







论文标题:YOLOv10:Real-Time End-to-End Object Detection
论文作者源码:Github | YOLOv10
YOLOv9还没出来多久,清华团队的YOLOv10算法就已经出来,而且在速度和精度上都赶超v8和v9,下面我们一起看看YOLOv10算法

一、文章摘要
背景和动机:YOLOs系列架构中,依赖非最大值抑制(NMS)进行后处理阻碍了YOLO的端到端部署,这对推理延迟产生不利影响。此外,YOLOs模型中各组分的设计缺乏全面、彻底思考,导致计算冗余明显,由此产生的受约束的模型能力也导致了较差的性能。
作者的方法和思想:提出一种consistent dual assignment 策略,解决后处理中冗余预测的问题,它同时带来了具有竞争力的性能和低推理延迟;其次,引入了基于效率-精度驱动的整体模型设计策略,从效率和精度两个角度对YOLOs的各个组成部分进行了全面优化,大大降低了计算开销,提升了性能。
实验结果:大量的实验表明,YOLOv10在各种模型尺度上都达到了最先进的性能和效率。例如,YOLOv10-S在COCO上类似的AP下比RT-DETR-R18快1.8倍,同时参数数量和FLOPs减少2.8倍。与YOLOv9-C相比,在相同性能下,YOLOv10-B的延迟减少了46%,参数减少了25%
二、方法论和思想
2.1 Consistent Dual Assignments for NMS-free Training
在训练过程中,YOLOs架构通常利用TAL(Task Alignment Learning)为每个实例分配多个正样本。但是,YOLOs需要依赖NMS的后处理,导致部署的推理效率不够理想。虽然以前的研究探索一对一匹配来抑制冗余预测,但它们通常会引入额外的推理开销或产生次优性能。因此,作者引入Dual label assignments 和 Consistent matching metric来解决上述问题。
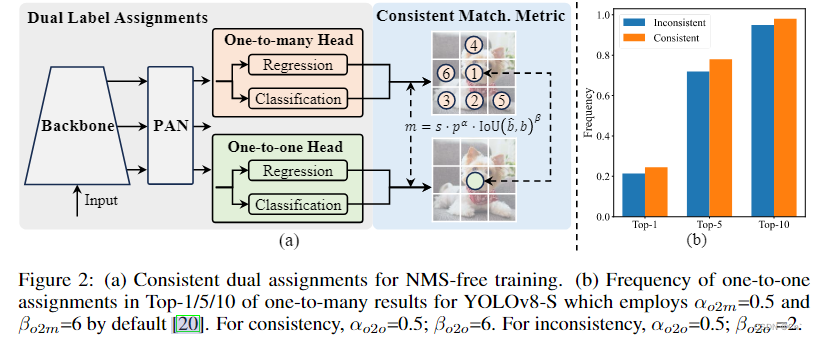
双重标签匹配 Dual label assignments
与一对多分配不同,一对一匹配只为每个基本事实分配一个预测,避免了 NMS 后处理。然而,它导致了弱监督,这导致了次优的准确性和收敛速度。因此,作者引入双重标签分配(dual label assignments )策略,以结合这两种策略的优点。
作者为YOLOs引入一对一头部,它保留了一对多头部的相同结构,并采用与原始一对多分支相同的优化目标,但利用一对一匹配来获得标签分配。在训练期间,两个头部与模型联合优化。
在推理过程中,作者丢弃一对多的头部并利用一对一的头部进行预测。 这使得 YOLO 能够用于端到端部署,而不会产生任何额外的推理成本。此外,在一对一匹配中,我们采用top_1选择方法,实现了与匈牙利匹配相同的性能,训练时间更少。
一致匹配度量 Consistent matching metric
在标签分配过程中,一对一和一对多方法都采用一种度量来定量评估预测与实例之间的一致性水平。为了实现两个分支的预测感知匹配,作者采用了一个统一的匹配度量:
m ( α , β ) = s ⋅ p α ⋅ I o U ( b ^ , b ) β m(α, β) = s·p^α ·IoU(\widehat{b}, b)^β m(α,β)=s⋅pα⋅IoU(b
,b)β
其中 p p p为分类得分, b b b和 b ^ \widehat{b} b 为表示预测和实例的边界框, s s s表示空间先验,指示预测的锚点是否在实例内。 α α α和 β β β是平衡语义预测任务和位置回归任务影响的两个重要超参数。作者将一对一和一对多指标记为 m o 2 o = m ( α o 2 o , β o 2 o ) m_{o2o}=m(α_{o2o}, β_{o2o}) mo2o=m(αo2o,βo2o)和 m o 2 m =
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 405
405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









