








1.模式和模式识别的概念
1.1. 广义定义
1)模式(pattern):
一个客观事物的描述,一个可用来仿效的完善的例子。
2)模式识别(pattern recognition) :
按哲学的定义是一个“外部信息到达感觉器官,并被转换成有意义的感觉经验”的过程。
例:识别热水、字迹等。
1.2. 狭义定义
1)模式:对某些感兴趣客体的定量的或结构的描述。模式类是具有某些共同特性的模式的集合。
2)模式识别:研究一种自动技术,依靠这种技术,计算机将自动地(或人尽量少地干涉)把待别识模式分配到各自的模式类中去。
注意:
狭义的“模式”概念——是对客体的描述,不论是待识别客体,还是已知的客体。
广义的“模式”概念——是指“用于效仿的完善例子”
1.3. 相关的计算机技术
1)目前的计算机建立在诺依曼体系基础之上。
1946年:美籍匈牙利数学家冯·诺依曼提出了关于计算机组成和工作方式的基本设想:数字计算机的数制采用二进制;计算机按照程序顺序执行,即“程序存储”的概念。
1949年:研制出第一台冯·诺依曼式计算机 。
1956年:第一次人工智能(artificial intelligence)研讨会在美国召开。
2)第五代人工智能型计算机
本质区别:主要功能将从信息处理上升为知识处理(学习、联想、推理、解释问题),使计算机具有人类的某些智能。研制工作从80年代开始,目前尚未形成一致结论 。
几种可能的发展方向:
神经网络计算机--模拟人的大脑思维。
生物计算机--运用生物工程技术、蛋白分子作芯片。
光计算机--用光作为信息载体,通过对光的处理来完成对信息的处理。
1.4. 研究和发展模式识别的目的
提高计算机的感知能力,从而大大开拓计算机的应用。
2.模式识别系统
2.1 简例:建立感性认识
以癌细胞识别为例,了解机器识别的全过程。
2.1. 信息输入与数据获取
将显微细胞图像转换成数字化细胞图像,是计算机分析的原始数据基础。
灰度数字图像的像素值反映光密度的大小。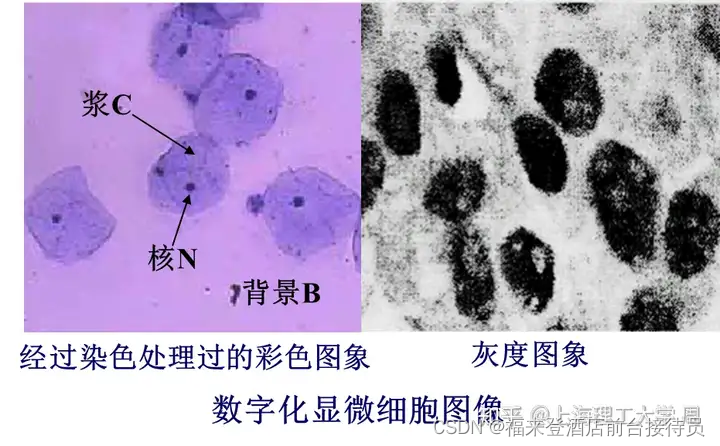
2.2数字化细胞图像的预处理与区域划分
预处理的目的:
(1)去除在数据获取时引入的噪声与干扰。
(2)去除所有夹杂在背景上的次要图像,突出主要的待识别
的细胞图像。
例:平滑、图像增强等数字图像处理技术。
区域划分的目的:
找出边界,划分出三个区域,为特征抽取做准备。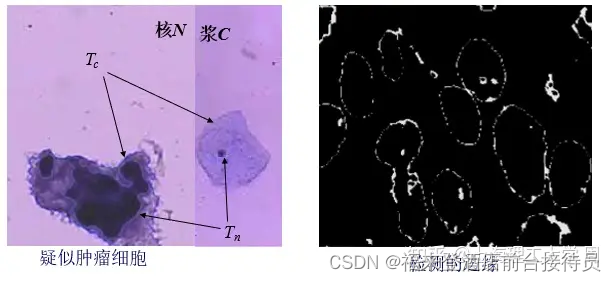
设灰度阈值为Tc和Tn,图像中某像素的灰度值为Ti,则:
Ti ≥ Tn的点属于胞核区;
Ti < Tc的点属于背景区;
Tc≤Ti<Tn的点属于胞浆区;
2.3细胞特征的抽取、选择和提取
目的:为了建立各种特征的数学模型,以用于分类。
① 抽取特征 :原始采集数据,第一手资料,特征数据量大。是特征选择和提取的依据。
例:对一个细胞抽取33个特征 ,建立一个33维的空间X,每个细胞可通过一个33维随机向量表示,记为:

