






 文章介绍了一种新的神经网络架构LACV-Net,它通过局部自适应特征增强、聚合损失函数和综合VLAD模块解决大规模点云语义分割中的局部感知模糊性和全局特征捕捉问题。实验证明LACV-Net在S3DIS、Toronto3D等基准上表现出色,提升了3D点云场景的准确分割和分类能力。
文章介绍了一种新的神经网络架构LACV-Net,它通过局部自适应特征增强、聚合损失函数和综合VLAD模块解决大规模点云语义分割中的局部感知模糊性和全局特征捕捉问题。实验证明LACV-Net在S3DIS、Toronto3D等基准上表现出色,提升了3D点云场景的准确分割和分类能力。
Zeng, Z., Xu, Y., Xie, Z., Tang, W., Wan, J., & Wu, W. (2024). Large-scale point cloud semantic segmentation via local perception and global descriptor vector. Expert Systems with Applications, 246, 123269. https://doi.org/10.1016/j.eswa.2024.123269
大规模点云语义分割通过局部感知和全局描述符向量
大规模点云语义分割是环境信息感知的一个关键方面,在自动驾驶、遥感和虚拟现实系统等领域有着广泛的应用。当前点云语义分割的方法通常采用K-最近邻(KNN)算法来学习局部特征。然而,这种方法引入了关于局部感知模糊性的问题,同时有效地捕捉分散在大规模场景中的全局特征仍然是一个重要挑战。为了解决这些局限性,我们提出了LACV-Net,一种专门用于大规模点云语义分割的神经架构。我们的LACV-Net包括三个主要元素:(1) 局部自适应特征增强(LAFA)模块,自适应地学习本地邻域之间的相似度权重,从而增强局部信息并减轻局部感知模糊性。(2) 聚合损失函数,使用相似度加权(从我们的LAFA模块导出)的邻域特征作为偏移,引导收敛到质心特征,从而限制相似度权重并进一步减轻局部感知模糊性。(3) 综合的局部聚合描述符(C-VLAD)模块,无缝地融合多个分辨率表示中的局部特征,生成全面的全局描述向量,从而更有效地捕捉全局上下文。我们在S3DIS、Toronto3D和SensatUrban等多个基准测试上评估了LACV-Net与最先进的网络的性能。结果表明,LACV-Net在准确分割和分类大规模3D点云场景方面具有卓越的效能,突显了其推进环境信息感知的潜力。
