










目录
这个笔记算是之前搅拌摩擦焊有限元仿真学习笔记的后续,但是内容主要不是有限元分析相关,所以就没有放在一个系列里
❤ 2023.4.30 ❤
本来我是打算用comsol来实现联合仿真的,毕竟那个软件是原生支持联合仿真的,但是考虑到截止至目前,我的精力都放在了abaqus上,虽然abaqus没有从底层支持matlab的联合仿真,但是有大神开发出了通过python脚本来实现实时的数据交换,所以我就来学习一下。
还是挺着急的!
我的资料:
○ 文章中【我的联合仿真】部分的一些文件和脚本可以在我的github里下载
○ 文章中介绍的方法在这篇论文中也有所体现,欢迎大家引用嘿嘿(虽然赶时间投了个开源期刊。。。)
《Digital Twin Virtual Welding Approach of Robotic Friction Stir Welding Based on Co-simulation of FEA Model and Robotic Model》
参考资料:
关于Abaqus与matlab联合仿真的资料我能找到的非常少,以至于我最开始放弃了用abaqus来实现联合仿真的想法。但是abaqus对于实现搅拌摩擦焊的仿真却支持的很好,于是一直在用abaqus来做有限元分析。
还好我找到了两篇关于abaqus和matlab联合仿真的文章,对我很有参考价值。
这虽然是两篇文章,但其实第二篇是在第一篇基础上的应用,主要的内容还是来自于第一篇。
说实话,当时看到这两篇文章之后,我就和老师夸下海口能实现我的设想,但是现在仔细研读之后,觉得我还是太乐观了。。。
首先现在能确定的是abaqus确实是可以通过matlab来调用,可以通过matlab来对仿真参数进行修改,然后可以读取仿真结果文件,但是不知道能不能实现我想要的对仿真过程的实时干预。
算了,不管行不行,海口是夸下了,总得尝试一下。
※ 仿真案例1——Abaqus与MATLAB联合仿真参数优化
这个案例是我在Youtube上面找资料的时候看到的,虽然也有人把他搬运到b站,但是油管上面提供了这个案例相关的脚本文件。所以我就把油管的链接附上了
→→→【Abaqus parameter Optimization from Matlab】
这个视频都是英语,而且没有字幕(好像歪果仁的视频都不喜欢加字幕。。。),而且这个口音。。。嗯。。。反正看了一遍不是很懂,所以打算照着做一遍
△ 案例概述
其实听的不是很懂,但是大概意思是优化模型中的杨氏模量(E)这个参数,使案例中的这个狗骨头模型在600N的拉力下变形量恰好为30mm,大概是这个意思吧。。。
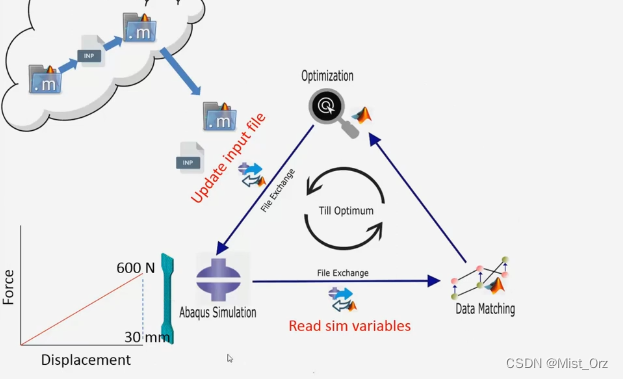
在循环的起始,先给杨氏模量一个随机的数值,然后把这个数值传输给inp文件,然后运行abaqus进行仿真,仿真结束后,运行matlab脚本读取结果文件,然后将仿真结果与预期结果进行比较,根据比较的结果,对杨氏模量的预设值进行优化,再将优化后的结果写入inp文件再次进行仿真。重复这个过程,直到得到预期的杨氏模量数值。
作者给出了如下几个文件
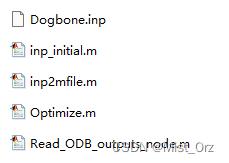
同时作者说可以用自己的inp文件,替换他给出的这个inp文件的。
△ 脚本解读
○ Dogbone.inp
这个是abaqus生成的input文件,是一个文本文件,作者没有给模型和建模用的python脚本,所以我直接运行一下这个文件试试
结果如图

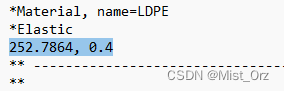
然后有两个例程输出,分别是位移和受力(也就是说这个仿真并不是一端固定给另一端施加力,而是一端固定一端施加确定的位移然后读取固定端的支反力)
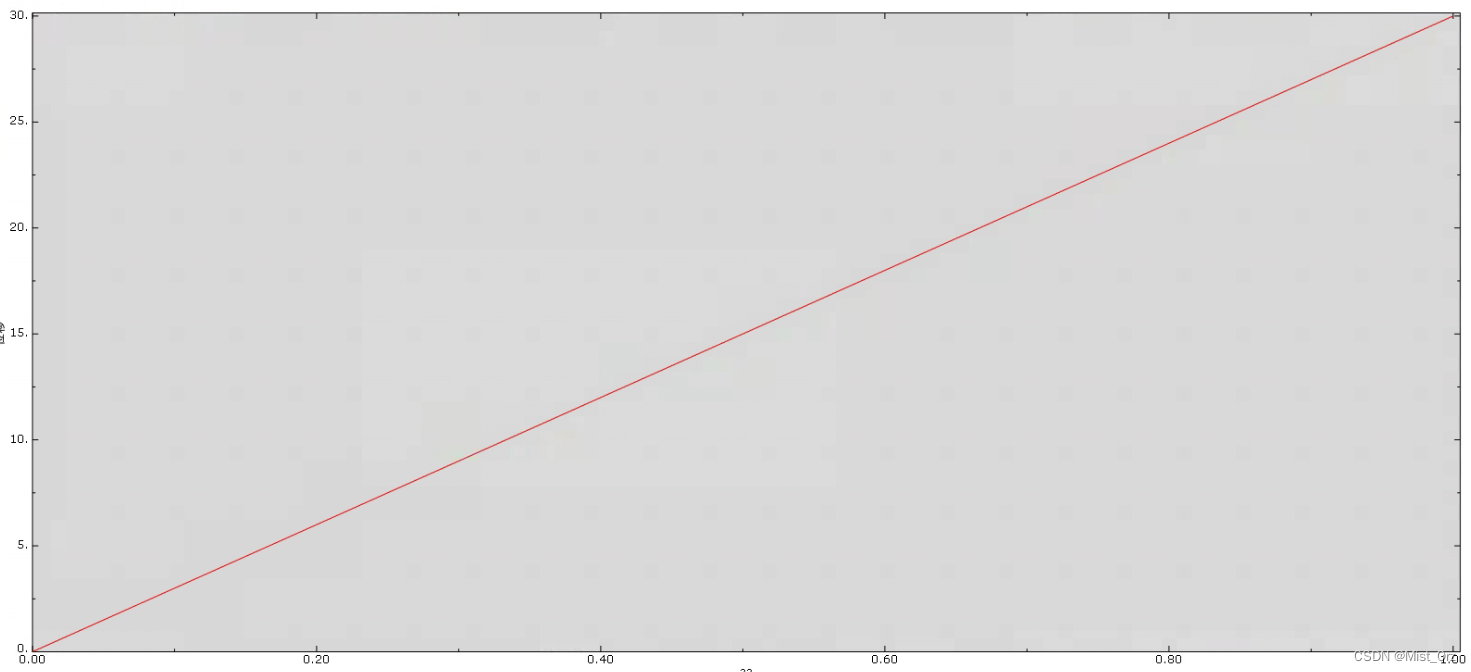
用记事本打开,整个过程优化的就是这一行
○ inp2mfile.m
这个文件是将abaqus的inp文件转化为matlab的m文件的脚本。
使用过程中需要注意

11行:将本行中的“E”替换为需要优化的变量
12、15行:将“Dogbone.inp”替换为自己的inp文件的名字
运行这个脚本,会读取对应的inp文件,并生成“inp_initial.m”的脚本文件
○ inp_initial.m
这个文件是运行上面的脚本生成的脚本文件,里面相当于把对应的inp文件复制了一遍
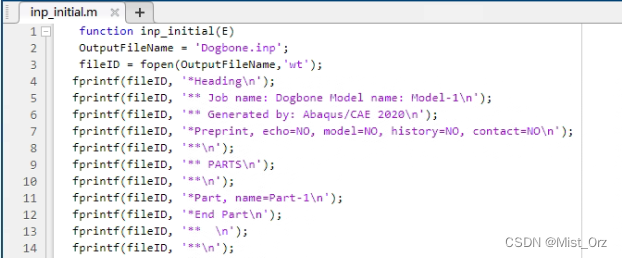
第一行的“E”即为需要优化的变量

找到对应的杨氏模量配置语句,修改为占位符

○ Read_ODB_outputs_node.m
顾名思义,这个脚本的作用是读取ODB文件中的历程输出变量,这个脚本的详细介绍在作者的另一个视频,也就是下面介绍的案例中。
○ Optimize.m
这个脚本是调用其他脚本以及执行优化任务的核心代码。
核心部分是这个(作者说的):

