







今天看到一个广告的精排和重排的文章,里面有了一个pcoc的指标,跟auc并排,这个指标,第一次见,查查相关资料,记录下笔记。
众所周知,在推荐系统中,很多情况下,我们的点击率通常会被错误的估计(通常会被高估),所以需要进行校准。
先说下业务背景
预估偏差的客观存在
随着深度学习技术的发展,预估模型在过去几年中也经历了快速的迭代,不断向更庞大、更精细、更准确的方向演进。但是预估模型真的变得更准确了吗?不失一般性,我们以计算广告中的点击率预估模型为例,思考以下几个问题:
1)用户的真实点击概率是可以被准确观测的吗?
点击率是指“用户在某个时刻对曝光广告进行点击的概率”。理论上每条流量都存在一个潜在的点击概率,从统计意义上来讲,如果存在平行空间将广告曝光给某个用户的事件重复多次,则可以根据大数定律将用户的点击概率估算出来。但是在真实世界中,我们能且仅能观察到事件的单次发生(点击与否),所以是无法准确观测到任意样本的真实点击概率的
2)点击率预估模型的准确性偏差原因是什么?
因为真实点击概率是不可以被准确观测到的,所以点击率预估模型也不能直接对点击率进行回归预测。现有点击率预估模型通常从统计视角对问题进行抽象和简化,假设特征和点击事件的联合分布服从某种函数形式(不同模型的假设分布不同),然后以Data-Driven的方式训练模型,实现对点击率的预测。但是该预测值是对真实点击概率的猜测,其预估偏差根本取决于分布假设与实际情况的差异程度,并受限于模型的真实学习效率
3)预估模型的准确性如何度量,AUC指标是足够的吗?
我们无法对预测结果从单样本粒度来度量其准确性(真实点击概率的不可预测性)。AUC是一种退而求其次从宏观层面对样本的比较关系进行度量的指标,反映了预测序关系对真实序关系的逼近程度。但是它无法表征预估值的“大小准确性”。大小准确性是指,如果广告点击率是1%,则意味着广告曝光10000次后将有100次被真实点击。如果低于100次,则意味着模型高估,反之则意味着模型低估。所以仅仅考虑序关系是不全面的,校准技术在本质上是一种在现有模型基础上进一步优化预估值大小准确性,使其尽可能逼近(近似)真实值的技术
1.怎么校准
校准技术的目标是:使用户行为的预估值尽可能逼近真实概率值。具体形式化表示如下,其中X为基础预估模型的输出空间(如预估点击率),Y为实际用户行为(如点击与否),f(x)为校准函数,f*为最优校准函数。在实际应用中,优化预估值大小准确性的同时,也会保证整体排序水平不会下降。
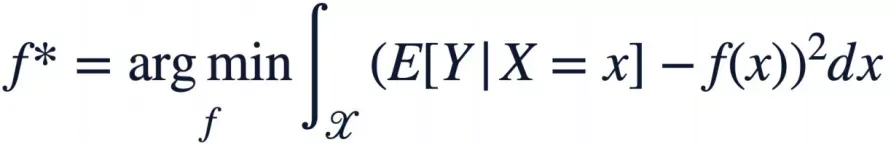
② 相关工作
现有预估模型在预估值上的不确定性,导致在实际应用中缺乏可信度(trustworthiness)和可解释性(interpretability),会导致次优结果甚至错误决策的风险,校准技术最早在气象预报和医疗诊断领域被提出和应用,近几年进一步延伸到自动驾驶和计算广告领域。具体校准方法总的来讲可以分为两大类:
第一类是尝试将导致模型预估偏差的因素(如假设分布偏差等各类先验信息)反向引入特征处理或损失函数中,端到端优化预估值大小。
第二类是后处理方法(Post-processing),即在基础预估模型的基础上串接一个校准模块,以后处理的方式得到校准结果。这种方式更具灵活性,是目前研究和应用最为广泛的形式。常见的后处理校准方法包括:Histogram Binning(将样本分为多个桶,每个桶内的样本Label均值作为该桶每个样本的校准结果)、Isotonic Regression(学习一个保序函数作为校准函数,它能够保证校准后的结果和基础模型预估值的排序能力是一致的)以及Scaling方法(基于某种参数化分布函数学习预估值到校准值的映射)等。近几年,也发展出上述方法的结合算法,并对校准技术进行了理论验证,本文不做过多展开,详细可参考:
https://github.com/huangsg1/uncertainty-calibration
阿里妈妈的校准技术采用的是后处理方式,主要考虑以下两点原因:1.我们希望在不改变已有基础预估模型的前提下,将校准技术解耦,做成灵活可插拔的形式;2.端到端的方法难以快速响应线上分布的剧烈变化,在阿里大促活动中线上环境的频繁变化是常态,更需要具备轻便灵敏的模型校准能力。
③ 后处理方法的关键技术问题
前面提到在实际环境中是无法观测到样本的真实点击概率的。但是我们可以采用近似的方法去逼近:针对观测样本,将各类特征相似的PV作为一个类簇,统计该类簇的整体点击率作为其中所有PV的真实点击概率(当类簇的数据量高于阈值时才认为是置信的);然后采用线性或非线性函数进行预估值和真实值的映射,该映射函数就构成了一种轻量级的校准函数。在这个过程中如何选择合理的类簇划分方式进行PV聚类就成为了问题的关键。经典的Isotonic Regression和Binning校准算法本质上是按预估值的大小进行样本划分,这种划分方式基于的假设是类簇划分精度的好坏与模型预估值的大小有关(或模型对于相近预估值大小的广告会具有相似的预估误差)。
在实践中我们发现校准维度越精细,越有利于产出准确的校准函数,但同时样本量也变的稀疏,当数据量不具有统计意义时,反而会降低校准函数的准确度。所以算法设计中需要进一步权衡校准维度选择和数据稀疏的问题,我们的算法演进之路也是不断解决这两个问题的进化之路。
校准指标
① Predict click over click (PCOC)
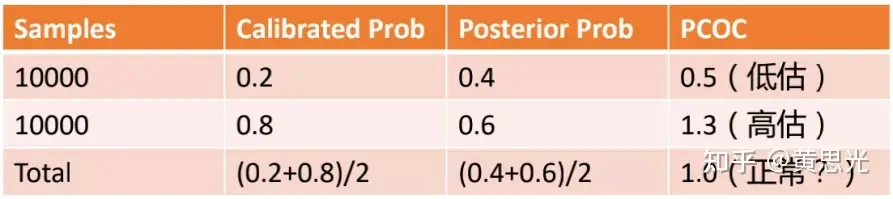
PCOC指标是校准之后的点击率与后验点击率(近似真实概率)的比值,越接近于1,意味着在绝对值上越准确,大于1为高估,小于1为低估,是一种常用的高低估评价指标。但是PCOC存在一定局限性,举个例子:2万个样本,其中1万个样本的预估概率是0.2,后验概率是0.4,计算出PCOC是0.2/0.4=0.5,是显著低估的,另1万个样本PCOC是0.8/0.6= 1.3,明显是高估的。所以校准效果并不好,但是样本放一起看,校准后概率是(0.2+0.8)/2=0.5,后验概率是(0.4+0.6)/2=0.5,整体PCOC是1.0,表现完全正常。所以单一PCOC指标不能表征样本各维度下的校准水平。
② Calibration-N(Cal-N)
针对PCOC问题,我们设计了一个新的指标Cal-N,将样本集合按照自定义规则划分出多个簇分别计算PCOC,并计算与标准1的偏差作为校准误差。相比PCOC,Cal-N显然能够更好的表征细粒度的校准水平。