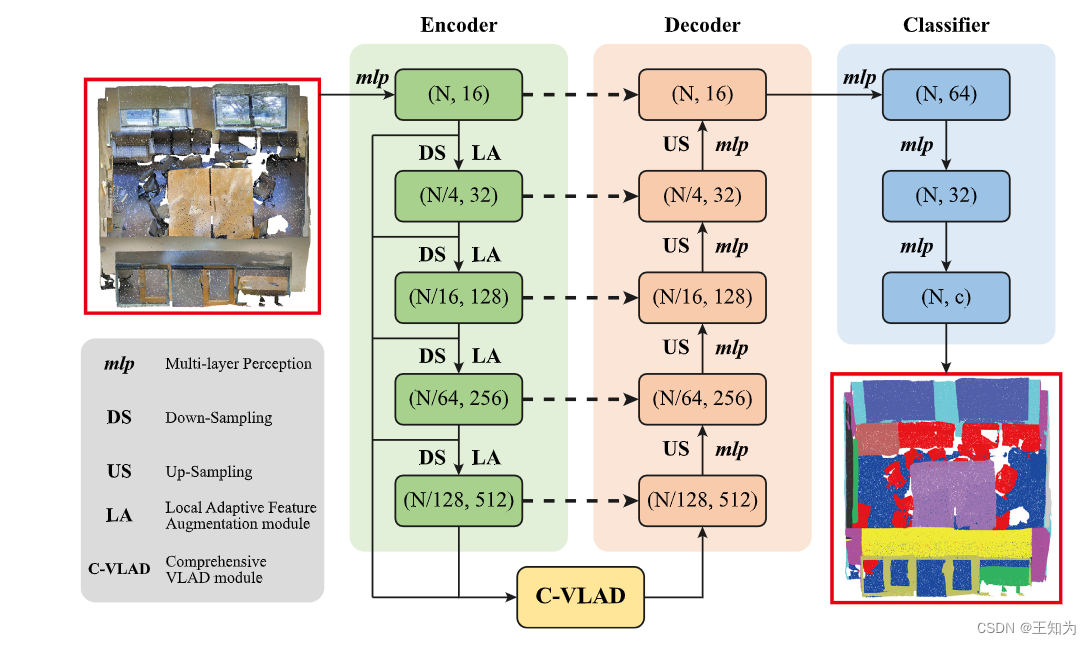
图1. 提出网络的架构。
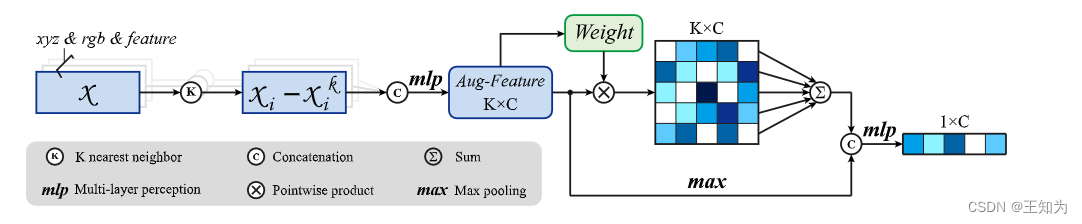
图2. 展示局部自适应特征增强模块。
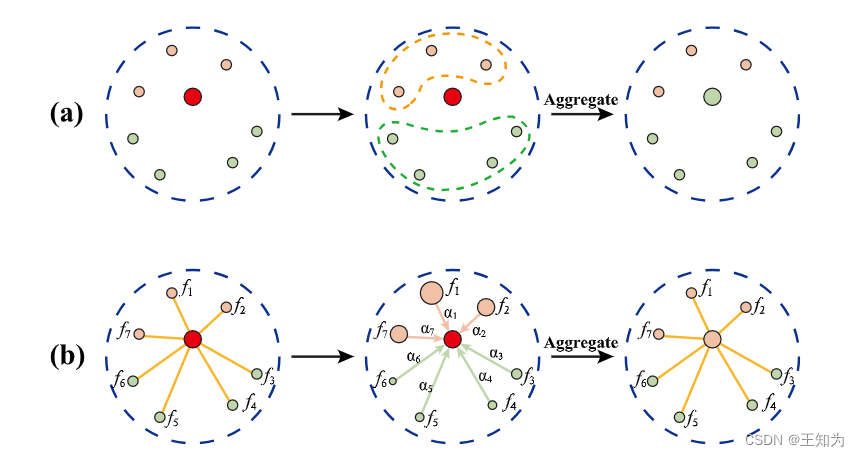
图3. 是否使用自适应权重的示意图。 (a) 示范了无自适应权重,而 (b) 示范了有自适应权重。
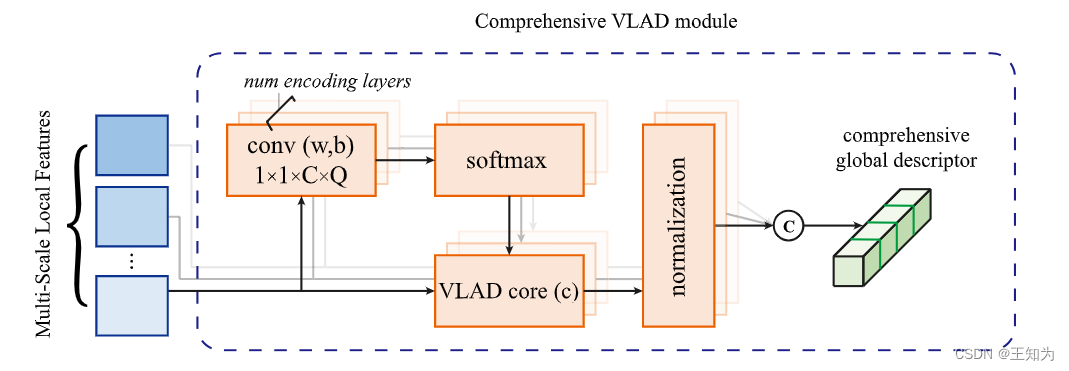
图4. 综合VLAD模块的示意图。
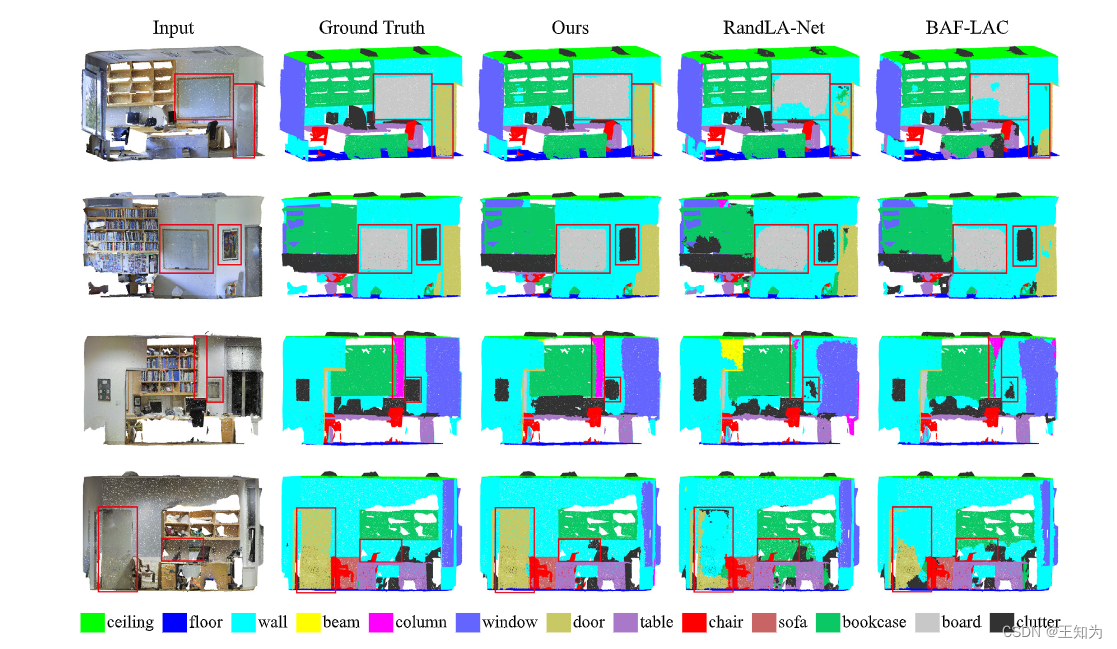
图5. 在S3DIS上的视觉比较。
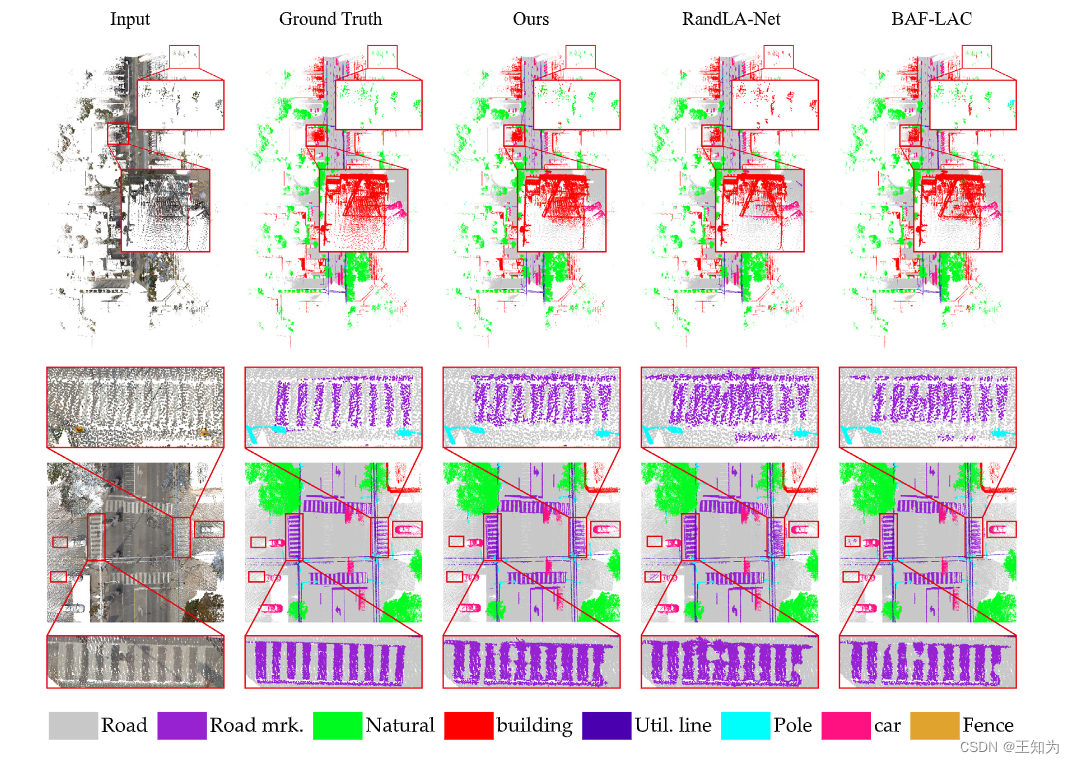
图6. 在Toronto3D上的视觉比较。
















 1677
1677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











