







Focal Loss
Focal Loss的引入主要是为了解决难易样本数量不平衡(注意,有区别于正负样本数量不平衡)的问题,实际可以使用的范围非常广泛,为了方便解释,还是拿目标检测的应用场景来说明:
单阶段的目标检测器通常会产生高达100k的候选目标,只有极少数是正样本,正负样本数量非常不平衡。我们在计算分类的时候常用的损失——交叉熵的公式如下:
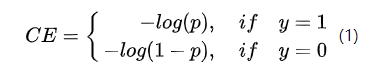
为了解决正负样本不平衡的问题,我们通常会在交叉熵损失的前面加上一个参数 alpha,即:
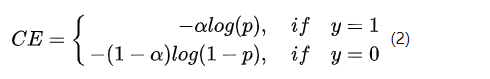
但这并不能解决全部问题。根据正、负、难、易,样本一共可以分为以下四类:
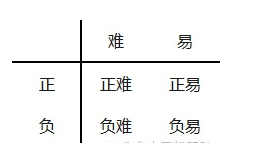
尽管 alpha 平衡了正负样本,但对难易样本的不平衡没有任何帮助。而实际上,目标检测中大量的候选目标都是像下图一样的易分样本。
这些样本的损失很低,但是由于数量极不平衡,易分样本的数量相对来讲太多,最终主导了总的损失。而本文的作者认为,易分样本(即,置信度高的样本)对模型的提升效果非常小,模型应该主要关注与那些难分样本(这个假设是有问题的,是GHM的主要改进对象)
这时候,Focal Loss就上场了!
一个简单的思想:把高置信度§样本的损失再降低一些不就好了吗!

举个例, [公式] 取2时,如果 [公式] , [公式] ,损失衰减了1000倍!
Focal Loss的最终形式结合了上面的公式(2). 这很好理解,公式(3)解决了难易样本的不平衡,公式(2)解决了正负样本的不平衡,将公式(2)与(3)结合使用,同时解决正负难易2个问题!
最终的Focal Loss形式如下:
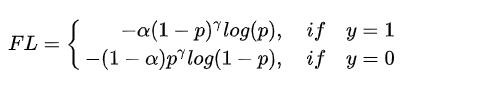
实验表明[公式] 取2, [公式] 取0.25的时候效果最佳。
这样以来,训练过程关注对象的排序为正难>负难>正易>负易。
这就是Focal Loss,简单明了但特别有用。

















 2682
2682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









