









- We propose a dynamic selection mechanism in CNNs that allows each neuron to adaptively adjust its receptive field size based on multiple scales of input information.
- However, some other RF properties of cortical neurons have not been emphasized in designing CNNs, and one such property is the adaptive changing of RF size.
- All of these experiments suggest that the RF sizes of neurons are not ffixed but modulated by stimulus.
- But that linear aggregation approach may be insufficient to provide neurons powerful adaptation ability. (InceptionNets)
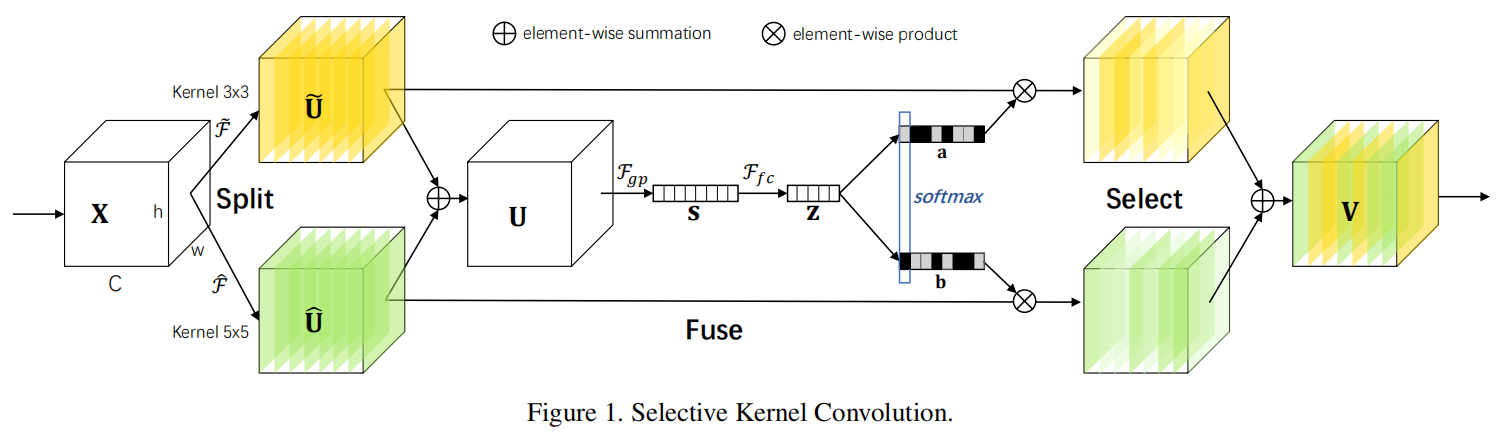
具体步骤(two-branch)
1. Split

输入\(X\)分别经过3×3和5×5的group卷积分别得到\(\widetilde{U}\)和\(\widehat{U}\),论文中提到two branch情况下,5×5的组卷积使用dilation=2的3×3的膨胀卷积替代,下面的代码中还是用的普通5×5卷积。
2. Fuse
(1)通过element-wise summation得到\(U\)
![]()
(2)通过global average pooling embed global information得到\(s\in \mathbb{R}^{C}\),其中s的第c个元素的计算方式如下:

(3)通过fully connected layer得到\(z\in\mathbb{R}^{d\times 1}\)
![]()
其中\(\beta\)是batch normlization,\(\delta \)是ReLU,\(W\in\mathbb{R}^{d\times C}\)。注意这里通过redunction ratio \(r\)和阈值\(L\)两个参数控制\(z\)的输出通道\(d\),论文中\(L\)默认为32。下面的实现代码中没有加BN和ReLU
![]()
3. Select

