







paper:A Dual Weighting Label Assignment Scheme for Object Detection
official implementation:https://github.com/strongwolf/dw
存在的问题
标签分配的目的是给每个训练样本分配一个正的和一个负的loss权重。现有的方法大都只关注正权重函数的设计,而负权重直接根据正权重得到。这种机制限制了模型的检测能力。
本文的创新点
本文探索了一种新的加权范式,称为双加权dual weighting(DW)来分别定义正权重和负权重。作者首先通过分析目标检测中的评价指标,确定正/负权重的关键影响因素,然后在这基础上设计正/负权重。具体来说,一个样本的正权重由其分类和定位得分之间的一致性确定,而负权重被分解为两项:样本作为负样本的概率和重要性。这种加权策略为区分重要样本和不重要样本提供了更大的灵活性,从而得到一个更有效的检测模型。
前言
现有的方法主要集中于正权重函数的设计,而负权重直接根据正权重推导得到,由于负权重提供的新监督信息很少,可能会限制检测模型的学习能力。作者认为这种耦合的加权机制不能在更精细的水平上区分每个训练样本。图1展示的是四个不同预测结果的anchor,但是GFL和VFL分配了几乎一样的正负权重给B,D和C,D,同时GFL分配给A.C的正负权重都为0,因为它们的分类得分和IoU相等。由于在现有的soft标签分配方法中,负权重与正权重高度相关,具有不同属性的anchor有时会被分配几乎相同的正、负权重,这可能会影响模型的有效性。
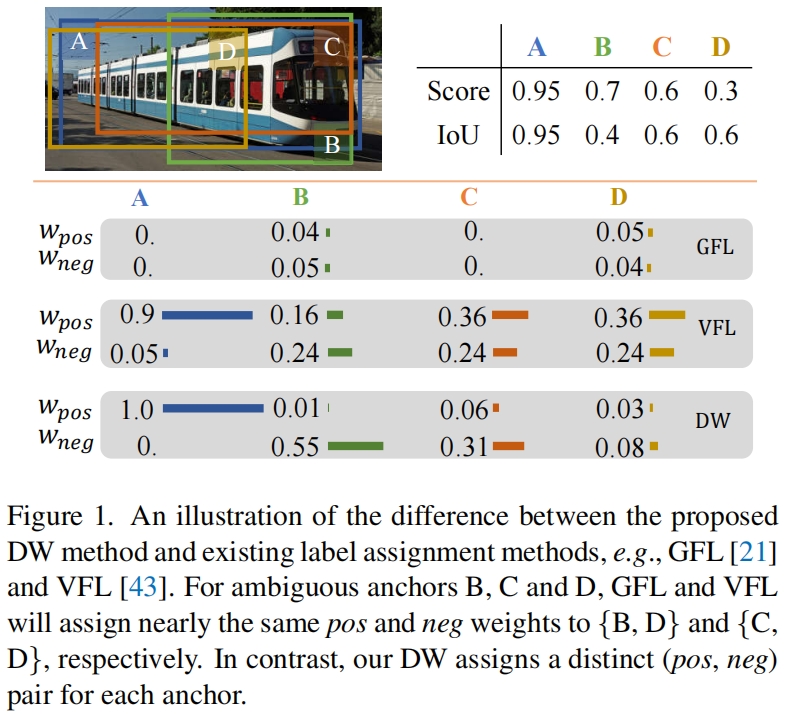
为了给模型提供更有区分度的监督信号,本文提出了一种新的双加权标签分配方法,从不同的角度指定正、负权重,并且它们是互补的关系。具体来说,正权重是由分类得分和回归得分的组合动态确定的,而每个anchor的负权重分为两个部分:一个样本是负样本的概率和它作为负样本时的重要性。正权重反映了cls head和reg head之间的一致性程度,它将一致性程度高的anchor推到anchor list的前列。而负权重反映的是不一致的程度,它将不一致的anchor推到anchor list的尾部。这样在推理时,具有更高分类得分和更准确位置的bounding box将有更大的可能在NMS后保存下来,而那些位置不准确的边界框将会被过滤掉。如图1所示,DW通过分配不同的正负权重来区分四个不同的anchor,从而为模型提供了更细粒度的监督信号。
方法介绍
Motivation and Framework
为了和NMS兼容,一个好的检测器应该能够预测一致性高的bounding box,它既具有高的分类得分又有精确的位置。但是如果所有样本都被同等对待,将导致两个检测头之间的misalignment:分类得分最高的检测框通常不是用于回归的最佳检测位置。这种不对齐会降低模型的性能,尤其是在高IoU指标下。软标签分配通过一种soft的方式加权损失旨在增强分类头和回归头之间的一致性,soft LA下一个anchor的损失可以表示如下
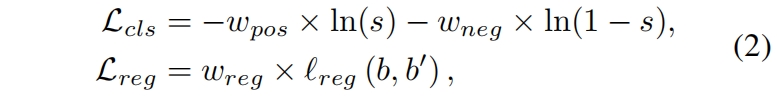
其中 \(s\) 是预测的分类得分,\(b,b'\) 分别是预测的bounding box和GT标签,\(\ell_{reg}\) 是回归损失如Smooth L1 Loss、IoU Loss或GIoU Loss。可以通过给一致性高的anchor分配较大的 \(w_{pos}\) 和 \(w_{neg}\) 来减轻两个检测头之间的不一致问题。这样这些训练好的anchor在推理时就能同时预测得到高的分类得分和准确的位置。
