






论文阅读
对于长尾数据,PLM更倾向于死记(rote memorization)下来少数的这几个例子(atypical instances),而不是去学习(learn the common pattern)。
人类可以进行联想学习,以回忆深层记忆中的相关技能,相互加强,从而拥有解决少镜头和零镜头任务的非凡能力。
收到以上思想的启发,本文提出利用检索和关联的方法,提升prompt learning的泛化性,在generalization和memorization之间寻找一个平衡。
做法是从training data里面找一些数据构建一个知识库。
1. 从知识库中检索demonstration,作为in-context augmentation与输入数据相结合。
2. 对输入和知识库使用KNN算法,将KNN的结果视为简单实例和困难实例的区分。此外,本文通过在训练期间分配一个标度,自动地强制模型强调由kNN识别的困难实例。
3. 最后,把KNN算法得到这个label信息结合进最后的prediction的过程中。inference的时候,通过插入非参数化的k近邻的信息,提升分类的性能。
本文的实验是在zero-shot和few-shot的场景下进行的,实验结果证明了所提出的检索机制对于稀缺样本具有更好的泛化性能。
Model
1. Knowledge store construction
将training data的输入改成template的形式,这样representation中就包含了mask,最后的embedding信息用mask token representation表示。把标签转化成相应的word,比如positive、negative。knowledge store是在few shot training data上构造的,而不是所有的training data。这个knowledge store应该是易于编辑的,可以在training过程中异步更新。
为knowledge source构建索引,使用FASSI快速地从大语料库中进行检索,相似度计算方法是MIPS。
还有一个trick就是knowledge encoder的异步更新,更新re-embedding and re-indexing,实验证明可以提升性能。(感觉和NMT caideng的文章好像啊)
Note: 有一个不同点就是他的encoder全部都是需要先把input sentence转化成template的,然后最后的embedding是[MASK]而不是[CLS]。
2. 为了增强PLMs的类别学习能力,提出了neural demonstration,将它跟input embedding cancat从而提升泛化性。对于一个输入,对每一个class都检索m个knowledge里面的demonstration,或者说cached representations。
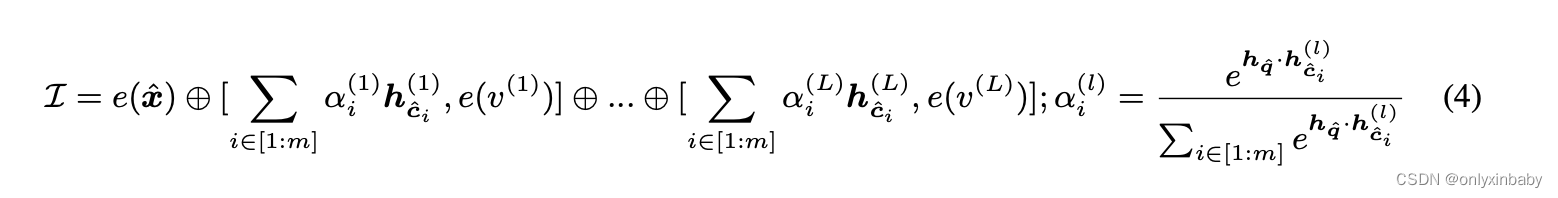
L是指总的分类的类别数,m是指每一个类别检索多少个neighbor。alpha就是过了soft Max的MIPS结果。
neural demonstration相比离散discrete demonstration的好处:
a. 能够容忍的最大输入长度更多,更适合多标签分类。
b. 更加省时间,不需要算cross attention,加快了inference。
c. cloze-style contextual representation更加informative,比BERT的[CLS]表达能力更强,算MIPS的时候也更准确?虽然我不觉得这个会有什么很大的提升,[CLS]不也是句子中的各个token的表示的加权求和吗?
2. retrieve KNN for guiding training
PLM是eager learner,KNN是lazy learner。
可以利用KNN的分类结果当作先验的外部知识去引导PLM的参数学习,尤其是对那些hard sample或者说atypical sample。这个过程可以称为knn-train。
Loss部分没太看懂。
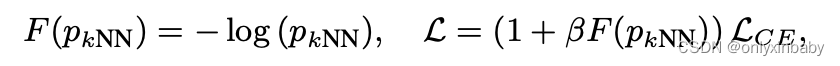
其实就是knn的结果变成概率,取gold label相对应的概率,给原本的cross entropy进行加权。加1是为了保证其他类别的概率不变。
3. knn based probs for cloze-style prediction
只用在test里面,也叫做knn test

Experiment
k way c shot,k类,每类有c个样本数据。














 1185
1185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









