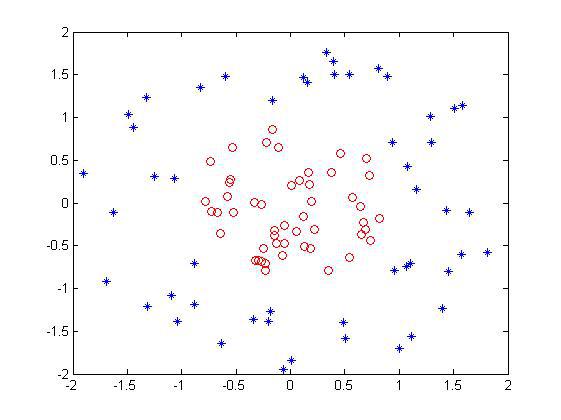
然后按照上面那个公式去把每个点映射成3维坐标点后,画出来是这样的:

可以看到是线性可分的吧,如果还看不清把视角换个角度(右视图):
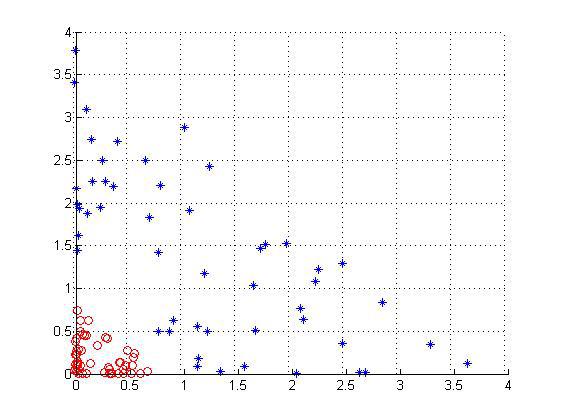
现在能看清楚了吧。
那这是二维的点到三维,映射的关系就是上面的那个关系,那如果是三维到四维,四维到N维呢?这个关系你还想去找吗?理论上是找的到的,但是实际上人工去找你怎么去找?你怎么知道数据的映射关系是这样的是那样的?不可能知道。然而我们真的需要找到这种关系吗?答案是不需要的,返回去看看前三节的关于SVM的理论部分可以看到,无论是计算 α 呀,还是b呀等等,只要涉及到原始数据点的,都是以内积的形式出来的,也就是说是一个点的向量与另一个点的向量相乘的,向量内积出来是一个值。
就拿 α 的更新来说,如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5965
5965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









