







在训练Lstm模型的时候可能会遇到这样的一个问题:特征的长度是不一样的,有的特征长度长,有的特征短,这可能会对我们训练模型造成困扰,本次分享如何解决这一问题:
如题所示,使用的正是 Mask 机制,所谓 Mask 机制就是我们在使用不等长特征的时候先将其补齐,在训练模型的时候再将这些参与补齐的数去掉,从而实现不等长特征的训练问题。
补齐的话使用 sequence 中的方法:
from keras_preprocessing import sequence
MaxLen=15
x = [[1], [2,5], [3,9,9,4,8]] # 特征
y = [2, 4, 6] # 标签
x=sequence.pad_sequences(x,maxlen=MaxLen,value=0)
print(x)
补齐的结果:
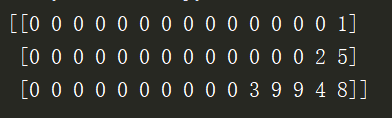
可以看到使用 sequence 的 pad_sequences() 方法后不等长的特征补齐了,补齐方式为不足我们所需要的特征长度的话将前面的值用我们给定的值补齐(我们需要的特征长度为“ MaxLen=15 ”,补齐的值为 0 )。
补齐之后,我们在训练的时候只要加上Mask机制将补齐的值过滤掉就可以了,整个过程如下:
import numpy as np
from keras.models import Sequential
from keras.layers.core import Dense, Activation, Dropout, Masking
from keras.layers.recurrent import LSTM
from keras_preprocessing import sequence
MaxLen=15
x = [[1], [2,5], [3,9,9,4,8]] # 特征
y = [2, 4, 6] # 标签
x=sequence.pad_sequences(x,maxlen=MaxLen,value=0)
x = np.array( x )
y_train = np.array( y )
x_train = np.reshape( x, (x.shape[0], x.shape[1], 1) ) # Lstm调用库函数必须要进行维度转换
model = Sequential()
model.add( Masking( mask_value=0, input_shape=(MaxLen,1) ) ) # Mask机制的使用
model.add( LSTM( 100, input_shape=(x_train.shape[1], x_train.shape[2]), return_sequences=True ) )
model.add( LSTM( 20, return_sequences=False ) )
model.add( Dropout( 0.2 ) )
model.add( Dense( 1 ) )
model.add( Activation( 'linear' ) )
model.compile( loss="mse", optimizer="rmsprop" )
model.fit( x_train, y_train, epochs=100, batch_size=1) # 参数依次为特征,标签,训练循环次数,小批量(一次放入训练的数据个数)
test=sequence.pad_sequences([[1.5]],maxlen=MaxLen,value=0)
test = np.reshape( test, (test.shape[0], test.shape[1], 1) )#维度转换
res = model.predict( test )
print(res)

















 71
71

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