即把一个物理实体“细胞”变成了一个数学模型“33维随机向量”,也即33维空间中的一点。
② 特征选择:在原始特征基础上选择一些主要特征作为判别用的特征。
③ 特征提取:采用某种变换技术,得出数目上比原来少的综合特征作为分类用,称为特征维数压缩,习惯上亦称特征提取。
例:有五个特征 x1,x2,x3,x4,x5,以及变换f(·)、g(·) ,则可有:

结果:
X 空间中的向量

变成 Y 空间的向量
![]()
即:特征向量由5维降为2维。
2.4. 判别分类
(1)气管细胞97个,识别错误率为7.2% 。
(2)肺细胞166个,识别错误率为18% 。
判别的好坏通过错误率给出,不同错误的代价和风险不同。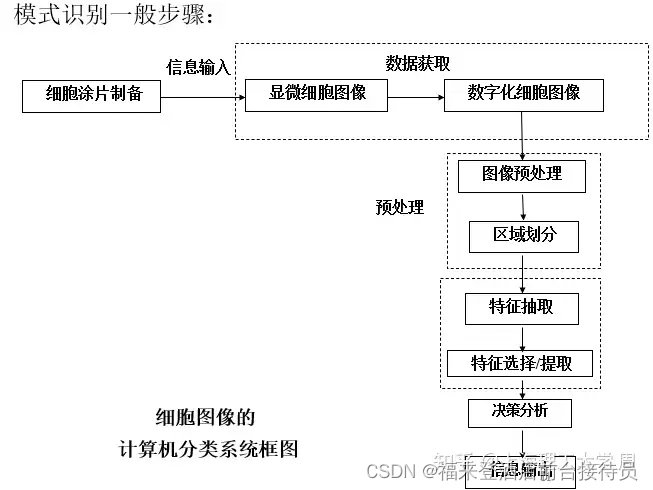
2.5模式识别系统组成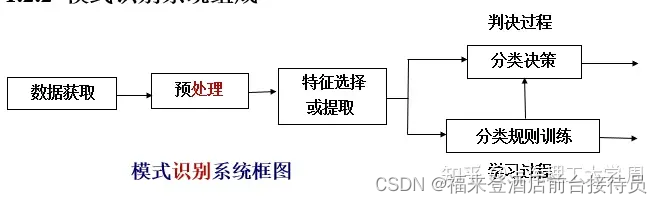
注意:“处理”与“识别”两个概念的区别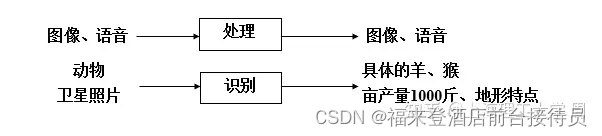
处理:输入与输出是同样的对象,性质不变。
识别:输入的是事物,输出的是对它的分类、理解和描述。
3.模式识别概况
3.1模试识别发展简介
1929年G. Tauschek发明阅读机;
30年代 Fisher提出统计分类理论;
50年代Noam Chemsky提出形式语言理论;
60年代L.A.Zadeh提出了模糊集理论,较广泛地应用;
80年代Hopfield提出神经元网络模型理论;
90年代以后小样本学习理论、支持向量机。
基本上:五十、六十年代开始迅速发展,
七十年代初奠定理论基础 。
比较成熟的:四大分支
3.1模式识别分类
1.从理论上分类
① 统计模式识别
以模式集在特征空间中分布的类概率密度函数为基础,对总体特征进行研究。包括判决函数法和聚类 分析法。
②句法模式识别(结构模式识别)
根据识别对象的结构特征,以形式语言理论为基础的一种模式识别方法 。
把复杂模式分化为较简单的子模式乃至基元,各层次之间的关系通过“结构法”来描述,相当于语言中的语法。用小而简单的基元与语法规则来描述大而复杂的模式。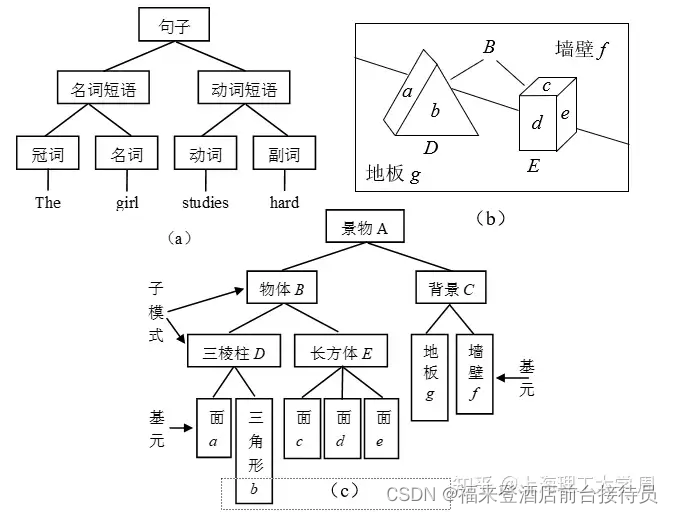
③ 模糊模式识别
以隶属度 为基础,运用模糊数学中的“关系”概念和运算进行分类。隶属度反映的是某一元素属于某集合的程度。
例:元素 a、b、c对正方形的隶属度: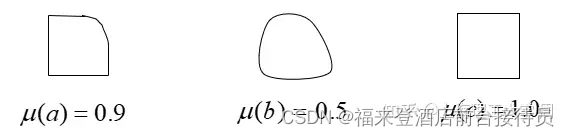
说明:a比b更像正方形。
④神经网络模式识别法
以人工神经元为基础,模拟人脑神经细胞的工作特点。对脑部工作的生理机制进行模拟,实现形象思维的模拟。