③ Grouped Calibration-N(GC-N)
在广告领域中,通常会重点关注某一维度下的校准效果(如广告计划维度)。我们进一步提出了GC-N指标,能够在Cal-N基础上自定义各维度权重。
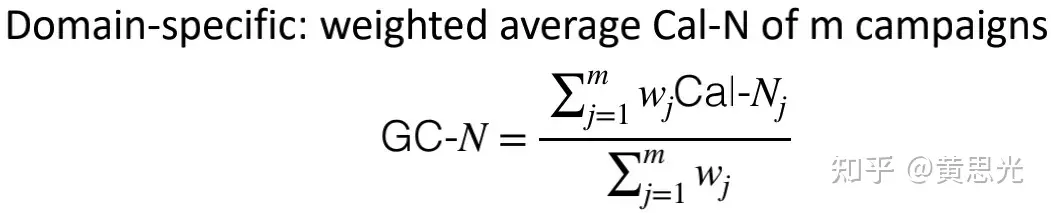
以上是对校准背景、概念、相关工作以及评价方法的简单介绍。
校准算法
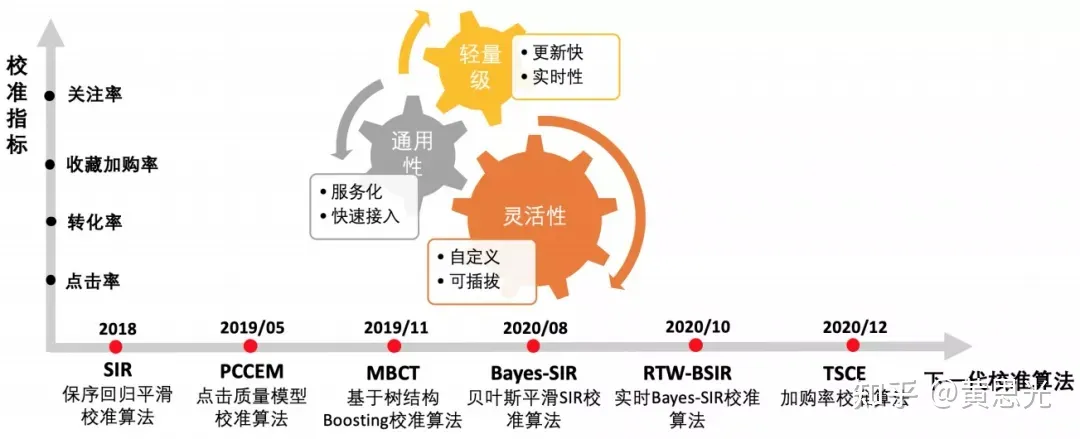
从18年以来我们开始在校准算法上不断创新,实现了对点击率、转化率、收藏加购率、关注率等各类预估指标的校准能力。整个迭代路线以实际业务需求为导向,以轻量级、通用性和灵活性为设计目标。接下来详细介绍我们提出的各类校准方法。
参考:

















 845
845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