关于这段代码的意思。。。chatgpt这样说。。。

emmmm。。。好像明白又好像不太明白
△ 运行及结果
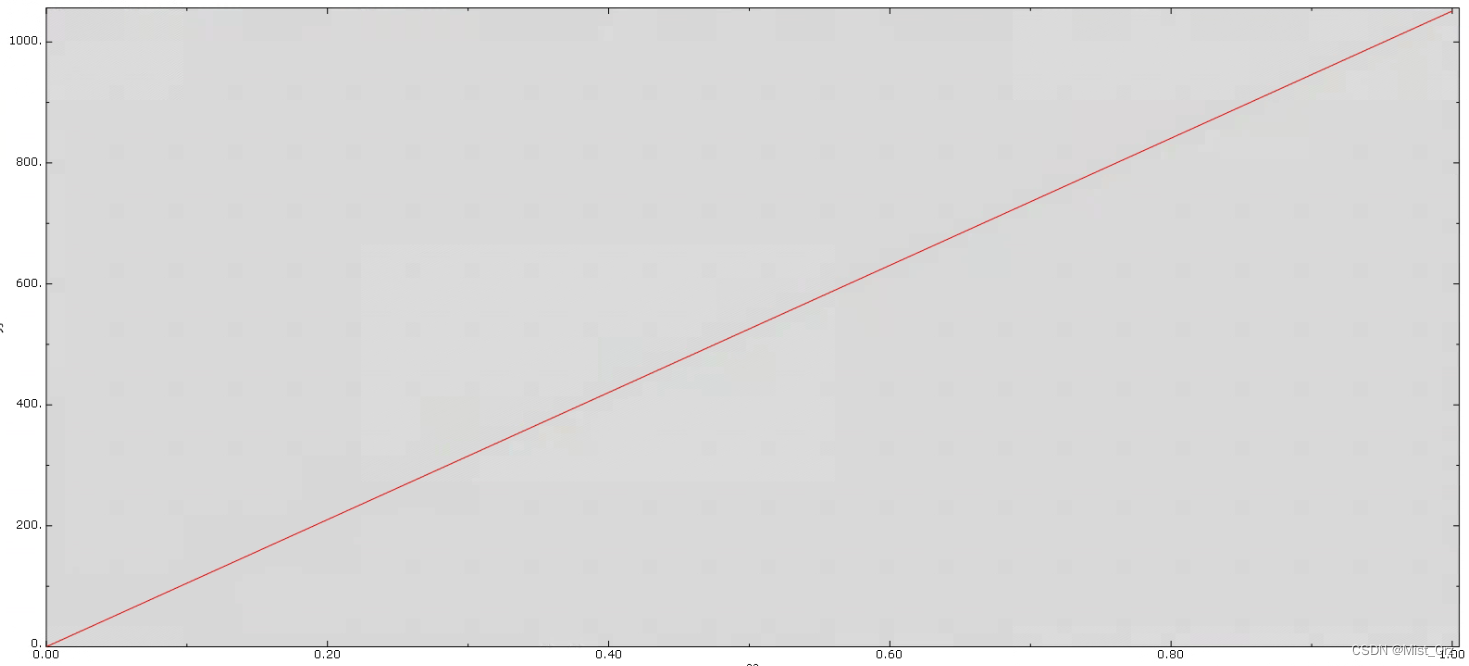
运行了7次之后,程序得出了结果

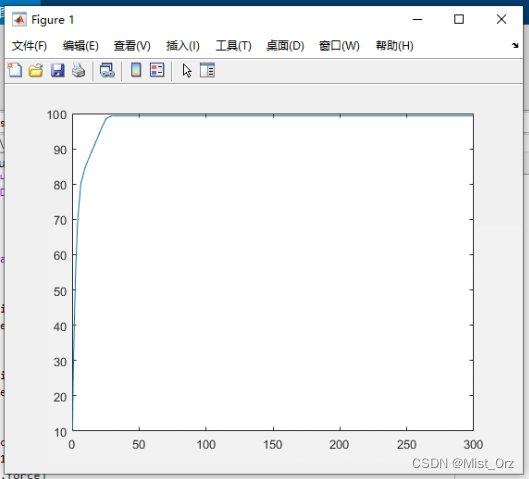
这个是最终的受力曲线
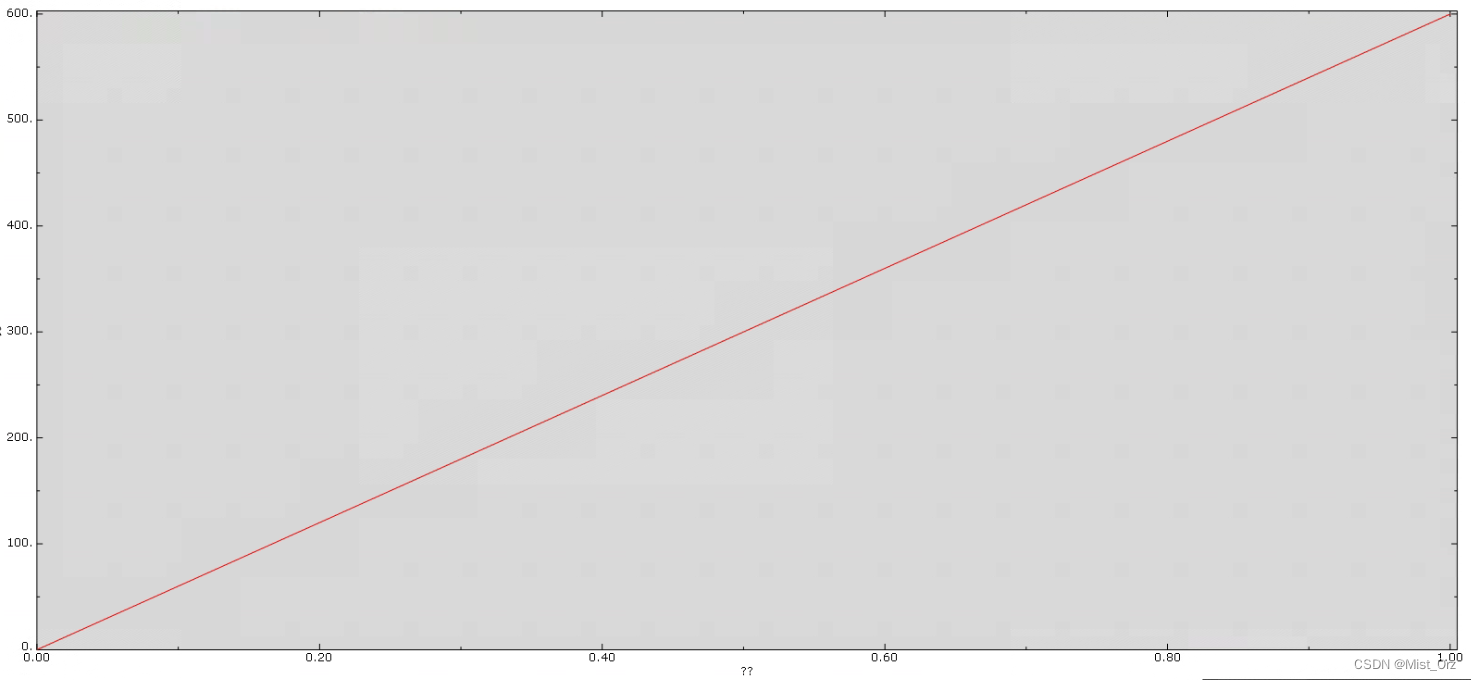
还挺神奇的。。。
※ 仿真案例2——使用MATLAB从Abaqus仿真结果中读取数据
这个案例是油管作者的另一个视频,是上一个案例的补充
→→→【Read Abaqus results from Matlab】
作者同样在视频下方提供了脚本的下载链接
△ 案例概述
脚本如下图

模型如下
△ 脚本解读
○ Dogbone.inp
这个是和上一个案例一样的abaqus的输入文件
但是要注意,使用abaqus生成inp文件之后要对它进行编辑(上个案例并没有说(好像是))
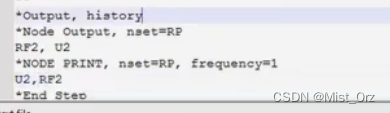
〇 打开inp文件,翻到最后一行

〇 在“* End Step”前面加上需要输出的量

如果需要输出RP这个节点集的位移和受力,则像这样
○ Run_job_request_outputs.m
顾名思义,这个脚本的作用是提交inp文件,然后调用“Read_ODB_outputs_node()”函数读取结果文件中的位移和受力数据,并绘制曲线
○ Read_ODB_outputs_node.m
读取dat文件中的历程变量输出数据。
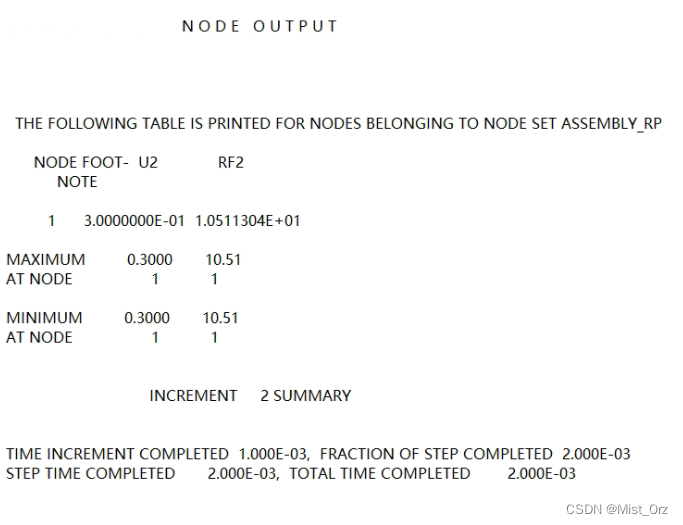
· .dat文件
在设置了历程变量输出后,每个增量步会在dat文件中增加一段这个,里面记录了当前时间点该历程变量的数值
通过编辑这个文件可以实现读取dat文件中不同数据的功能,具体编辑的方法作者在视频里说的还挺详细的,当然前提是需要在inp文件中设定了相应数据的输出。
○ Read_ODB_outputs_ele.m
和上面的脚本作用相似,只是读取的是单元的数据
把上面脚本中的“N O D E O U T P U T”替换为了“E L E M E N T O U T P U T”