对比:基于知识的逻辑性推理:对逻辑思维的模拟。
3.2从实现方法来分
① 监督(有人管理)分类:利用判别函数进行分类判别。需要有足够的先验知识。
② 非监督(无人管理)分类:用于没有先验知识的情况下,采用聚类分析的方法。
4模式识别的应用
例1.1 不停车收费系统。交通部的收费标准:按吨位划分 收费站:按车型收费(间接按车辆设计载重量收费)关键:车型的自动分类。几种主要技术:
1)提取车辆外形几何参数进行处理分析,实现分类。
如视频检测方法、红外检测方法。
2)测量车辆的其他物理参数(噪声、振动、压重等)实现分类。
如动态称重、电磁感应等。
3)直接识别车辆身份的方法实现分类。
如电子标签、视频牌照识别等。
例1.2 生物识别技术。
根据每个人独有的可以采样和测量的生物学特征(生理特征)和行为学特征进行身份识别的技术。
1)指纹识别:最早、最成熟的识别技术。
2)掌纹识别:研究纹线上某几个点的幅值(灰度值)、线长
与线所对应的角之比等特征。
3)人脸识别:
4)虹膜识别:
5 )签名识别
6)击键分析
第2章 聚类分析
2.1 距离聚类的概念
2.2 相似性测度和聚类准则
2.3 基于距离阈值的聚类算法
2.4 层次聚类法
2.5 动态聚类法
2.6 聚类结果的评价
1. 概念:“物以类聚”
聚类分析:根据模式之间的相似性对模式进行分类,是一种非监督分类方法。
2.相似性的含义
有n个特征值则组成n维向量
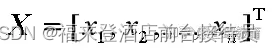
,称为该样本的特征向量。它相当于特征空间中的一个点,以特征空间中,点间的距离函数作为模式相似性的测量,以“距离”作为模式分类的依据,距离越小,越“相似”。
注意:聚类分析是否有效,与模式特征向量的分布形式有很大关系。选取的特征向量是否合适非常关键。例:酱油与可乐。
2.2.1 相似性测度
相似性测度:衡量模式之间相似性的一种尺度。如:距离。
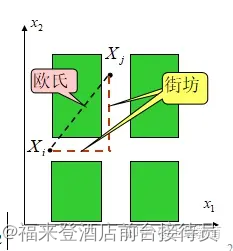
1. 欧氏距离(Euclid,欧几里德) ——简称距离
设X1、X2为两个n维模式样本,
注意:
1)各特征向量对应的维上应当是相同的物理量;
注意物理量的单位。
某些维上物理量采用的单位发生变化,会导致对同样的点集出现不同聚类结果的现象。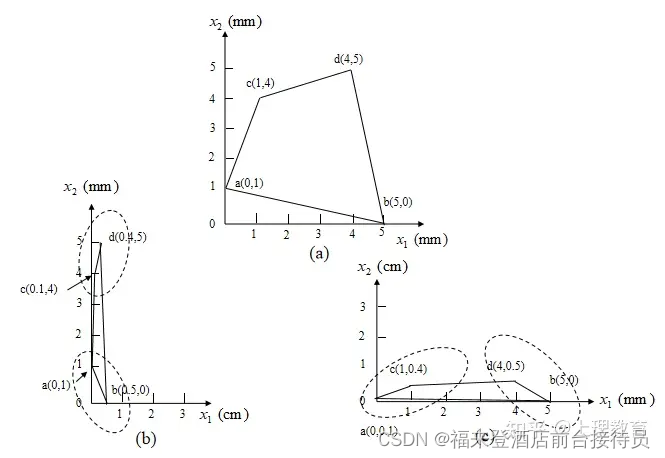
2)解决方法:使特征数据标准化,使其与变量的单位无关。
2. 马氏距离(Maharanobis)
平方表达式:
![]()
式中,X:模式向量;
M:均值向量;
C:该类模式总体的协方差矩阵。
对n维向量:

示的概念是各分量上模式样本到均值的距离,也就是在各维上模式的分散情况。
优点:排除了模式样本之间的相关影响 。当C = I 时,马氏距离为欧氏距离。
3. 明氏距离( Minkowaki
n维模式样本向量Xi、Xj间的明氏距离表示为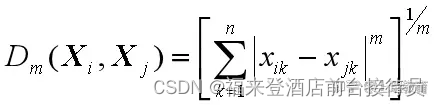
式中, xik、xjk分别表示Xi和Xj的第k个分量。
当m=2时,明氏距离为欧氏距离。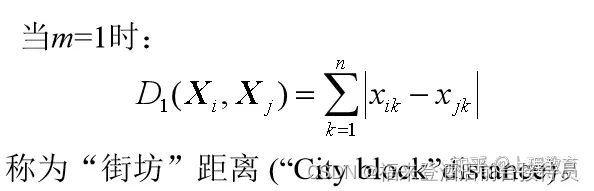
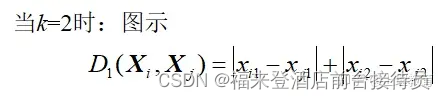
4.汉明(Hamming)距离
设Xi、Xj 为n维二值(1或-1)模式样本向量,则
汉明距离: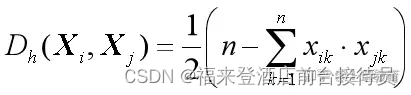
式中, xik、xjk分别表示Xi和Xj的第k个分量。
两个模式向量的各分量取值均不同:Dh(Xi, Xj)=n;
全相同: Dh(Xi, Xj)=0
5.角度相似性函数
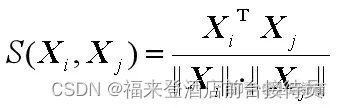
是模式向量Xi,Xj之间夹角的余弦。
6.Tanimoto测度
用于0,1二值特征的情况,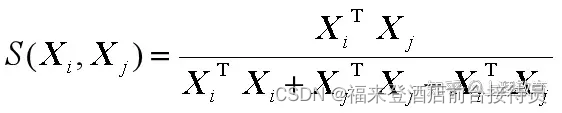