现有的方法大多设置 \(w_{neg}\) 等于 \(w_{pos}\) 并主要关注于如何定义一致性并将其融入到损失函数中。表1总结最近一些代表方法中 \(w_{pos}\) 和 \(w_{neg}\) 的公式
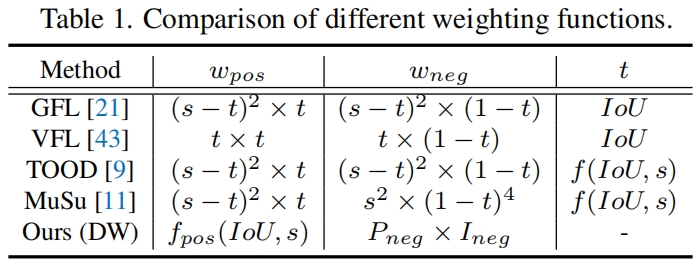
可以看出现有方法大都设计了一个指标 \(t\) 来表示两个检测头之间的一致程度,然后设置不一致程度为 \(1-t\)。 然后将两者融入到损失函数正负项的权重中。
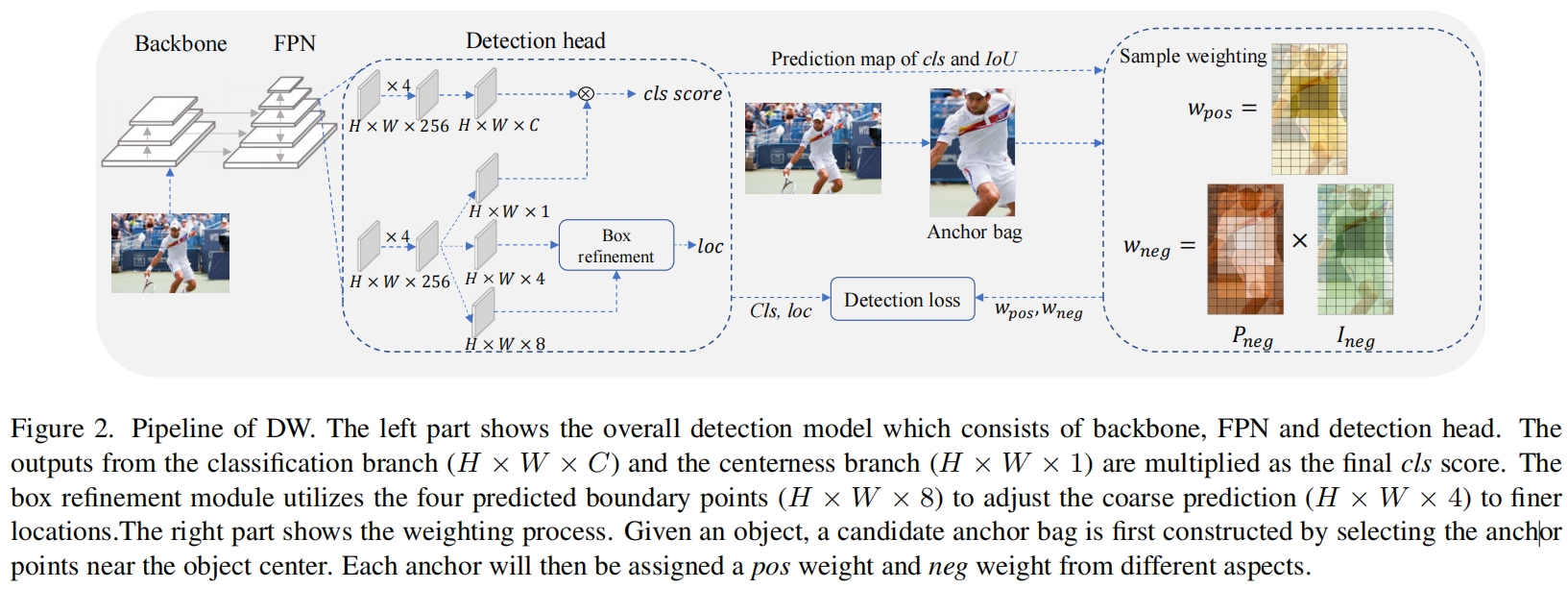
DW的完整pipeline如图2所示,首先选择每个GT中心附近区域的anchor(center prior)作为正样本的候选,这个区域之外的anchor定义为负样本并且不会参与加权函数的计算中,候选中的anchor会分配三个权重 \(w_{pos},w_{neg},w_{reg}\) 从而更有效的监督训练过程。
Positive Weighting Function
通过分析目标检测的评价指标,我们知道一个预测被定义为正确的只有当且仅当满足下述条件时
- 预测bounding box和它最近的GT的IoU大于设定阈值 \(\theta \)
- 没有其它box满足条件1且排在当前box的前面
因此高的ranking得分和高的IoU是一个pos预测的充分必要条件,正权重 \(w_{pos}\) 应该和IoU以及排序得分都呈正相关,因此作者定义了一个一致性评价指标 \(t\) 如下
![]()
其中 \(\beta\) 是平衡系数。为了增大不同anchor之间正权重的方差作者添加了一个指数调制因子
![]()
其中 \(\mu\) 是超参用来控制不同正权重的relative gap。最后每个anchor的正权重通过候选集中所有pos weight的和进行归一化。
Negative Weighting Function
Probability of being a Negative Sample. 根据COCO的评价指标来看,只要IoU小于 \(\theta\) 就说明是一个错误的预测了,不管分类得分有多高。由于COCO采用IoU 0.5~0.95的区间来计算AP,因此负样本概率 \(P_{neg}\) 应该满足下式
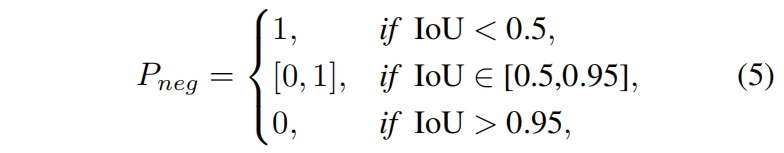
在区间[0.5, 0.95]内定义的任何单调递减函数都可以用来定义 \(P_{neg}\),为了简便定义如下
![]()
Importance Conditioned on being a Negative Sample. 在推理时,ranking list中的一个neg预测不会影响召回但会影响精度,因此负样本应该尽可能的靠后。但得分更高的neg预测应该比得分更低的更加重要因为它们对模型来说更难学习属于困难样本,因此neg样本的重要性 \(I_{neg}\) 应该是排名分数的函数,为了简便定义如下
![]()
最后,负权重 \(w_{neg}=P_{neg}\times I_{neg}\) 定义如下
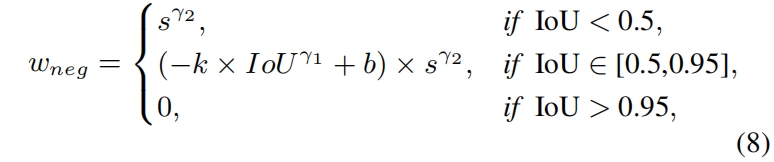
可以看出对于两个pos权重相同的anchor,IoU较小的neg权重更大,从而更好的区分它们,如图1所示。
Box refinement