读取的是dat文件中这部分数据

❤ 2023.5.8
下面开始我的联合仿真实验
我的联合仿真1——自动提交仿真工程并读取历程输出
首先建立一个仿真模型,然后通过matlab修改模型中的部件的运动速度,再读取结果文件得到部件的位置与角度。
△ 建立仿真模型
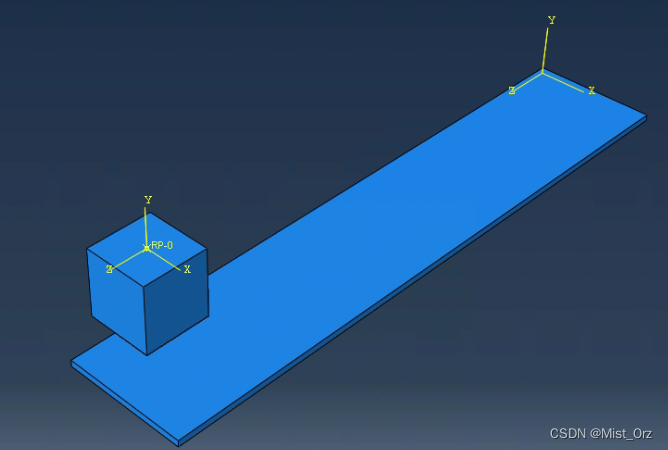
○ 模型及装配
建立一个底板作为位置参照
建立一个立方体作为运动的主体,并在立方体上建立了参考点以及参考坐标系
○ 材料属性
为了贴近仿真实际,这里虽然预计没有相互作用,但是还是给模型赋予材料属性吧
就用之前的steel吧
○ 分析步
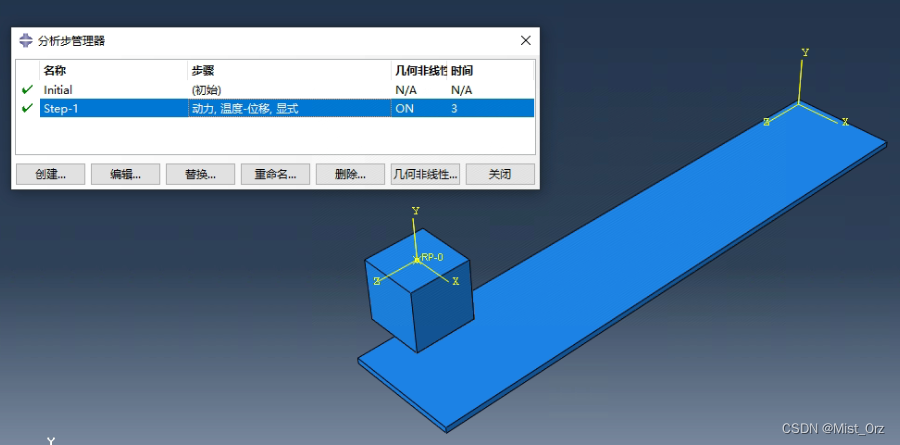
还不太清楚分析步应该怎样定义比较好,先定义一个3s的分析步,后面根据需要再改
场变量的话。。。就先这样?
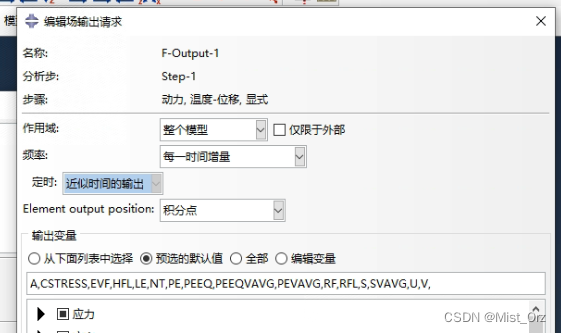
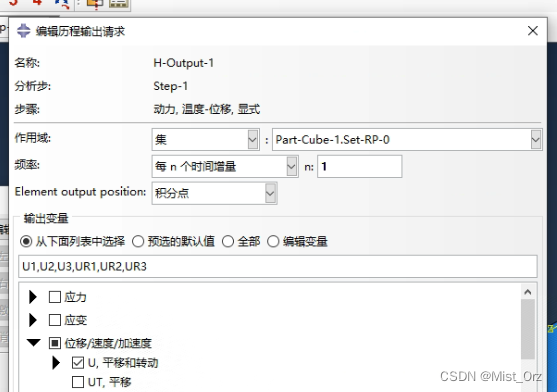
历程变量,输出参考点的位移
○ 相互作用
接触属性随便定义一下喽
反正不指望真的会接触,就弄个通用接触吧

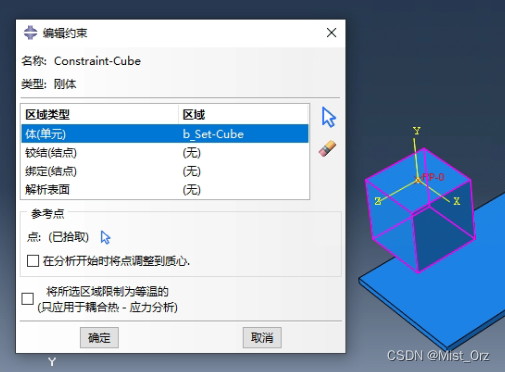
基本操作约束立方体
○ 载荷与边界条件
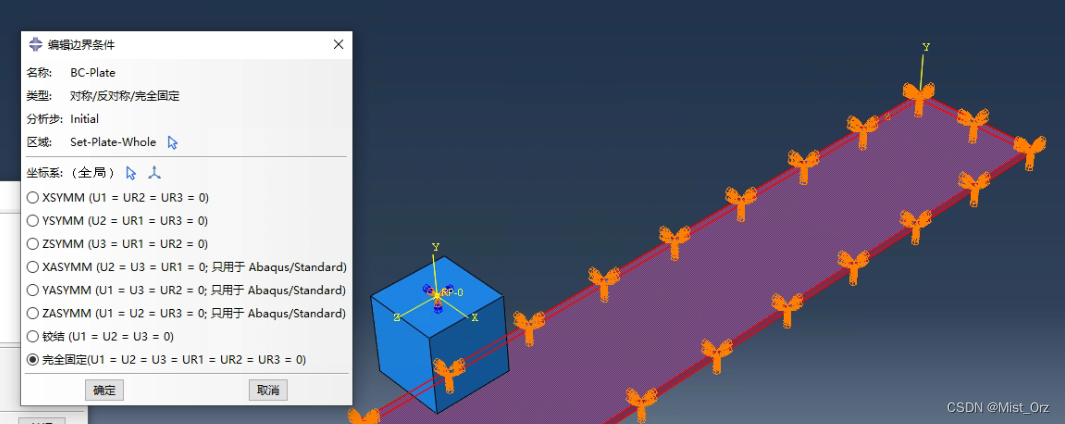
首先把底盘完全固定
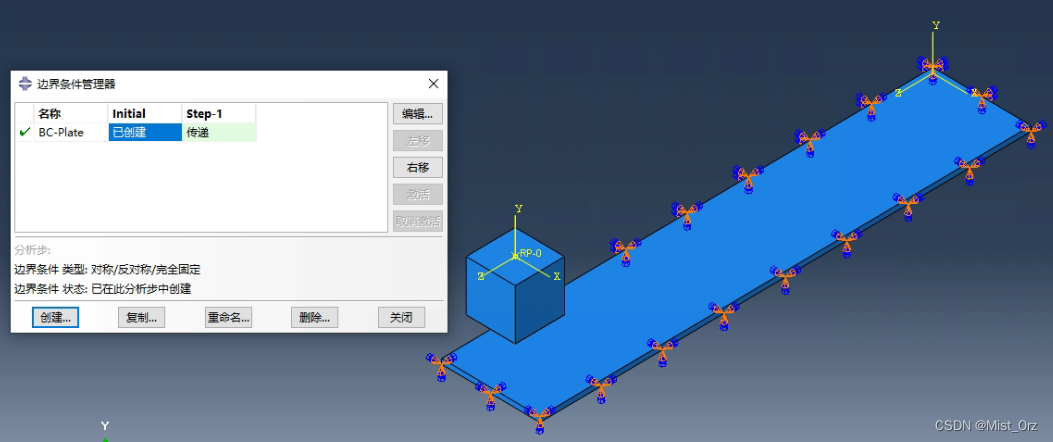
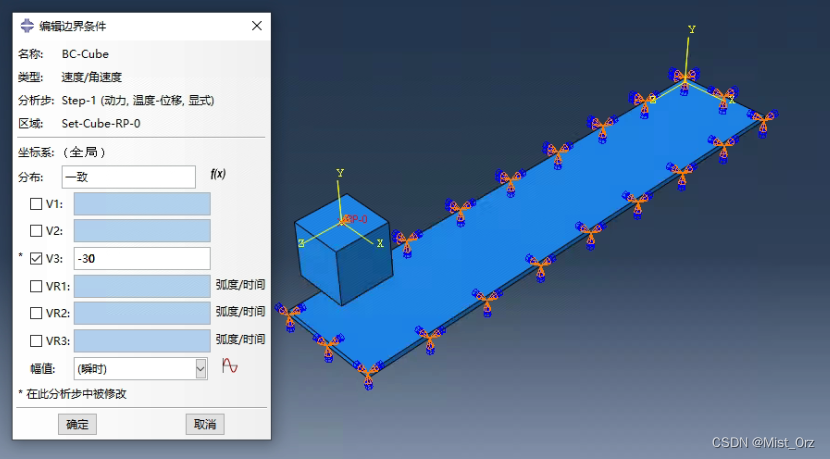
然后给立方体施加一个沿z轴负方向的平移运动(为了方便后面编辑)
○ 划分网格
网格随便划一下
○ 提交作业
效果如视频所示
AbaqusMatlab-job1
△ 输出并编辑inp文件
○ 输出inp文件
因为刚才提交过了,所以这里直接去工作目录找到inp文件就行了
○ 修改inp文件(错误示范)
在比较了youtube上老哥的方法和csdn上老哥的方法后,我发现他们的差异就是获取仿真数据的方法。
youtube老哥是通过修改inp文件使历程输出数据打印到dat文件中,然后再用matlab读取dat文件得到数据,而csdn老哥的方法是通过matlab调用python脚本读取odb文件中的历程输出数据。
在经过比较之后,我觉得youtube老哥的方法更好,毕竟youtube老哥提供了完整代码而且我自己也运行验证过。
【 !!!】但是后来发现,油管老哥的方法只适用于【隐式分析】,不能用在【显示分析】里面,扑街。。。。
但是油管老哥的方法和脚本依然有很重要的学习价值!
【 !】因为我需要用到的是显示分析,所以不能直接用油管老哥的方法,但是对于使用隐式分析的同学来说,这个方法还是很实用的,可以省去一步调用python脚本的操作。
那么,打开inp文件,定位到最后一行