相似性测度函数的共同点都涉及到把两个相比较的向量Xi,Xj的分量值组合起来,但怎样组合并无普遍有效的方法,对具体的模式分类,需视情况作适当选择。
2.2.2 聚类准则
聚类准则:根据相似性测度确定的,衡量模式之间是否相似的标准。即把不同模式聚为一类还是归为不同类的准则。
确定聚类准则的两种方式:
1. 阈值准则:根据规定的距离阈值进行分类的准则。
2. 函数准则:利用聚类准则函数进行分类的准则。
聚类准则函数:在聚类分析中,表示模式类间相似或差异性
的函数。
它应是模式样本集{X }和模式类别
![]()
的函数。可使聚类分析转化为寻找准则函数极值的最优化问题。一种常用的指标是误差平方之和。
聚类准则函数: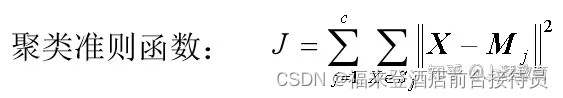
式中:c为聚类类别的数目,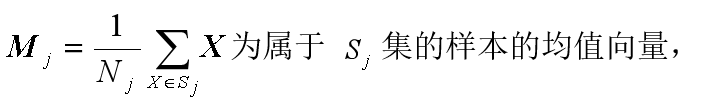

J代表了分属于c个聚类类别的全部模式样本与其相应类别模式均值之间的误差平方和。
适用范围:
适用于各类样本密集且数目相差不多,而不同类间的样本又明显分开的情况。
例1
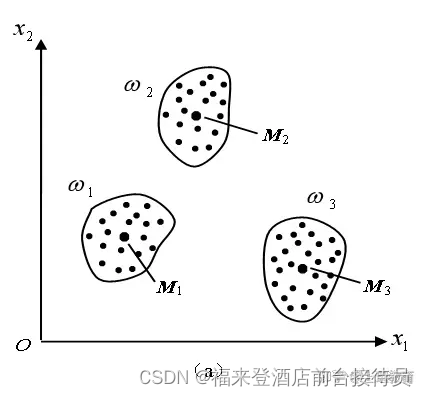
类内误差平方和很
小,类间距离很远。
可得到最好的结果。
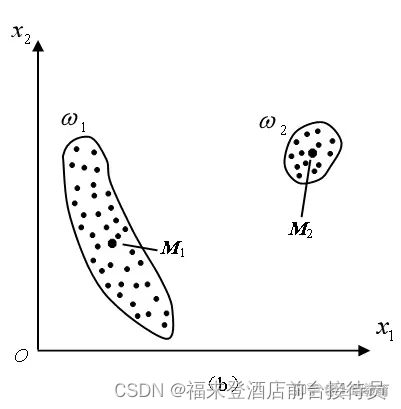
类长轴两端距离中心很远,J值较大,结果不易令人满意。
例2:另一种情况
有时可能把样本数目多的一类分拆为二,造成错误聚类。
原因:这样分开,J值会更小。
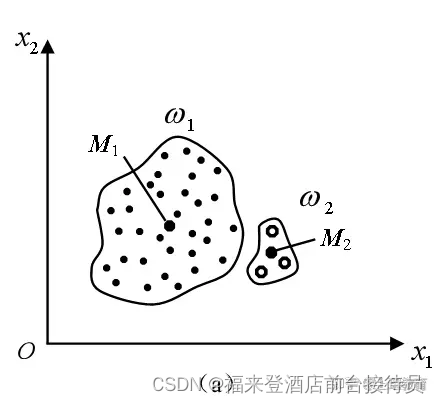
正确分类
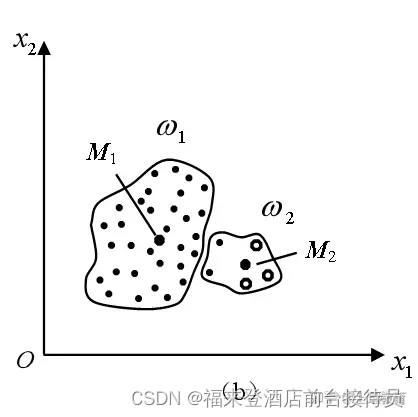
错误分类
2.3 基于距离阈值的聚类算法
2.3.1 近邻聚类法
2. 算法描述
① 任取样本Xi 作为第一个聚类中心的初始值,如令Z1 = X1