由于正负权重的输入都包含IoU,更准确的IoU能得到更高质量的样本,有利于学习更强的特征。因此本文基于预测偏移 \(O\in R^{H\times W\times 4}\) 提出了一个box refinement操作,其中 \(O(j,i)=\left \{ \Delta l,\Delta t, \Delta r, \Delta b \right \} \) 表示当前anchor中心点到预测框左、上、右、下四边的距离,如图4所示。

由于靠近物体边界的点更优可能预测准确的位置,因此作者设计一个可学习的预测模块基于coarse bounding box为每条边生成一个边界点,边界点的定义如下
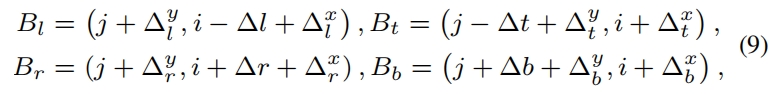
其中 \(\left\{\Delta_l^x, \Delta_l^y, \Delta_t^x, \Delta_t^y, \Delta_r^x, \Delta_r^y, \Delta_b^x, \Delta_b \right \} \) 是refine模块的输出。细化后的offset map \(O'\) 更新如下
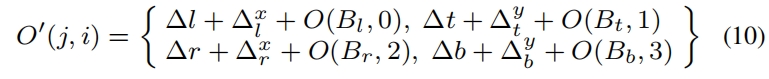
Loss Function
完整损失函数定义如下,其中分类得分是cls分支与centerness分支预测的乘积
![]()
其中 \(\beta\) 是平衡系数
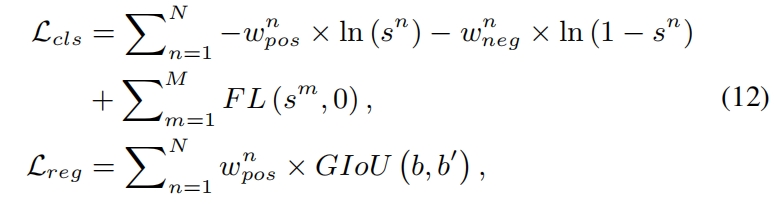
其中 \(N,M\) 分别是候选集内和候选集外的anchor数量。
代码解析
超参 \(\gamma_{1}=\gamma_{2}=2\),\(\beta=\mu=5\)
- 图4有问题,中心点坐标应该是 (j, i),即(y, x)的顺序。https://github.com/strongwolf/DW/issues/24
- box refine代码没看懂
if self.with_reg_refine: # True reg_dist = bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4) # (2,4,136,100)->(2,136,100,4)->(27200,4) points = self.prior_generator.single_level_grid_priors((h, w), self.strides.index(stride), dtype=x.dtype, device=x.device) # (13600,2) points = points.repeat(b, 1) # (27200,2) decoded_bbox_preds = distance2bbox(points, reg_dist).reshape(b, h, w, 4).permute(0, 3, 1, 2) # (27200,4)->(2,136,100,4)->(2,4,136,100), (x1,y1,x2,y2) reg_offset = self.reg_offset(reg_feat) # (2,8,136,100), left,top,right,bottom的顺序和bbox_pred一致,每个点的坐标是(y,x) bbox_pred_d = bbox_pred / stride reg_offset = torch.stack([reg_offset[:, 0], reg_offset[:, 1] - bbox_pred_d[:, 0], reg_offset[:, 2] - bbox_pred_d[:, 1], reg_offset[:, 3], reg_offset[:, 4], reg_offset[:, 5] + bbox_pred_d[:, 