添加我需要的历程输出

· 提交验证
!!!报错了!!!

他说这个关键字在显示分析里不可用???!!!
吓得我赶紧搜了下abaqus的官方帮助文档
芭比Q了呀。。。
只能用在隐式分析过程里面。。。
好吧,偷懒失败,只好回去看csdn老哥的文章了。。。。。‘’
顺便我也搜了一下从odb(output database)文件里读取数据的方法
果然和csdn老哥的脚本一样
【正确方法见后面内容。。。】
△ 验证脚本
○ 验证 odbHistoryOutput.py
odbHistoryOutput.py是个python脚本,需要用get_history_output.m这个函数来调用
· 获取odb文件
我按照文章的图片把脚本敲好,然后和inp文件放在同一个文件夹里

然后在matlab中提交inp文件给abaqus

得到odb文件
用abaqus打开odb文件,生成如下的历程输出
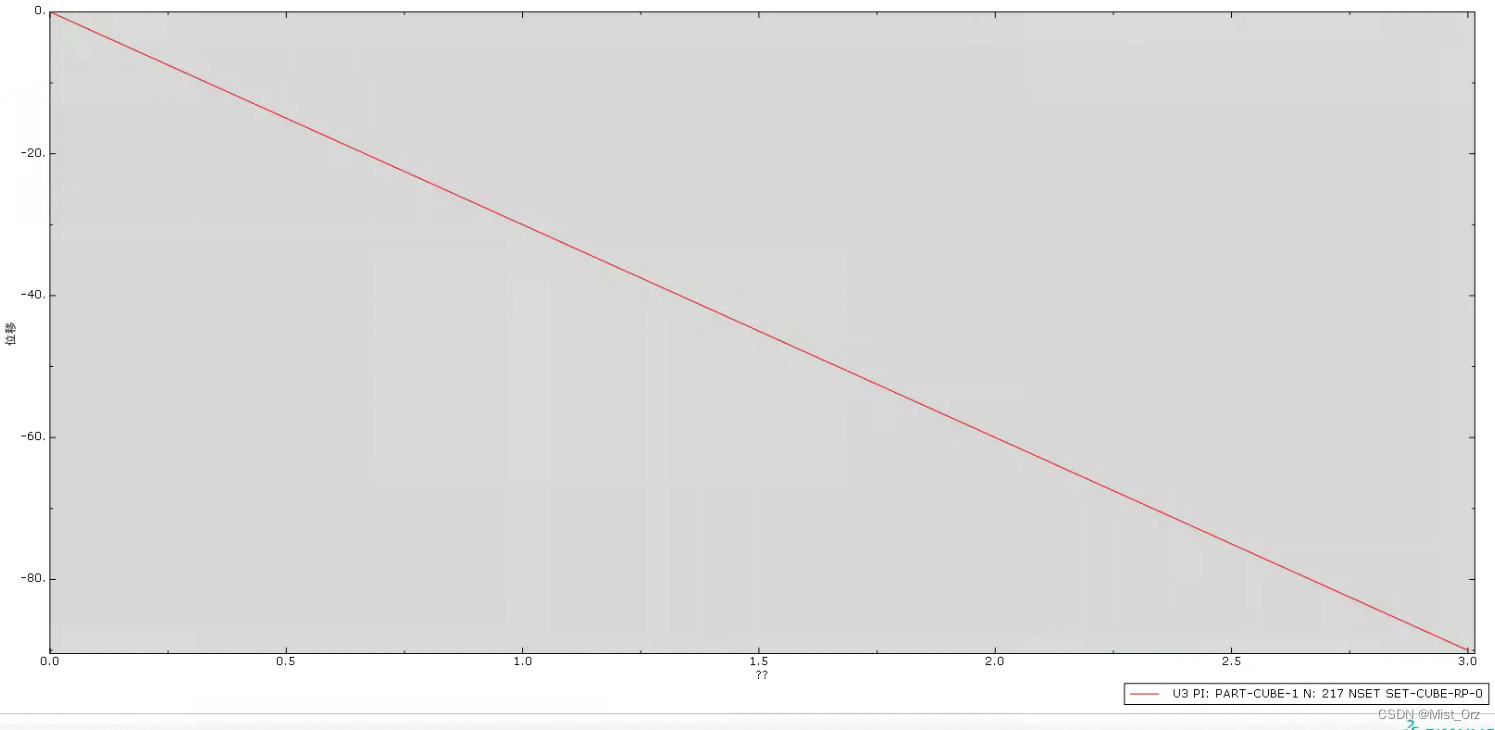
因为我只设置了沿z方向的运动,所以只有U3有数据。
· 使用 get_history_output.m 获取历程数据
为了使用这个函数调用python脚本文件,需要先编辑一个脚本文件,将模型的参数路径以及需要读取的节点和历程变量输入进去。
首先通过inp文件查看历程输出节点的编号

可以看到编号为217
我才发现,其实也不是必须从inp文件中得到节点编号,在上面的历程输出图像里面就显示了节点编号为217
然后参照文章中的示例,建立脚本文件“try_get_history_output.m”如下:
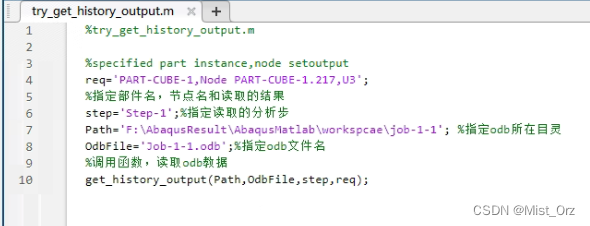
【 !】这里要注意“Node”后面接的是实例的名称不是节点集的名称,并且按照作者的说法,这里的名称无论命名的时候是大写还是小写,这里一律要用大写
· 运行验证
运行之后,程序会生成一个“req.txt”的文件,并用“odbHistoryOutput.py”脚本来读取,并生成一个“U3.txt”的文件来保存读取到的历程数据,并且生成一个“pylog.txt”的日志文件。
我用绘图指令画出“U3.txt”文件中的数据(因为偷懒又让chatgpt帮我写的诶嘿)
结果如下
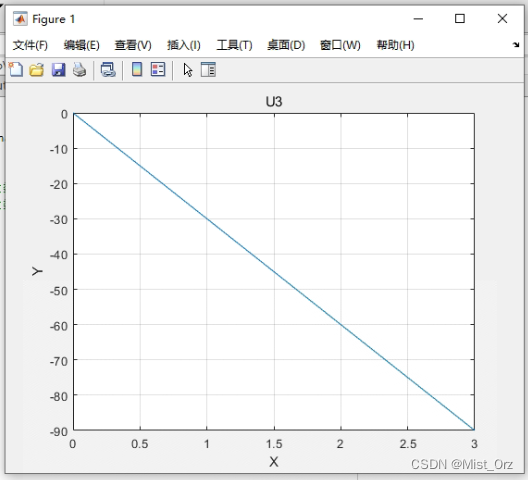
没有问题,能行!
○ 验证 inp2mfile.m
这个脚本是油管老哥案例里的,csdn老哥的文章只给了读取abaqus仿真结果的脚本,但是如果需要迭代优化的话还是得能够自动修改inp文件并提交。
所以这里我使用油管老哥的脚本来验证一下。
· 使用 inp2mfile.m 将inp文件转化为m文件
〇 将这个脚本与之前的文件放在一个目录里
〇 打开脚本修改相关词条
在这里我计划修改立方体的xyz方向的运行速度,所以修改如下