3. 算法特点
1)局限性:很大程度上依赖于第一个聚类中心的位置选择、待
分类模式样本的排列次序、距离阈值T的大小以及样本分布
的几何性质等。
2)优点:计算简单。(一种虽粗糙但快速的方法)
4.算法讨论
用先验知识指导阈值T 和起始点Z1的选择,可获得合理的聚类结果。否则只能选择不同的初值重复试探,并对聚类结果进行验算,根据一定的评价标准,得出合理的聚类结果。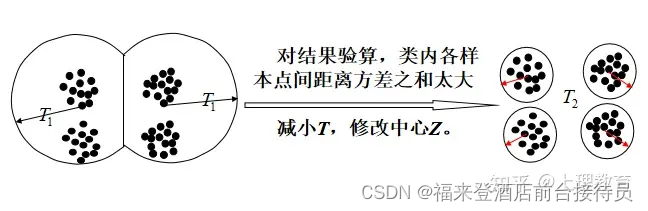
2.3.2 最大最小距离算法(小中取大距离算法 )
2. 算法描述
① 选任意一模式样本做为第一聚类中心Z1。
② 选择离Z1距离最远的样本作为第二聚类中心Z2。
③ 逐个计算各模式样本与已确定的所有聚类中心之间的距离,并选出其中的最小距离。例当聚类中心数k=2时,计算
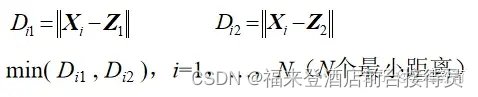

例k =2时

⑤ 重复步骤③④,直到没有新的聚类中心出现为止。
思路总结:
先找中心后分类;关键:怎样开新类,聚类中心如何定。
为使聚类中心更有代表性,可取各类的样本均值作为聚类中心。
例2.1 对图示模式样本用最大最小距离算法进行聚类分析。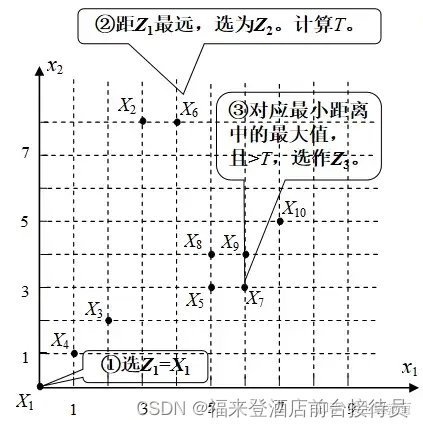

编者能力有限,如有错误欢迎留言交流
编者的其他专栏:

关注编者了解更多
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









