









时间线

Motivation
Yolo-v1是在检测精度尚可的前提下达到了实时检测,同年的SSD检测速度略慢但检测精度远高于Yolo-v1,因此,Yolo-v2则是着眼于检测得更快更准,同时它利用WordTree创造性地将ImageNet和coco结合起来构建了beyond coco的Yolo9000,为后续的研究、工程应用打开了一扇门。
Better
-- Batch normalization
通过采用BN而不是dropout来达到预防overfitting的目的,mAP提升2%.
-- High Resolution Classifier
首先在224x224的尺度上训练分类网络,然后使用448x448适应训练几个epoch,然后再进行detection任务的训练,mAP提升4%.
-- Convolutional With Anchor Boxes
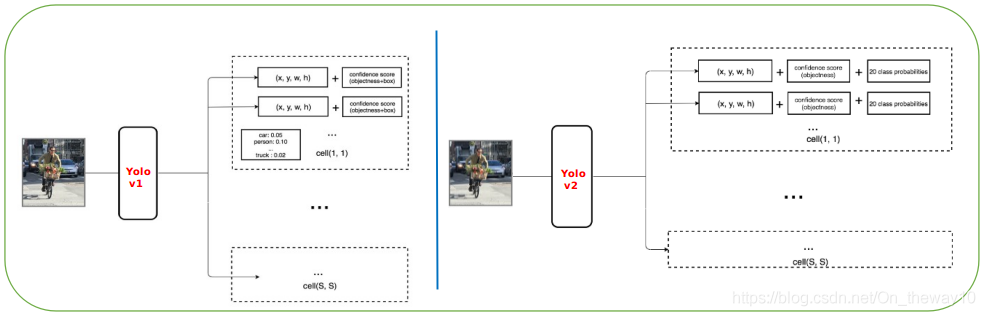
对于特征图上的每个网格对应的bbox,Yolo-v1采用随机猜的策略,导致训练困难、检测精度受损;因此,为了避免随机猜的情况,受Faster RCNN和SSD的启发,Yolo-v2也引入了anchor机制。具体地,对于每个网格我们生成K(K=5)个priors boxes:

然后预测priors boxes的offset,同时将Yolo-v1中Pr(Class_i|Obj)从cell-level下放至bbox-level,这样每个prior box就对应一个含有(4+1+C)个分量的预测结果,其中C表示数据集中包含object的类别数。下图给出了采用priors boxes后的预测流程:
-- Image input size : 448 x 448 --> 416 x 416
获得的feature_map从原来的7 x 7变为resolution更高的13 x 13.
-- Dimension Clusters
与Faster RCNN、SSD等采用anchor机制的detection方法不同的是,Yolo-v2在设定prior boxes时采用了Data Driven的思想。我们来看,日常生活中常见object的宽高比并非任意的,它们具有某种规律,因此Yolo-v2采用k-means聚类方法对训练集中的truth_bboxes进行聚类,并得到如下图所示的观测数据:

需要补充的一点是,在聚类时距离度量没有采用bbox的空间距离,而是采用如下的方式:
d(box, centroid) = 1 − IOU(box, centroid)
为了便于对比聚类效果,这里以COCO2017-val样本为例,可视化聚类数目依次为3,5,7,9,11的效果图:

随着聚类个数增多,样本划分越发紧凑,但是越大的K值意味着模型训练、推理时速度越慢;聚类代码如下:
def compute_iou(x, centers):
num_samples, K = len(x), len(centers)
ious_mat = np.zeros((num_samples, K))
for k in range(K):
center = centers[k]
w_arr = x.copy()
w_arr[:, 1] = np.repeat(center[0], num_samples)
min_w = w_arr.min(axis=1)
h_arr = x.copy()
h_arr[:, 0] = np.repeat(center[1], num_samples)
min_h = h_arr.min(axis=1)
inter = min_w * min_h
union = x[:, 0] * x[:, 1]
ious_mat[:, k] = inter / (union + center[0] * center[1] - inter + 1e-6)
return ious_mat
def get_anchor_statistics_infos(data, K=5):
num_samples = len(data)
centers = data[np.random.choice(a=num_samples, size=K, replace=False)]
pre_centers = centers.copy()
pre_max_center_ids = np.zeros(num_samples, dtype=np.int64)
step = 0
max_iters = 10000
while True:
ious = compute_iou(x=data, centers=centers)
max_center_ids = np.argmax(a=ious, axis=1)
pre_centers = centers.copy()
if np.all(max_center_ids == pre_max_center_ids) or step >= max_iters:
if step >= max_iters:
print('Does not converage before %06d iters ...' % max_iters)
else:
print('Cluster converaged!')
break
centers = np.zeros_like(centers, dtype=np.float32)
for j in range(K):
target_x_index = max_center_ids == j
target_x = data[target_x_index]
centers[j] = np.sum(target_x, axis=0) / np.sum(target_x_index)
pre_max_center_ids = max_center_ids.copy()
step += 1
return (pre_centers, pre_max_center_ids)
-- Direct location prediction

左侧为Faster RCNN中bbox的预测参数关系,右侧为Yolo-v2的参数预测关系,它们主要的区别在于bx和by的预测关系。具体体现在:Faster RCNN中的bx和by不受限制,而Yolo-v2则将bx和by限制在参考网格内部!。具体的loss设计如下:

-- Fine-Grained Features
- Backbone

- Pass through

这里,YoloV2借鉴SSD使用多尺度特征图来提升检测效果的方法,提出pass through层将高分辨率特征图与低分辨率特征图拼接在一起,从而更好地利用多尺度特征来检测目标。
- Architecture
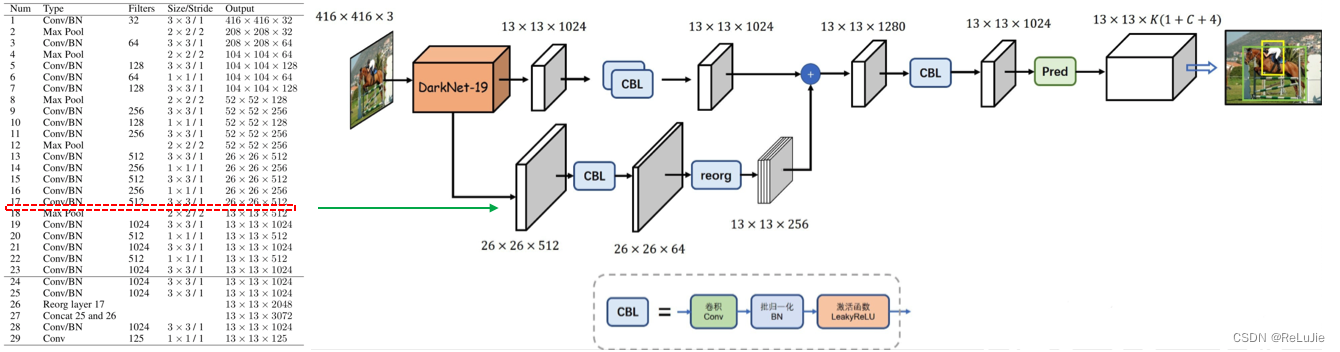
-- Multi-Scale Training
因为Yolo-v2的网络框架中去掉了fully connected layers,因此网络可以接受不同size的image,eg:Yolo-v2采用的采样因子为32,当input-size为320时,输出为[batchsize, 100, len(priors)+1+C];当输入是608时,输出为[batchsize, 361, len(priors)+1+C].论文指出,在训练Yolo-v2时,每隔10个epoch从[320, 352, ..., 608]中选择一个新的size最为input_size对网络进行训练。这样做的好处是:模型可以更好地适应不同image-resolution的detection任务。
-- Accuracy

Faster
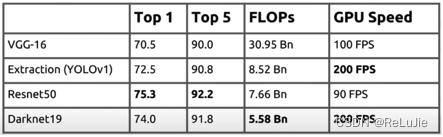
- FLOPS
| backbone | operations(billion) | accuracy(ImageNet) |
| VGG16 | 30.69 | 90.0% |
| GoogLeNet | 8.52 | 88.0% |
| DarkNet-19 | 5.58 | 91.2% |
- Speed

Yolo-v2的backbone网络采用了操作量更少、但分类效果更佳的DarkNet-19, 具体计算量、检测指标如下图所示:
受GoogLeNet、NIN的启发,DarkNet的卷积核采用了3x3,1x1的尺寸,前者用于feature提取,后者用于feature降维。在detection的工程实现时,最后一层的1x1的Conv层、Avgpool层被替换为3x3[特征融合]和1x1[降维输出]的Conv-layer。下图给出了Yolo-v2的完整流程图:

Stronger
Yolo-v2在解决了better、faster这两个核心问题之后,顺便提出了联合COCO和ImageNet来训练更为强大的Yolo9000.它需要解决如下两个问题:
- 不同数据集的标签怎么合并?[直接合并不能保证标签之间的互斥性,从而使得不能直接用softmax来计算各类的概率]
- 分类数据无bbox信息,如何在detection网络中应用分类数据?
-- WordTree
下图是COCO和ImageNet的标签体系:


Yolo-v2中作者基于自下而上的层次结构构造的WordTree标签体系:
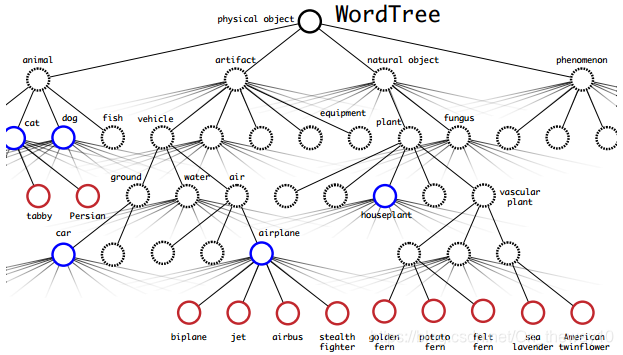
这样做的好处是,同一层级内的各个标签是互斥的,因此可以使用softmax来计算概率。以ImageNet-1000为例,作者构建了一棵含有369个内部节点的WordTree,在训练模型时采用向上传递标签的方式,例如:如果一张image被标记为Norfolk terrier,那么它也会被同时标记为它的一系列父节点:dog、mammal ... 为了计算条件概率,网络会输出1369个score,然后计算对相应分支的节点计算softmax概率:
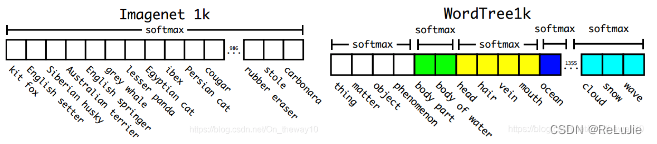
采用WordTree的标签体系的好处是它可以充分利用层次结构,例如,当模型遇到一张狗的照片但不确定是哪种狗的时候,模型会输出高置信度的标签“狗”,而不是强行把它分为某个低置信度的狗的子类目。
-- Train/Test
在训练时,当输入的是detection(来自coco)的图片时,bbox的loss照旧;classification的loss只计算当前预测label在WordTree对应level及上游层中依赖节点的损失;当输入的图片来自ImageNet时,仅仅反传classification-loss.















 3067
3067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