〇 运行脚本,生成 inp_initial.m
· 修改 inp_initial.m
〇 打开 inp_initial.m 定位到需要添加变量的位置

〇 按照油管老哥教的方法将立方体xyz方向的运动速度修改为变量形式
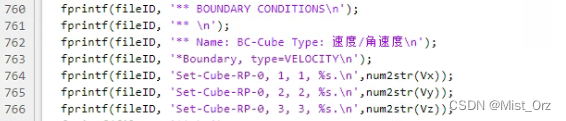
· 运行验证
新建一个脚本“try_inp_initial.m”
运行
打开inp文件
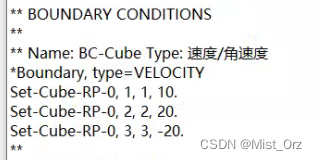
step-1的边界条件已经修改为设定的值。
△ 联合仿真
下面要新建一个脚本,将生成修改过的inp文件的过程,inp文件的提交过程,abaqus计算之后提取odb文件中历程数据的过程和读取结果的显示过程整合成一个完整的流程。
○ 建立联合仿真脚本
这里我不打算参考csdn老哥的 runabaqus.m 文件,而是主要参考油管老哥的脚本文件
新建一个“co_simulation.m”文件
%job-1-1的联合仿真
%通过MATLAB输入立方体沿xyz方向的速度,得到其对应方向的位移曲线
%zzz 20230514
%--------------------
%配置立方体的运动速度
Vx=10;
Vy=15;
Vz=-20;
%--------------------
%--------------------
%这部分代码chatgpt说是为了更新matlab的工作目录
close all
S = mfilename('fullpath');
f = filesep;
ind=strfind(S,f);
S1=S(1:ind(end)-1);
cd(S1)
%--------------------
%删除已存在的结果文件
delete('Job-1-1.odb');
delete('Job-1-1.lck');
%--------------------
%调用inp_initial.m生成inp文件
inp_initial(Vx,Vy,Vz);
pause(2)
%--------------------
%将生成的inp文件提交运算
system('abaqus job=Job-1-1 cpus=4 interactive' )
%--------------------
%等待计算完成
while exist('Job-1-1.lck','file')==2
pause(1)
end
while exist('Job-1-1.odb','file')==0
pause(1)
end
%--------------------
%调用get_history_output()获取历程数据
req1='PART-CUBE-1,Node PART-CUBE-1.217,U1';
req2='PART-CUBE-1,Node PART-CUBE-1.217,U2';
req3='PART-CUBE-1,Node PART-CUBE-1.217,U3';
step='Step-1';
Path='F:\AbaqusResult\AbaqusMatlab\workspcae\job-1-1';
OdbFile='Job-1-1.odb';
get_history_output(Path,OdbFile,step,req1);
get_history_output(Path,OdbFile,step,req2);
get_history_output(Path,OdbFile,step,req3);
%--------------------
%读取输出文件,绘制曲线图
filename1 = 'U1.txt';
filename2 = 'U2.txt';
filename3 = 'U3.txt';
data1 = readmatrix(filename1);
data2 = readmatrix(filename2);
data3 = readmatrix(filename3);
x = data1(:, 1);
y1 = data1(:, 2);
y2 = data2(:, 2);
y3 = data3(:, 2);
plot(x, y1, 'b-', x, y2, 'r-', x, y3, 'g-');
xlabel('时间');
ylabel('位移');
title('xyz位移曲线');
legend('x', 'y', 'z');
grid on;
○ 提交验证
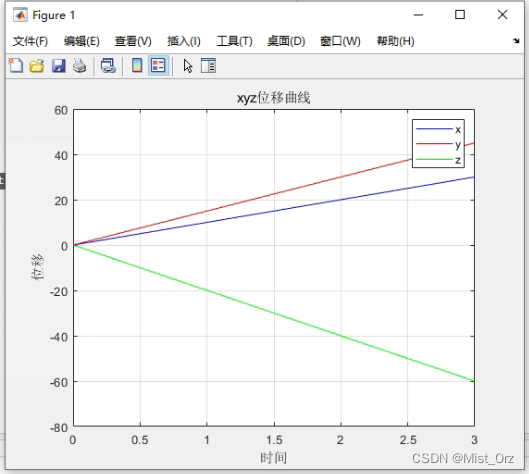
运行结果如下
用abaqus打开odb文件
AbaqusMatlab-job1-1
历程曲线
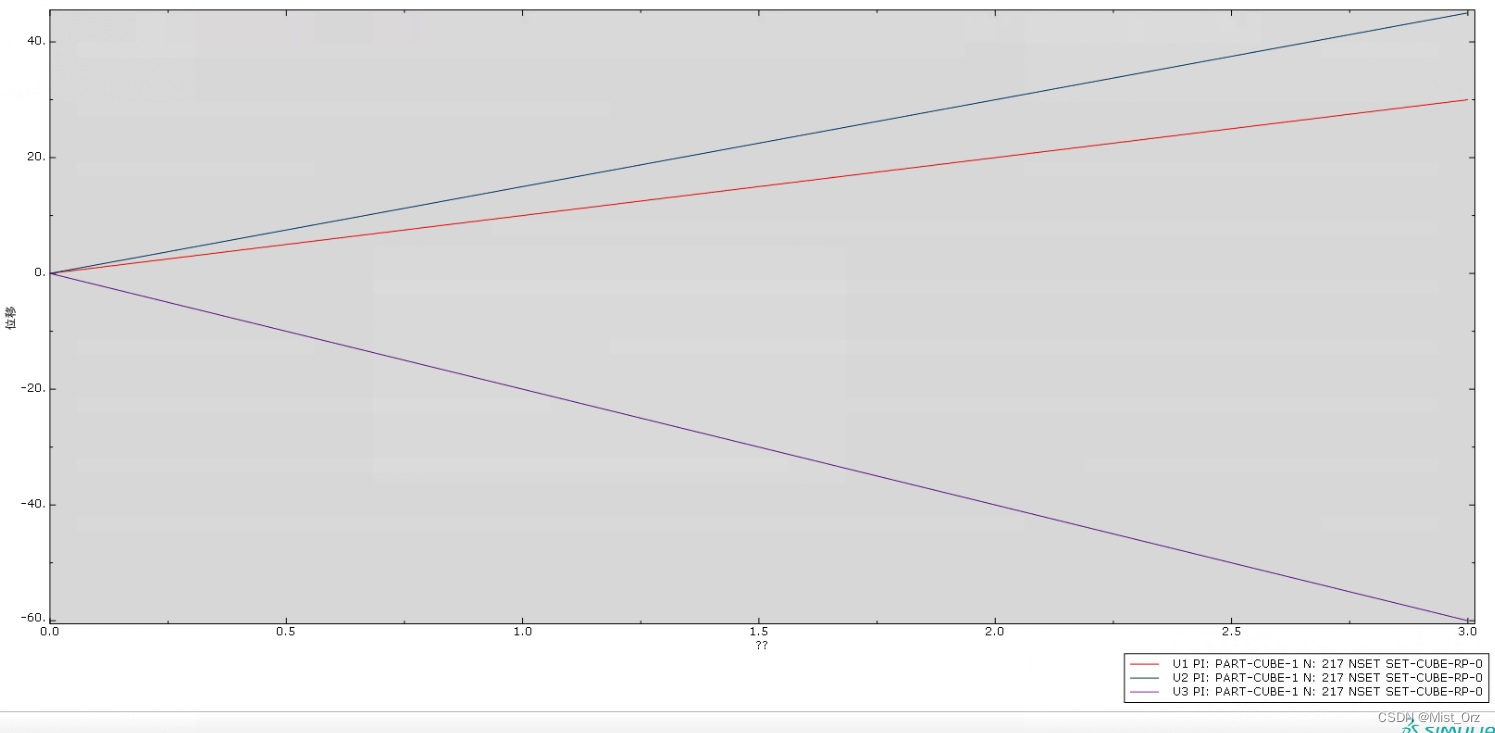
nice!
❤ 2023.5.29 ❤
我的联合仿真2——自动重启动分析
关于已经实现的联合仿真,现在还有个缺陷,就是一次提交之后只能等分析完成然后读取仿真结果。虽然实现了通过自动生成分析步将分析过程离散化处理,但是还没有做到我预期的能够实时对仿真过程进行干预
我最开始的想法是通过abaqus的子程序实现与matlab的通讯,然后控制仿真参数,但是目前没有直接的材料能证明可以实现,但是在查资料的过程中我看到了关于重启动分析的内容,顾名思义,就是通过预先设置可以实现在仿真运算过程意外中断之后,可以不从头开始,而是从已完成的分析步作为起始,重新进行当前分析步的运算,并且可以修改未进行的分析步的参数。
经过思考,我觉得可以实现将整个仿真过程离散化,然后通过重启动分析实现对下一个分析步参数的准实时更新。
不过是不是能够实现和matlab的联合仿真我还不是很确定。
关于重启动分析,我找到几个视频资料
→→→【ABAQUS重启动分析】
比较基础的重启动分析内容
→→→【ABAQUS重启动分析】
这个视频讲了基本的手动实现重启动分析的方法,并演示了分析中断重启动和在已有分析后面添加分析步重启动两种操作方法。