2], reg_offset[:, 6] + bbox_pred_d[:, 3], reg_offset[:, 7]], 1) # (2,8,136,100) bbox_pred = self.deform_sampling(decoded_bbox_preds.contiguous(), reg_offset.contiguous()) bbox_pred = F.relu(bbox2distance(points, bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)).reshape(b, h, w, 4).permute(0, 3, 1, 2).contiguous()) def deform_sampling(self, feat, offset): # (2,4,136,100),(2,8,136,100) b, c, h, w = feat.shape weight = feat.new_ones(c, 1, 1, 1) # (4,1,1,1) y = deform_conv2d(feat, offset, weight, 1, 0, 1, c, c) # (2,4,136,100) return y函数deform_samplilng的输入是原图上的coarse box (x1, y1, x2, y2),以及在特征图上的式(9)去掉了其中的中心点坐标 (j, i)。通过可变形卷积是怎么直接得到调整后的新 (x1, y1, x2, y2)的?
-
p_loc = torch.exp(-reg_loss*5)是式(3)中的 \(IoU^{\beta}\),只不过其中的IoU变成了GIoU-1 https://github.com/strongwolf/DW/issues/36
- p_pos是式(3)中的t
- 式(4)求pos weight归一化时指数分子取5分母取3的解释https://github.com/strongwolf/DW/issues/3
https://github.com/strongwolf/DW/issues/3p_pos_weight = (torch.exp(5*p_pos) * p_pos * center_prior_weights) / (torch.exp(3*p_pos) * p_pos * center_prior_weights).sum(0, keepdim=True).clamp(min=EPS) - 关于式(10)的解释https://github.com/strongwolf/DW/issues/7
-
式(6)求 \(k,b\) 带入的是(0.5, 1)和(1, 0)而不是(0.95, 0),https://github.com/strongwolf/DW/issues/25,求得k=b=4/3
alpha = 2 t = lambda x: 1/(0.5**alpha-1)*x**alpha - 1/(0.5**alpha-1) # 式(6) - 本文和AutoAssign的区别,https://github.com/strongwolf/DW/issues/33,后者的介绍AutoAssign: Differentiable Label Assignment for Dense Object Detection_autoassign论文下载-CSDN博客


















 1844
1844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











