







 本文介绍了序列到序列任务中的Transformer网络结构,包括编码器-解码器模型和注意力机制。Transformer利用自注意力和多头注意力解决了长距离依赖问题,其中键值对注意力机制改进了柔性注意力机制。此外,位置编码用于弥补注意力机制忽略输入位置信息的缺点。整体而言,Transformer已成为通用特征提取器,在序列转换任务中表现出色。
本文介绍了序列到序列任务中的Transformer网络结构,包括编码器-解码器模型和注意力机制。Transformer利用自注意力和多头注意力解决了长距离依赖问题,其中键值对注意力机制改进了柔性注意力机制。此外,位置编码用于弥补注意力机制忽略输入位置信息的缺点。整体而言,Transformer已成为通用特征提取器,在序列转换任务中表现出色。
1. 序列到序列任务中的编码器-解码器架构
Transformer :通用特征提取器
- seq2seq (一种任务类型)从原序列到目标序列 例:翻译任务
- encoder-decoder 完成seq2seq的其中一种网络结构
- attention机制
RNN Encoder-Decoder网络架构
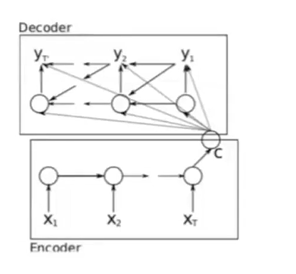
使用循环神经网络,将变长源序列X编码成定长(难点)向量表示c,并将学习的定长向量表示c解码成变长木变序列Y。
2.序列到序列任务中的注意力机制
Seq2Seq with Attention网络架构
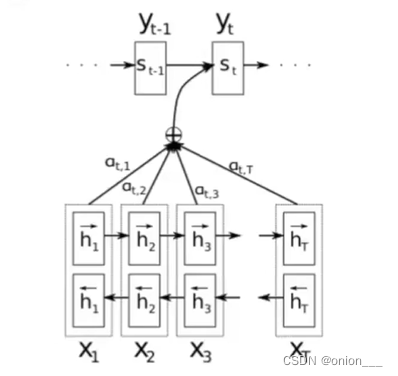
加权平均
3. Attention机制 (没有序列顺序)
3.1 柔性注意力机制
输入信息X=[x1…xN]
注意力机制计算:
- 在输入信息上计算注意力分布
- 根据注意力分布计算输入信息的加权平均
注意力分布
给定一个和任务相关的查询向量q,用注意力变量z∈[1,N]表示呗选择信息的索引位置,即z=i表示选择了第i个输入信息。其中,查询向量q可以是动态生成的,也可以是可学习的参数。
注:大部分情况下q取的是当前序列的前序序列
柔性注意力的注意力分布:
在给定输入信息X和查询变量q下,选择第i个输入信息被选中的概率 :
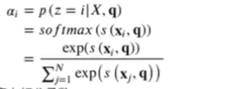
其中,αi称为注意力分布,s(xi,q)称为注意力打分函数
注意力打分函数:(缩放点积最常见)
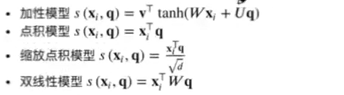
如下图,在柔性注意力机制中,输入X不仅要参与计算αi,还要参与最后的加权平均计算。键值对注意力机制改善了这个问题。
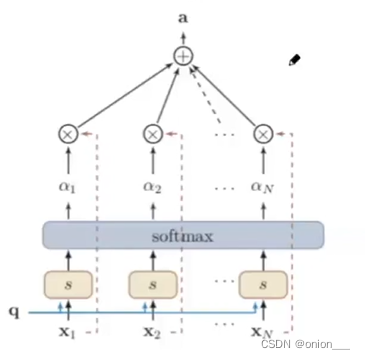
3.2 键值对注意力机制
输入信息为(K,V),其中键用来计算注意力分布αi,值用来计算聚合信息。 k,v通常不相等
当K=V时,键值对注意力机制等价于柔性注意力机制
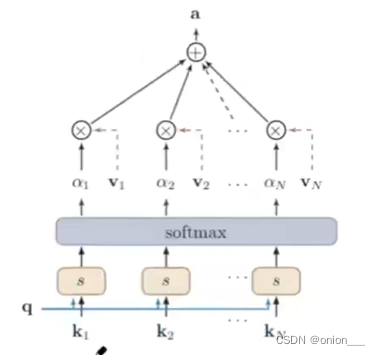
3.3 自注意力机制
提出三个新的向量,在k,v,q中,最重要的是v, v就是输入序列X的线性变换,包含了X的全部信息
减少了对外部信息的依赖,更擅长捕捉数据或者特征内部相关性,主要通过计算单词间的相互影响来解决长距离依赖问题
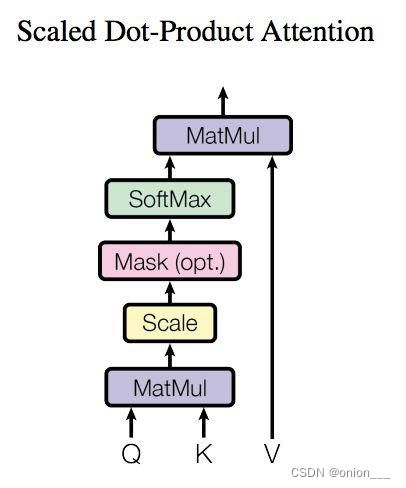