下面先从手动重启动分析开始。
△ abqus手动重启动分析
【MovingCube20230813】
○ 建立模型
- 这里依然用上面的立方体模型并进行修改
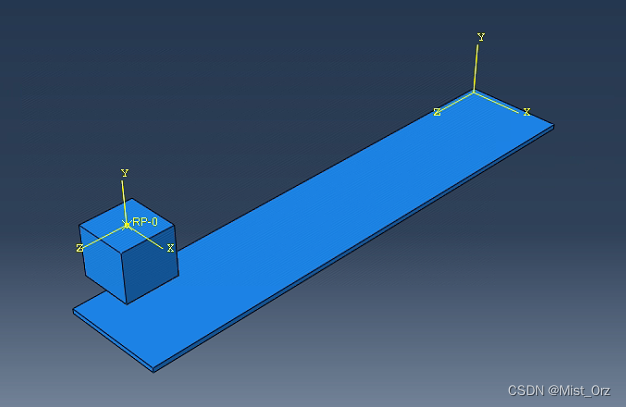
- 修改分析步,如下,使用和之前相同的配置
- 边界条件修改为沿-z方向-20mm/s,x方向±10mm/s摆动
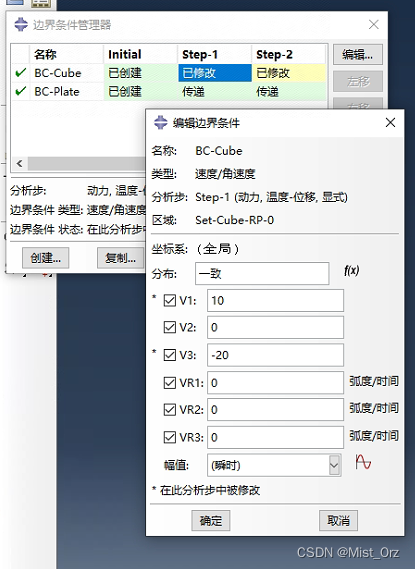
-
设置工作目录
-
提交
-
可视化
yanshi1
○ 配置手动重启动分析
- 在分析步界面,点输出→重启动请求
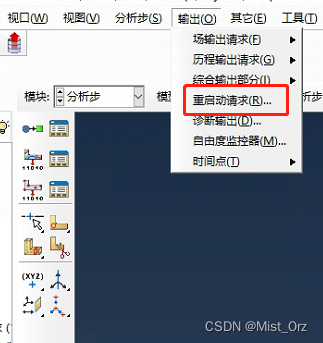
- 编辑重启动请求
可能因为我的是显式分析,所以界面是这样的,
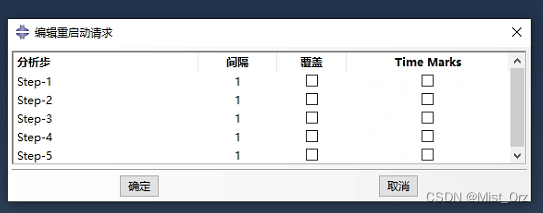
如果是隐式分析,大概界面长这样
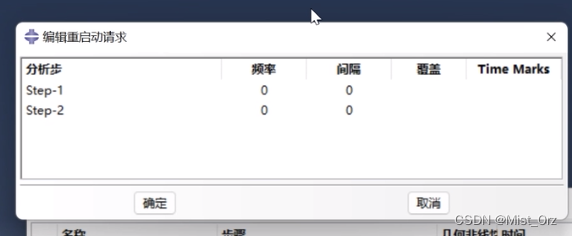
其中:
- 频率:Frequency
- 间隔:Intervals
- 覆盖:Overlay
- Time Marks
以上选项的含义

因为在显式分析中只有间隔(intervals)一个参数,所以这个参数的含义我又了解了下,大概就是一个分析步输出多少个重启动数据。

所以这里可以看到,重启动分析默认是打开的
在工作目录里也找到了重启动的res文件

○ 重启动分析
- 复制模型
将需要重启动分析的模型复制一份
- 创建作业
- 选择重启动
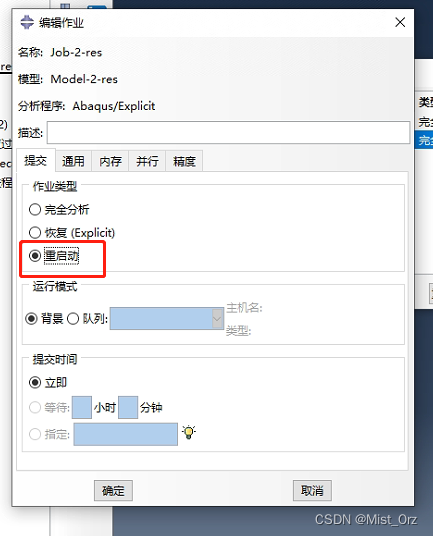
其他设置不变
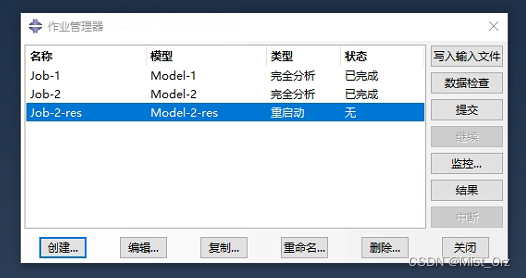
- 编辑重启动模型属性
在模型属性中勾选“从下列作业中读取数据”,后面输入此模型对应的含有重启动res文件的作业名(不用加.res的后缀)
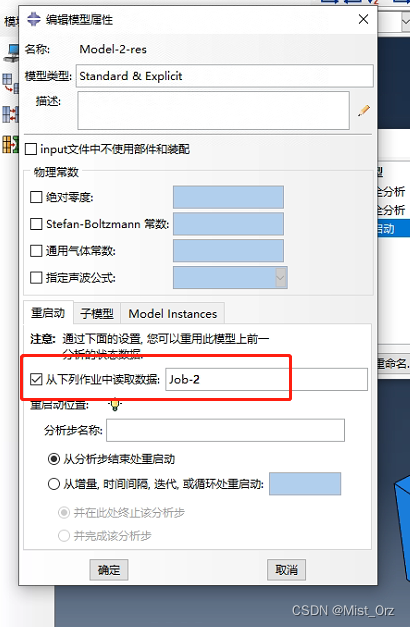
分析步名称这里填写重启动的分析步
确定
-
提交
-
结果
可以看到这里是从step-4开始计算的
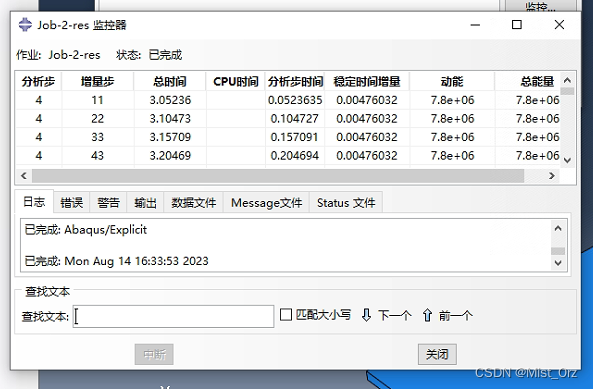
可视化结果也是从step-4的位置开始的
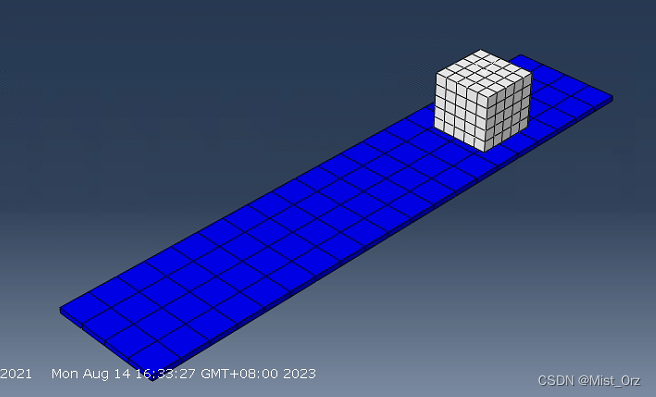
OK,以上就是手动重启动分析
重启动分析可以修改后面的分析步,可以更改边界条件等参数,这里就不演示了。
其实重启动分析还包括ODB结果文件的合并,这个放在后面自动重启动里面再说吧。
△ abaqus与matlab实现自动重启动分析
自动重启动分析的目的是根据前一步的仿真结果进而调整下一步的仿真参数
○ 仿真模型
既然是重启动分析,那么首先需要建立一个包含重启动信息的仿真模型。
这里继续偷懒,用上面的开启了重启动请求的Job-2来做接下来的步骤
- 将Job-2的输出的文件一起复制到新的文件夹里
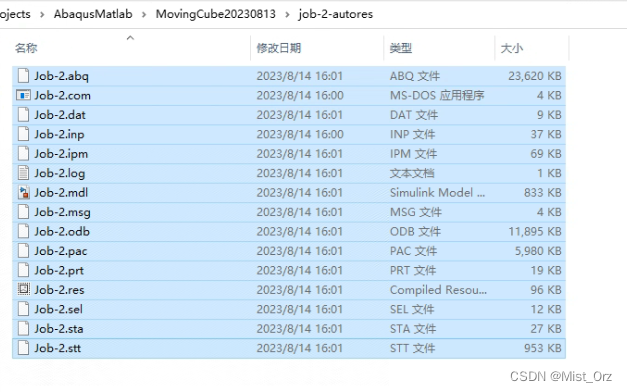
- 将上面job-2的重启动工程job-2-res的inp文件复制过来

