







RCNN:Regions with CNN
背景
在RCNN出现以前,目标检测系统一般通过将多个low-level图像特征进行结合,来产生high-level的特征。
创新点
1.将CNN与region proposals相结合,首次展现出CNN在object detection问题上的强大威力,各种碾压传统方法
2.将图像分类与目标检测联系起来,利用预训练好的图像分类模型+少量数据的domain-specific微调,解决了训练数据不足的问题。
3.利用RCNN完成了语义分割的任务。
基于RCNN的目标检测
算法流程见下图(详见图片描述)
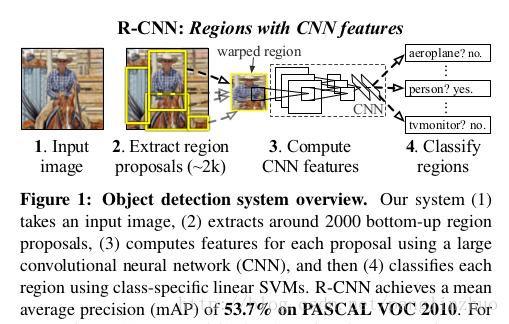
At test time:
1.对每一张测试图像,采用selective search得到2000张左右的region proposals(即目标候选框框)。
2.对每一个region进行仿射变换并传递给CNN,以求出长度一定的feature。即使region大小不一,CNN输出的feature长度也是一定的~
3.用线性SVM对每一个region对应的feature进行分类,并统计得分。注意:如果一共有N类,则每一个region需要分别输入给N个SVM分类器,得到N个得分。若regions一共2000个,则SVM输出的矩阵维度就是2000xN
4.采用非极大抑制算法(non-maximum suppression )从所有scored-regions中选出置信度最高的bounding box做为目标的框框。
pretraining and fine-tuning
pretraining:
采用的是图像分类模型Imagenet(输出为1000维向量,即可以对1000种物体进行分类)
domain-spesific fine-tuning:
将最后的1000维输出层替换为N+1维输出,N指的是分类任务中的物体类别数目,1代表背景,其余结构不变。
训练数据:
positive samples:ground-truth regions以及与groundtruth region重叠率大于0.3的selective search regions
negative samples:与groundtruth region重叠率小于0.3的selective search regions
注意:
1.在fine-tuning时,学习率为预训练模型的十分之一,这使得原来的模型参数不会剧烈变化。
2.由于正负样本的比例悬殊较大,通过增大正样本的采样率来保证训练的有效进行。
SVM Training
一旦得到CNN提取到的region proposals的features及其对应的labels(物体类别),就可以训练SVM分类器了。由于训练数据太多,内存占用很高,采用标准的hard negative mining method[P. Felzenszwalb, R. Girshick, D. McAllester, and D. Ramanan. Object detection with discriminatively trained part based models. TPAMI, 2010. 2, 4, 7, 12][K. Sung and T. Poggio. Example-based learning for view-based human face detection. Technical Report A.I. Memo No. 1521, Massachussets Institute of Technology, 1994. 4]得到hard negative samples,这样可以更有效的更新分类器参数。
训练数据:(与fine-tuningCNN时的数据有点不同哦~)
positive samples:ground-truth regions
negative samples: 与ground truth bounding box重叠率小于0.3的selective search regions
这里有个问题:
CNN输出features后,为什么不直接连一个softmax层输出各类别的概率呢而要单独训练一个SVM呢?作者在论文中也给出了解答。
Bounding-box regression
Bounding-box regression是干啥的?
给定一个region proposal,输入CNN得到pool5 features,将其输入给一个线行回归模型以预测detection window。Bounding-box regression就是一个预测detection window的东东。
训练数据:
输入为region proposal的坐标(region中心点坐标以及region的长、宽),输出为groundtruth box的坐标(box中心点坐标以及box的长、宽)
目的就是将一个proposal box与ground-truth box形成映射。
Region Proposals
即目标的候选区域。
Recognition using proposals已成功应用在目标检测[J. Uijlings, K. van de Sande, T. Gevers, and A. Smeulders.Selective search for object recognition. IJCV, 2013. 1, 2, 3, 4, 5, 9]、语义分割[J. Carreira and C. Sminchisescu. CPMC: Automatic object segmentation using constrained parametric min-cuts. TPAMI, 2012. 2, 3]中。
非极大抑制算法
Non-Maximum Suppression就是需要根据score矩阵和region的坐标信息,从中找到置信度比较高的bounding box。首先,NMS计算出每一个bounding box的面积,然后根据score进行排序,把score最大的bounding box作为队列中。接下来,计算其余bounding box与当前最大score与box的IoU,去除IoU大于设定的阈值的bounding box。然后重复上面的过程,直至候选bounding box为空。最终,检测了bounding box的过程中有两个阈值,一个就是IoU,另一个是在过程之后,从候选的bounding box中剔除score小于阈值的bounding box。
需要注意的是:
Non-Maximum Suppression一次处理一个类别,如果有N个类别,Non-Maximum Suppression就需要执行N次。
Visualizing learned features
作者采用了一种简单的non-parametric方法来可视化网络学习到的东西。
The idea is to single out a particular unit (feature) in the network and use it as if it were an object detector in its own right. That is, we compute the unit’s activations on a large set of held-out region proposals (about 10 million), sort the
proposals from highest to lowest activation, perform non-maximum suppression, and then display the top-scoring regions. Our method lets the selected unit “speak for itself” by showing exactly which inputs it fires on.
我的理解是:对于某一个输入的region proposal,CNN输出此region对应的多个features,其中每个features都是一个小方块,每个小方块中的一个点就是一个unit(feature)。选择其中的一个unit(feature),将这个feature看做一个卷积核,在一系列region proposals上面滑动,计算出其在各个regions上面的激活值,激活值最大的region就是它所fires on的region。(因为这个region与所输入的region proposal具有相似的feature,所以才会对其有较高的响应值。)
层数越深,效果不一定越好
实验发现,采用预训练的模型完成目标检测任务时,只采用pool5 layer即可得到较好的效果,加上了fc6和fc7之后,效果反而下降了。这说明,CNN强大的特征表示能力主要来源于卷积层而不是全连接层。
采用domain-spesific fine-tuning后的模型进行目标检测时,fc6和fc7层的存在反而使得检测效果变好了,这说明pool5 layer学习到的特征是general features,在微调的过程中,fc6 和 fc7 层把pool5 featurs与特定的目标检测任务做了映射,也就是说,检测效果提高的原因主要归功于fc6和fc7层。
RCNN实时性较高的原因
1.feature的维度较低
2.权值共享:对任意类别的测试样本,将region proposals输入给一个CNN卷积网络后得到不同region的特征,后面经过SVM分类器输出目标的类别。由于这个CNN网络是唯一的,将features与类别进行映射的工作就是由最后的featur层与SVM之间的权重矩阵完成的:若CNN输出的features为2000*4096,SVM输出为N维向量,则权重矩阵就是4096*N大小















 388
388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