"A soft attention across channels is used to adaptively select different spatial scales of information",其中\(A,B\in\mathbb{R}^{d\times C}\),\(a,b\)分别表示\(\widetilde{U}\)和\(\widehat{U}\)的soft attention vector,\(A_{c}\in\mathbb{R}^{1\times d}\)是A的第c行,\(a_{c}\)是a的第c个元素,\(B_{c}\)和\(b_{c}\)同样。在两个分支的情况下,矩阵B是多余的,因为\(a_{c}+b_{c}=1\),最终结果特征图V通过下式得到
![]()
其中\(V=[V_{1},V_{2},...,V_{c}],V_{c}\in\mathbb{R}^{H\times W}\)。
具体步骤如下:
a.通过两个不同的fc层(即矩阵A、B)分别得到a和b,这里将通道从d又映射回原始通道数C
b.对a,b对应通道c处的值进行softmax处理
c.\(\widetilde{U}\)和\(\widehat{U}\)分别与softmax处理后的a,b相乘,再相加,得到最终输出V,V和原始输入X的维度保持一致。
个人理解
输入\(X\)分别经过3×3和5×5的group卷积分别得到\(\widetilde{U}\)和\(\widehat{U}\),然后相加得到\(U\),因此\(U\)中既包含了3×3感受野的信息又包含了5×5感受野的信息。然后通过使用全局平局池化编码全局信息生成channel-wise statistics,然后接一层全连接层进一步学习,然后接两个不同的全连接层分别得到\(a\)和\(b\),\(a\)和\(b\)分别编码了3×3感受野和5×5感受野的信息,然后接softmax,这一步可以看作是attention机制,即让网络自己去学习不同视野的信息然后自适应的去融合不同感受野的信息。
在Introduction的最后一段,作者为了验证该方法,在保持图片大小的情况下,增大前景目标,缩小背景,然后发现大多数神经元更多的接收来自大kernel分支的信息。
SK与SE类似的地方在于,都用到了attention机制,SE是自适应的去学习通道间的联系,增强更有用通道的信息,削弱相对没用通道的信息。SK是自适应的去学习不同感受野的联系,对于某些物体更大的感受野会学习到更有用的信息,那么SK就会更多的接收来自大感受野分支的信息。
与Inception不同的地方在于,Inception对不通感受野的信息按相同的比例接收,没有考虑到对于不同的目标不同感受野之间的差异,可能对于某些目标大感受野更有用,对另一些小感受野更有用,SK会自适应的去调整接收不同感受野信息的比例。
注释代码
import torch
import torch.nn as nn
class SKConv(nn.Module):
def __init__(self, features, M, G, r, stride=1, L=32):
""" Constructor
Args:
features: input channel dimensionality.
M: the number of branches.
G: num of convolution groups.
r: the radio for compute d, the length of z.
stride: stride, default 1.
L: the minimum dim of the vector z in paper, default 32.
"""
super(SKConv, self).__init__()
d = max(int(features / r), L)
self.M = M
self.features = features
self.convs = nn.ModuleList([])
for i in range(M):
self.convs.append(nn.Sequential(
nn.Conv2d(features, features, kernel_size=3 + i * 2, stride=stride, padding=1 + i, groups=G),
nn.BatchNorm2d(features),
nn.ReLU(inplace=False)
))
self.fc = nn.Linear(features, d)
self.fcs = nn.ModuleList([])
for i in range(M):
self.fcs.append(
nn.Linear(d, features)
)
self.softmax = nn.Softmax(dim=1)
def forward(self, x): # (batch_size, channel, height, width), channel==features
# 1. Split
for i, conv in enumerate(self.convs):
fea = conv(x).unsqueeze_(dim=1) # (b, 1, c, h, w)
if i == 0:
feas = fea
else:
feas = torch.cat([feas, fea], dim=1) # (b, 2, c, h, w)
# 2. Fuse
fea_U = torch.sum(feas, dim=1) # (b, c, h, w) element-wise summation
fea_s = fea_U.mean(-1).mean(-1) # (b, c) global average pooling
fea_z = self.fc(fea_s) # (b, c/r)
# 3. Select
for i, fc in enumerate(self.fcs):
vector = fc(fea_z).unsqueeze_(dim=1) # (b, 1, c)
if i == 0:
attention_vectors = vector
else:
attention_vectors = torch.cat([attention_vectors, vector], dim=1) # (b, 2, c)
attention_vectors = self.softmax(attention_vectors) # (b, 2, c)
attention_vectors = attention_vectors.unsqueeze(-1).unsqueeze(-1) # (b, 2, c, 1, 1)
fea_v = (feas * attention_vectors).sum(dim=1) # (b, c, h, w)
return fea_v
该代码与论文的两处不同
- 论文中提到5×5卷积用dilation=2的3×3膨胀卷积代替,但该实现中还是用的普通5×5卷积
- 在global avg pooling后面的fc层中,论文中有BN和ReLU,但该实现中没有
















 716
716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