使用matlab调用abaqus最重要的就是这个inp文件了,打开重启动的inp文件可以看到里面的内容和最初的inp文件相差甚远,所以我推测,这个inp文件是实现自动重启动的关键
job-2-res文件内容
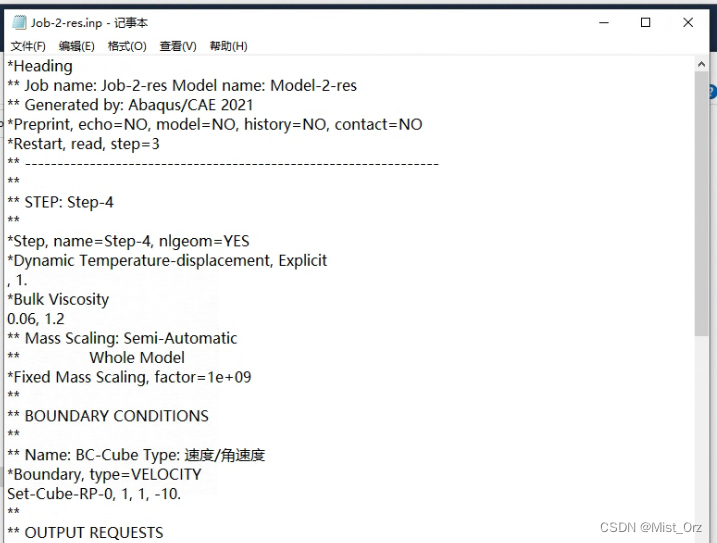
· 测试使用inp文件重启动
- 首先将Job-2-res工程生成的inp文件复制并修改为“Job-2-res-inptest.inp"

- 修改内容,只保留一个分析步,并修改边界条件

- 在作业管理器中创建输入文件的作业,并提交
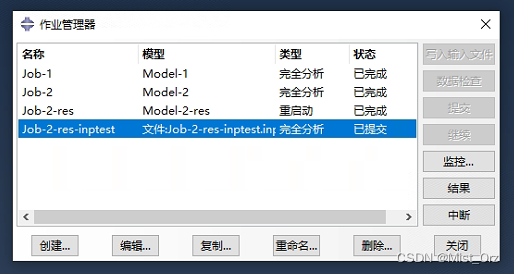
提交之后一直转圈圈,看来这样不太行
- 使用命令行提交inp文件
猜测可能是直接用作业管理器提交inp文件的话,作业里没有原作业信息,但是命令行里面是可以设定原作业的
ABAQUS job=Job-2-res-inptest oldjob=Job-2

输完之后命令行里并没有显示,但是工作目录里有了新的文件
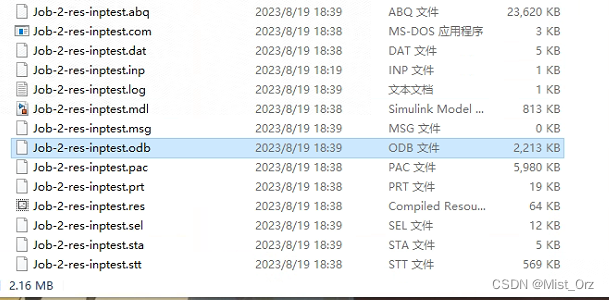
- 结果及可视化
打开odb文件

没有问题,行得通!
○ 使用inp2mfile.m生成inp脚本文件
复制油管老哥的inp2mfile.m脚本文件到工程目录

打开编辑
- 首先将文件名替换成所需的“Job-2-res.inp”

- 修改输出的inp文件名

- 添加变量
根据“Job-2-res.inp”文件来分析,在每一步重启动分析过程中,需要修改的变量,除了下一步的Vx,Vy,Vz外,还有当前的分析步名和下一步分析步名。

- 生成“inp_initial.m”函数文件
运行“inp2mfile.m”
得到

○ 编辑“inp_initial.m”函数
这里再来分析一下“Job-2-res.inp”文件的内容
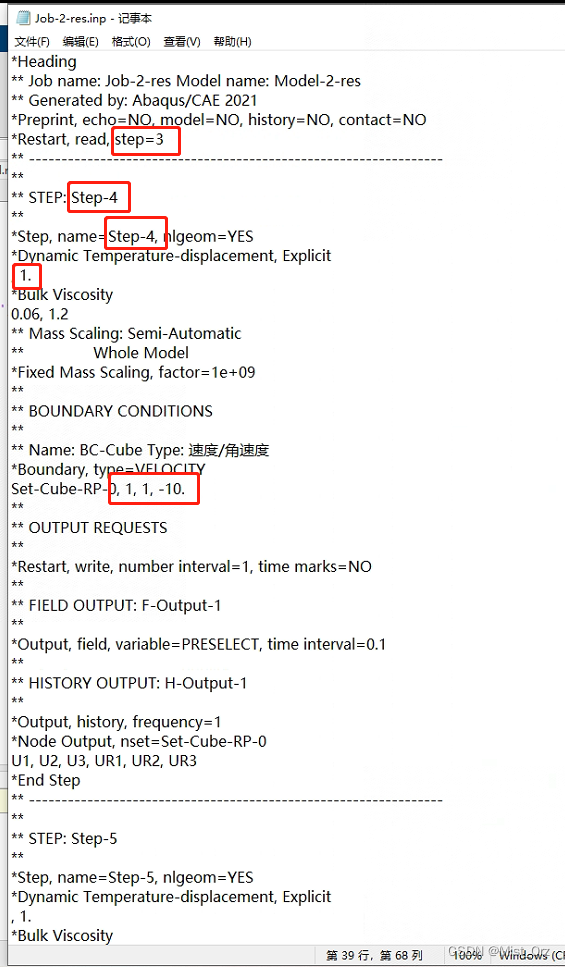
红框中的是可以修改的内容,对应的是当前分析步、下个分析步、分析步时间、边界条件
与此对应修改“inp_initial.m”中内容如下
- 首先删除多余的分析步
作为模板的“Job-2-res.inp”配置了接下来的2个分析步,这里只保留一个
- 修改分析步
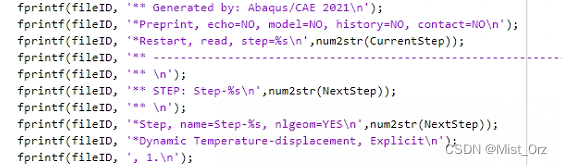
- 修改边界条件

· 测试“inp_initial.m”函数
创建脚本,调用“inp_initial.m”函数,将设定好的参数写入inp文件,然后再启动重启动分析
%inp_initial.m函数测试程序
clc; clear all; close all
CurrentStep = 3;
NextStep = 4;
Vx = 10;
Vy = 20;
Vz = 30;
inp_initial(CurrentStep,NextStep,Vx,Vy,Vz);
pause(2);
system('abaqus job=Job-2-AutoRes oldjob=Job-2 cpus=4 interactive' )
运行。。。
报错了
Analysis initiated from SIMULIA established products
Abaqus JOB Job-2-AutoRes
Abaqus 2021
Abaqus License Manager checked out the following licenses:
Abaqus/Explicit checked out 8 tokens from Flexnet server localhost.
<9991 out of 9999 licenses remain available>.
Begin Analysis Input File Processor
8/19/2023 10:49:03 PM
Run pre.exe
8/19/2023 10:49:24 PM
End Analysis Input File Processor
Begin Abaqus/Explicit Packager
8/19/2023 10:49:24 PM
Run package.exe
***WARNING: A restart analysis uses the same number of parallel domains as the
original analysis. The current value for domains will be ignored.
Abaqus/Explicit 2021 DATE 19-8月-2023 TIME 22:49:45
8/19/2023 10:49:45 PM
End Abaqus/Explicit Packager
Begin Abaqus/Explicit Analysis
8/19/2023 10:49:45 PM
Run explicit.exe
***ERROR: The parallel domains cannot be distributed equally to the number of
cpus requested (4). The number of parallel domains must be a
multiple of the number of cpus. There are 10 parallel domains in the
model.
***ERROR: The parallel domains cannot be distributed equally to the number of
cpus requested (4). The number of parallel domains must be a
multiple of the number of cpus. There are 10 parallel domains in the
model.
***ERROR: The parallel domains cannot be distributed equally to the number of
cpus requested (4). The number of parallel domains must be a
multiple of the number of cpus. There are 10 parallel domains in the
model.
***ERROR: The parallel domains cannot be distributed equally to the number of
cpus requested (4). The number of parallel domains must be a
multiple of the number of cpus. There are 10 parallel domains in the
model.
job aborted:
[ranks] message
[0] application aborted
aborting MPI_COMM_WORLD (comm=0x44000000), error 1, comm rank 0
[1] application aborted
aborting MPI_COMM_WORLD (comm=0x44000000), error 1, comm rank 1
[2] application aborted
aborting MPI_COMM_WORLD (comm=0x44000000), error 1, comm rank 2
[3] application aborted
aborting MPI_COMM_WORLD (comm=0x44000000), error 1, comm rank 3
---- error analysis -----
[0-3] on LAB-ZONG
C:\Users\DELL\AppData\Local\Temp\DELL_Job-2-AutoRes_13704\tmp6fngdg.bat aborted the job. abort code 1
---- error analysis -----
8/19/2023 10:50:07 PM
Abaqus Error: Abaqus/Explicit Analysis exited with an error - Please see the
status file for possible error messages if the file exists.
Abaqus/Analysis exited with errors
ans =
0
>>
这个意思是。。。分配cpu核心数和原始作业不一样?
那我改一下
%inp_initial.m函数测试程序
clc; clear all; close all
CurrentStep = 3;
NextStep = 4;
Vx = 10;
Vy = 20;
Vz = 30;
inp_initial(CurrentStep,NextStep,Vx,Vy,Vz);
pause(2);
system('abaqus job=Job-2-AutoRes oldjob=Job-2 cpus=10 interactive' )
嗯,这回successfully了
可能其实不用分配这个cpu核心数吧
可视化

