




 SKNet是一种轻量级卷积神经网络,它引入了Selective Kernel Convolution,允许神经元根据输入信息的尺度自适应调整感受野大小。通过Split、Fuse和Select操作,SKNet能动态聚合不同卷积核的信息,实现更高效和灵活的特征提取。在ImageNet和CIFAR基准测试中,SKNet在低模型复杂度下表现出优越性能。
SKNet是一种轻量级卷积神经网络,它引入了Selective Kernel Convolution,允许神经元根据输入信息的尺度自适应调整感受野大小。通过Split、Fuse和Select操作,SKNet能动态聚合不同卷积核的信息,实现更高效和灵活的特征提取。在ImageNet和CIFAR基准测试中,SKNet在低模型复杂度下表现出优越性能。
Selective Kernel Networks
论文:https://arxiv.org/abs/1903.06586
代码:https://github.com/implus/SKNet
摘要
在标准卷积神经网络(CNN)中,每层中人工神经元的感受野被设计成共享相同的大小。在神经科学界众所周知,视觉皮层神经元的感受野大小受到刺激的调节,这在构建CNN时很少被考虑。我们在CNN中提出了一种动态选择机制,允许每个神经元根据输入信息的多个尺度自适应地调整其感受野大小。设计了一个名为Selective Kernel(SK)单元的构建块,其中使用由这些分支中的信息引导的softmax attention来融合具有不同卷积核大小的多个分支。对这些分支的不同关注产生了融合层中神经元的有效感受野的不同大小。多个SK单元被堆叠到称为Selective Kernel(SKNets)的深度网络中。在ImageNet和CIFAR基准测试中,我们凭经验证明SKNet在模型复杂度较低的情况下优于现有的最先进架构。详细分析表明,SKNet中的神经元可以捕获具有不同尺度的目标物体,从而验证神经元根据输入自适应地调整其感受野尺寸的能力。
1. Introduction
在本文中,我们提出了一种非线性方法来聚合来自多个卷积核的信息,以实现神经元的自适应感受野大小。我们引入了一个“选择性卷积核”(SK)卷积,它由三个操作组成:split,fuse和select。split操作生成具有各种卷积核大小(对应于神经元的不同感受野大小)的多个路径。融合操作组合并聚合来自多个路径的信息,以获得选择性权重的全局和综合表示。select操作根据选择权重聚合不同大小的卷积核的特征映射。
SK卷积可以是计算上轻量级的,并且仅是参数和计算成本的轻微增加。为了证明它们的一般适用性,我们还在较小的数据集CIFAR-10和100上提供了引人注目的结果,并成功地将SK嵌入到小模型中(例如,ShuffleNetV2)。
为了验证所提出的模型是否具有调整神经元感受野尺寸的能力,我们通过在自然图像中放大目标对象并缩小背景以保持图像大小不变来模拟刺激。发现当目标对象变得越来越大时,大多数神经元越来越多地从更大的卷积核路径收集信息。这些结果表明,所提出的SKNet中的神经元可以自适应感受野尺寸,这可能是该模型在物体识别中的优越性能的基础。
2 相关工作
Multi-branch convolutional networks :注意,提出的SKNets遵循InceptionNets的概念,包含多个分支的各种卷积核,但至少有两个重要方面不同:1)SKNets的方案更简单,没有大量的定制设计; 2)多个分支的自适应选择机制用于实现神经元的自适应感受野大小。
基于交错的分组卷积:例如IGCV1 ,IGCV2和IGCV3。卷积的特殊情况是depthwise convolution,其中组的数量等于通道的数量。Xception 和MobileNetV1 引入了深度可分离卷积,它将普通卷积分解为深度卷积和逐点卷积。深度卷积的有效性在随后的工作中得到验证,如MobileNetV2 和ShuffleNet。除了分组/深度卷积之外,扩张的卷积支持感受野的指数扩展而不会损失覆盖范围。例如,具有扩张2的3×3卷积可以近似覆盖5×5滤波器的RF,同时消耗不到一半的计算和存储器。在SK卷积中,较大尺寸(例如,> 1)的卷积核被设计成结合分组/深度/扩张的卷积,以避免繁重的开销。
注意力机制:SENet 带来了一种有效的,轻量级的门机制,可以通过channel-wise的重要性自校准特征图。相比之下,我们提出的SKNets是第一个通过引入注意机制明确地关注神经元的自适应感受野大小。
3方法
3.1. Selective Kernel Convolution
为了使神经元能够自适应地调整其感受野尺寸,我们在具有不同卷积核大小的多个卷积核中提出了自动选择操作SK卷积。具体来说,我们通过三个操作实现SK卷积 - Split,Fuse和Select,如图1所示,其中显示了一个双分支的情况。因此,在此示例中,只有两个卷积核具有不同的卷积核大小,但很容易扩展到多个分支的情况。
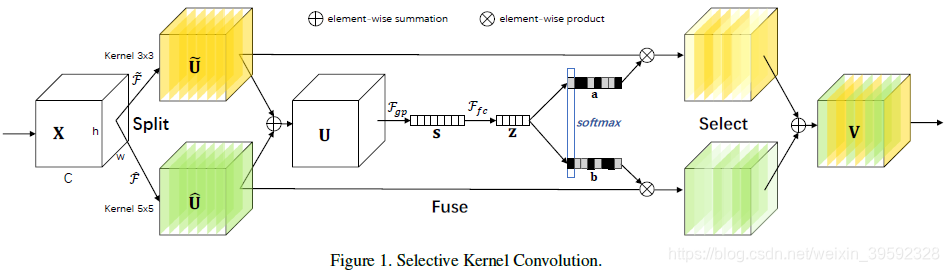
Split:对于任何给定的特征映射 X ∈ R H ′ × W ′ × C ′ X \in {
{\rm{R}}^{H' \times W' \times C'}} X∈RH′×W′×C′,默认情况下,我们首先分别进行卷积大小为3和5的两个转换 F ∼ : X → U ∼ ∈ R H × W × C \mathop F\limits^ \sim :X \to \mathop U\limits^ \sim \in {
{\rm{R}}^{H \times W \times C}} F∼:X→U∼∈RH×W×C和 F ^ : X → U ^ ∈ R H × W × C \hat F:X \to \hat U \in {
{\rm{R}}^{H \times W \times C}} F^:X→U^∈RH×W×C。请注意,$\mathop F\limits^ \sim 和 和 和\hat F$均由高效的分组/深度卷积,批量标准化和ReLU函数组成。为了进一步提高效率,5×5卷积核的常规卷积被替换为3×3卷积核和扩张尺寸为2的扩散卷积。
Fuse: 基本思想是使用门来控制来自多个分支的信息流,这些分支携带不同尺度的信息到下一层的神经元中。为实现这一目标,门需要整合来自所有分支的信息。我们首先通过element-wise summation融合来自多个(图1中的两个)分支的结果:
U = U ~ + U ^ U = \tilde U + \hat U U=U~+
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1477
1477




 到【灌水乐园】发言
到【灌水乐园】发言