3.4 多头注意力机制
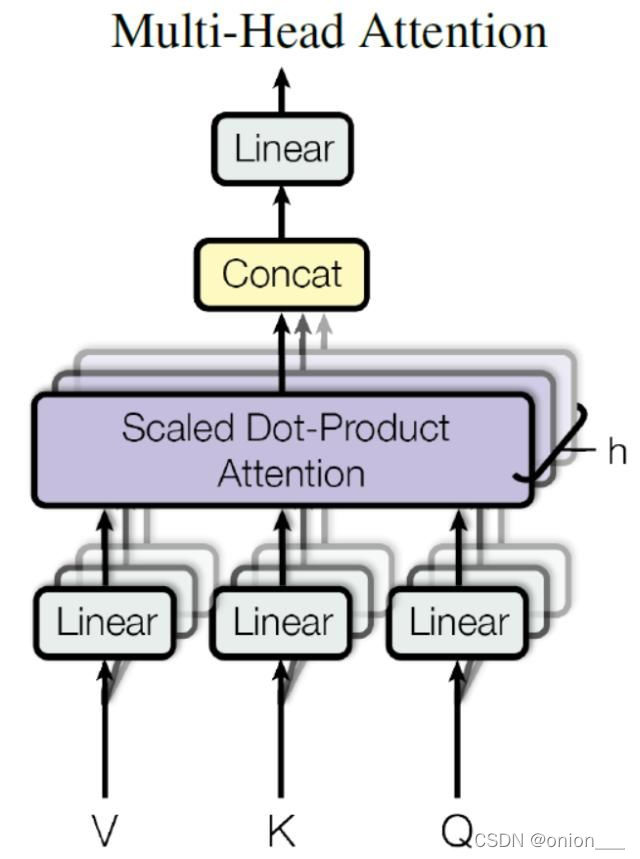
attention缺点:
没有考虑输入的位置信息,
解决:transformer位置嵌入,位置编码
4. Transformer通用特征提取器
用attention机制在encoder-decoder架构下完成seq2seq任务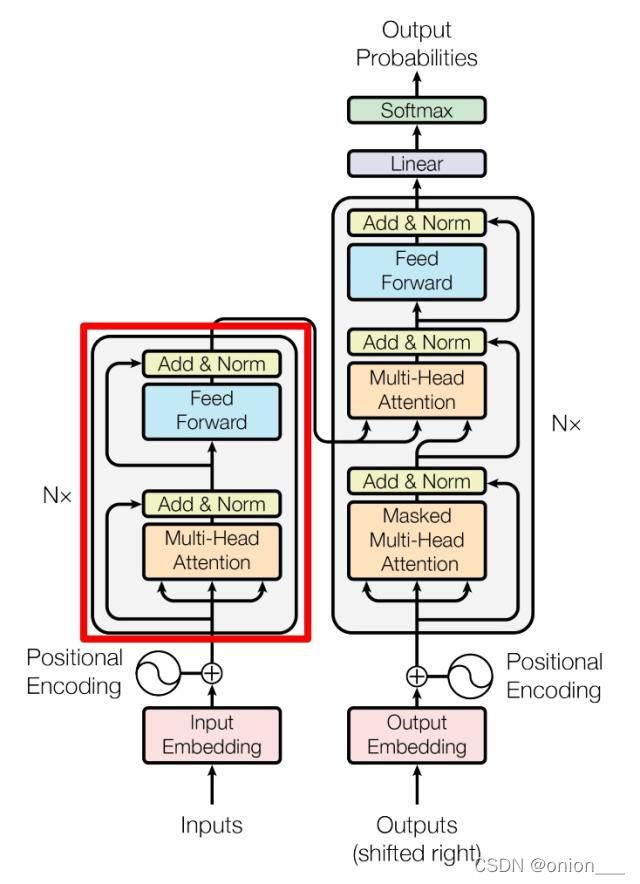
详细讲解:https://zhuanlan.zhihu.com/p/338817680

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