○ 自动重启动分析加ODB文件合并
根据刚刚的重启动实验,我们发现使用重启动命令生成的ODB文件只有重启动部分的数据,但是我们的目标是输出完整的结果文件,于是就需要使用ODB文件合并指令。
参考资料:

根据资料可知,ODB文件合并只能通过命令行进行,命令为
abaqus restartjoin originalodb=Job-1.odb restartodb=Job-2.odb copyoriginal
加了copyoriginal就不会覆盖原ODB
于是我来试一下
· 单步自动重启动加ODB合并
- 首先备份Job-2.odb文件
防止被覆盖

- 流程说明
首先还是在job-2的基础上进行自动重启动分析
单个重启动步骤
重启分析动完成后对ODB文件进行合并
- 首先针对当前工程修改“inp_initial.m“函数
使其生成的inp文件中包含分析步序号
同时我在这里修改了之前的变量名
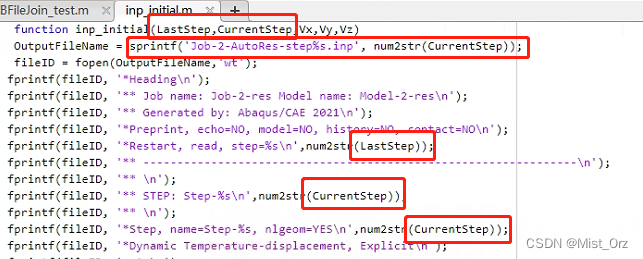
因为输出文件的文件名要随迭代步变化,所以这里用sprintf()函数
- 建立脚本文件
% 测试abaqus自动重启动分析过程的ODB文件自动合并
clc; clear all; close all
LastStep = 3;
CurrentStep = 4;
Vx = 10;
Vy = 20;
Vz = 10;
inp_initial(LastStep,CurrentStep,Vx,Vy,Vz);
pause(2);
system(sprintf('abaqus job=Job-2-AutoRes-step%s oldjob=Job-2 cpus=10 interactive', num2str(CurrentStep)))
% 等待计算完成
while exist(sprintf('Job-2-AutoRes-step%s.lck', num2str(CurrentStep)),'file')==2
pause(1)
end
while exist(sprintf('Job-2-AutoRes-step%s.odb', num2str(CurrentStep)),'file')==0
pause(1)
end
system(sprintf('abaqus restartjoin originalodb=Job-2.odb restartodb=Job-2-AutoRes-step%s.odb copyoriginal', num2str(CurrentStep)))
这里依然用了sprintf()函数实现输出文件的自动编号
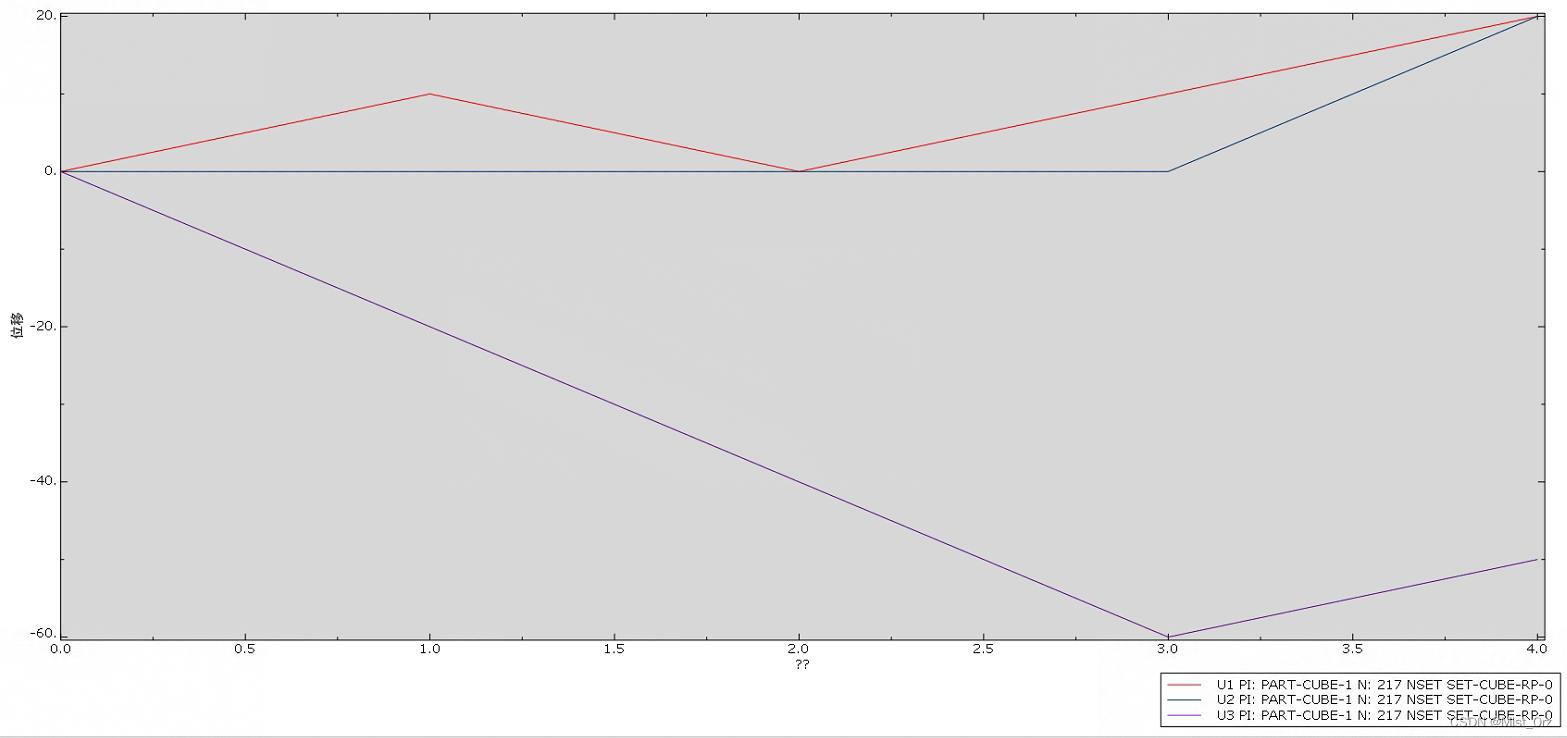
- 可视化、

job-2-AutoRes-2-1
没有问题,所有分析步的结果都有,但是没有例程数据
- 在合并ODB指令中加入history
提交
OK no problem
· 多步自动重启动加ODB合并
这里在上一个实验的基础上先验证可不可以在重启动工程上再次进行重启动分析
代码
% 测试abaqus自动重启动分析过程的ODB文件自动合并,2个分析步
clc; clear all; close all
%% 初始参数设定
LastStep = 3;
CurrentStep = 4;
Vx = 10;
Vy = 20;
Vz = -10;
%% 第一次重启动
inp_initial(LastStep,CurrentStep,Vx,Vy,Vz);
pause(2);
system(sprintf('abaqus job=Job-2-AutoRes-step%s oldjob=Job-2 cpus=10 interactive', num2str(CurrentStep)))
% 等待计算完成
while exist(sprintf('Job-2-AutoRes-step%s.lck', num2str(CurrentStep)),'file')==2
pause(1)
end
while exist(sprintf('Job-2-AutoRes-step%s.odb', num2str(CurrentStep)),'file')==0
pause(1)
end
% 第一次合并不覆盖原文件
system(sprintf('abaqus restartjoin originalodb=Job-2.odb restartodb=Job-2-AutoRes-step%s.odb copyoriginal history', num2str(CurrentStep)))
pause(10)
%% 第二次重启动参数设定
LastStep = 4;
CurrentStep = 5;
Vx = -10;
Vy = -20;
Vz = -10;
%% 第二次重启动
inp_initial(LastStep,CurrentStep,Vx,Vy,Vz);
pause(2);
system(sprintf('abaqus job=Job-2-AutoRes-step%s oldjob=Job-2-AutoRes-step%s cpus=10 interactive', num2str(CurrentStep), num2str(LastStep)))
% 等待计算完成
while exist(sprintf('Job-2-AutoRes-step%s.lck', num2str(CurrentStep)),'file')==2
pause(1)
end
while exist(sprintf('Job-2-AutoRes-step%s.odb', num2str(CurrentStep)),'file')==0
pause(1)
end
% 第二次合并使用Restart_Job-2.odb文件,并覆盖原文件
system(sprintf('abaqus restartjoin originalodb=Restart_Job-2.odb restartodb=Job-2-AutoRes-step%s.odb history', num2str(CurrentStep)))
pause(10)
提交,
没有问题,过程很顺利,也就是说在直接在重启动分析基础上就可以再次重启动,不需要再去编辑原来的inp文件
job-2-AutoRes-2-2
总结
我觉得这个学习笔记到这里就可以了。
本来还想再做一个通过循环实现的多步重启动分析,但是觉得既然2步能实现那么多步也没有问题,就没有必要再做了
我自己的两个实验解决了在matlab中提交abaqus仿真、读取仿真结果、再次提交仿真、合并仿真结果的流程
好了,接下来要做的就是我自己的东西了,涉及到论文这里就不写了
关于联合仿真可以应用的研究课题有很多,希望这篇关于abaqus和matlab联合仿真的学习笔记能给相关专业的本科生和研究生同学提供新的研究思路和帮助哈~
❤ 2023.10.30
【注意】在经过我好长时间的调试与验证之后,发现。。。abaqus是有最大重启动次数限制的。。。
至少我用的2021版本最多只能进行100次重启动分析,第101次就会报错。。。
emmmm…辣鸡!

















 3885
3885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









