






CNN(卷积神经网络)和Transformer的差异
CNN(卷积神经网络)和Transformer在图像编码器中提取的特征存在显著差异,主要体现在以下几个方面:
-
特征提取方式:
- CNN:CNN通过卷积核提取图像的局部特征,如点、线和局部纹理。这些特征通常在较低层次上表示,具有明显的几何特性,关注图像的平移、旋转等变换下的不变性。CNN通过分层提取特征,从低级到高级逐步抽象出更丰富的语义信息。
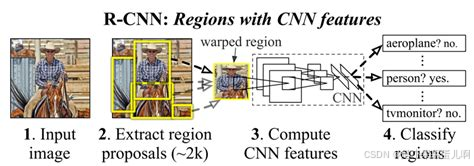
- Transformer:Transformer通过自注意力机制提取全局特征,能够捕捉图像中的长距离依赖关系和全局上下文信息。Transformer将图像分割成多个块(patch),每个块独立编码,然后通过多头注意力机制聚合不同块之间的关系。Transformer的特征图更加“抽象”,能够更好地捕捉深层次的语义信息。
- CNN:CNN通过卷积核提取图像的局部特征,如点、线和局部纹理。这些特征通常在较低层次上表示,具有明显的几何特性,关注图像的平移、旋转等变换下的不变性。CNN通过分层提取特征,从低级到高级逐步抽象出更丰富的语义信息。
-
特征表示:
- CNN:CNN编码的是邻近像素之间的相关性,依赖于卷积核的位置和大小。随着网络深度增加,感受野逐渐扩大,但仍然主要关注局部区域。
- Transformer:Transformer通过位置嵌入(position embedding)引入位置信息,使得模型能够处理序列化的图像块。Transformer的特征表示不依赖于卷积核,而是通过自注意力机制动态地结合不同区域的信息。
-
计算效率和资源消耗:
- CNN:CNN具有较高的计算效率,适合实时处理和资源受限的应用场景。CNN通过卷积层和池化层逐步降低特征图的维度,减少计算量。
- Transformer:Transformer需要更多的计算资源和内存,尤其是在处理高分辨率图像时。Transformer通过多头注意力机制和大量的参数实现全局信息的捕获,但这也导致了较高的计算复杂度。
-
应用场景:
- CNN:CNN在图像分类、目标检测和分割等任务中表现出色,特别是在需要提取局部特征和处理低层次视觉信息的任务中。
- Transformer:Transformer在图像分类、语义分割和目标检测等任务中也取得了显著成果,特别是在需要捕捉全局上下文信息和长距离依赖关系的任务中。
多层CNN的特征能否替代Transformer的特征?
多层CNN的特征在某些任务中可以部分替代Transformer的特征,但两者各有优势,完全替代并不现实:
-
局部特征提取:
- 多层CNN能够有效提取图像的局部特征,如边缘、纹理等。这些特征在许多计算机视觉任务中非常重要。然而,多层CNN在捕捉全局上下文信息和长距离依赖关系方面存在局限性。
-
全局信息捕获:
- Transformer通过自注意力机制能够更好地捕捉全局信息和长距离依赖关系,这对于许多任务(如语义分割和目标检测)至关重要。即使多层CNN能够提取丰富的局部特征,但在处理全局信息时仍然不如Transformer有效。
-
计算资源:
- 多层CNN在计算效率上优于Transformer,适合实时处理和资源受限的应用场景。然而,Transformer虽然计算资源需求较高,但在处理复杂任务时能够提供更好的性能。
-
融合策略:
- 为了充分发挥两者的优点,许多研究提出了将CNN和Transformer结合的混合模型。例如,CTHNet结合了CNN和Transformer的优点,既保留了局部特征的细节,又能够捕捉全局信息。类似的,Swin Transformer通过分块和窗口自注意力机制降低了计算复杂度,同时保持了Transformer的优势。
结合使用的优势
- 互补性:CNN擅长提取局部特征,而Transformer擅长捕捉全局上下文信息。将两者结合可以充分利用各自的优势,提高模型的性能。
- 混合模型:例如,TC-Net结合了CNN和Transformer的优点,通过CNN提取局部特征并通过Transformer提取全局特征,从而在皮肤病变分割任务中取得了更好的效果。
- 多模态融合:在多模态任务中,CNN和Transformer可以分别处理不同模态的数据,并通过融合机制整合信息,提高任务的准确性和鲁棒性。
多层CNN和transformer间的替换性
多层卷积神经网络(CNN)在捕捉全局上下文信息和长距离依赖关系方面存在一些局限性,与Transformer相比,这些缺陷主要体现在以下几个方面:
-
局部感受野与全局信息的获取:
- CNN通过逐层卷积操作来提取特征,每个卷积核只能捕获局部区域的信息。尽管可以通过增加卷积层的深度来逐步扩展感受野,但这种扩展是逐步的,且受到卷积核大小的限制。因此,CNN在捕获全局上下文信息方面能力有限,尤其是在处理需要全局理解的任务时。
- Transformer通过自注意力机制(Self-Attention)能够直接计算输入序列中任意两个位置之间的关系,从而实现全局信息的高效捕获。这种机制使得Transformer在处理长距离依赖关系时表现出色。
-
长距离依赖问题:
- CNN在处理长距离依赖关系时面临挑战。由于其局部卷积操作的特性,CNN需要通过多层堆叠来逐步扩展感受野,这不仅增加了计算复杂度,还可能导致梯度消失或梯度爆炸问题。
- Transformer通过自注意力机制解决了这一问题。自注意力机制允许模型在一步内计算所有位置之间的关系,从而有效捕捉长距离依赖关系,避免了RNN和CNN在处理长序列时的梯度消失或爆炸问题。
-
并行化能力:
- CNN的计算过程是顺序的,每一层的输出需要等待前一层的计算完成。这种顺序性限制了CNN的并行化能力,尤其是在处理长序列时,计算效率较低。
- Transformer完全摆脱了CNN和RNN的顺序性限制,其自注意力机制允许模型在一步内并行处理所有输入,大大提高了计算效率。
-
计算复杂度与资源消耗:
- CNN在处理大规模数据集时,尤其是在需要深层网络结构的情况下,计算资源和训练时间消耗较大。此外,更深的CNN可能会引入梯度消失或爆炸问题,进一步增加训练难度。
- Transformer虽然在训练过程中需要大量的数据和计算资源,但其自注意力机制使得模型能够更高效地处理长序列数据,并且在推理阶段具有较高的效率。
-
特征提取与表示能力:
- CNN在特征提取方面表现出色,尤其是在局部特征和边缘检测方面。然而,其对全局特征的捕获能力有限,尤其是在处理需要全局上下文的任务时。
- Transformer通过自注意力机制能够捕捉全局特征,并且能够通过多头注意力机制同时关注多个子空间的特征表示,从而更好地捕捉复杂任务中的全局信息。
多层CNN在捕捉全局上下文信息和长距离依赖关系方面存在局限性,主要体现在局部感受野的限制、长距离依赖问题、并行化能力不足、计算复杂度高以及特征提取能力有限等方面。相比之下,Transformer通过自注意力机制有效解决了这些问题,使其在处理全局信息和长距离依赖关系方面具有显著优势。


















 1491
1491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









