








实验汇总 1——4: 1. C均值聚类 2. 感知准则函数分类器 3.贝叶斯分类器 4. PCA特征提取
实验1 C均值聚类
C均值聚类(更常用的叫法是K均值算法,K-means clustering)是经典的非监督数据处理方法。实验目的在于加深学生对C均值聚类原理的理解、掌握的算法的实现过程,体会其在模式识别中的作用。
1实验原理
设定 C个类别并选取 C个初始聚类中心,按最小距离原则将各样本分配到 C类中的某一类;之后不断地计算各类中心并调整各样本的类别,最终使各样本到其所属类别中心的距离平方之和最小。
2实验内容
处理男生和女生的身高、体重数据,分别保存在文件FEMALE.TXT、MALE.TXT中,利用C均值方法进行聚类分析。
3实验要求
1) 同时采用身高和体重数据作为特征,类别数设为2,利用C均值聚类方法对数据进行聚类,并将聚类结果表示在二维平面上;尝试不同的初始值,观察聚类结果是否发生变化。
matlab代码:
clc;clear;close all
F = importdata('FEMALE.TXT')'
M = importdata('MALE.TXT')'
%
figure(2); hold on;
plot(F(1,:),F(2,:),'bo',M(1,:),M(2,:),'r*');
data = [F M];
% data = importdata('cmeans_data.txt');
% data = data';
figure(1);
plot(data(1,:),data(2,:),'b+');
[d,N] = size(data);
P = randperm(N,2);
m1 = data(:,P(1));
m2 = data(:,P(2));
for k = 1:100
S1=[];
S2=[];
for i=1:N
cur = data(:,i);
d1 = (cur - m1)'*(cur - m1);
d2 = (cur - m2)'*(cur - m2);
if d1<d2
S1 = [S1, cur];
else
S2 = [S2, cur];
end
end
plot(S1(1,:),S1(2,:),'bo',S2(1,:),S2(2,:),'r*');
m1_new = mean(S1,2);
m2_new = mean(S2,2);
if (m1_new == m1) & (m2_new == m2)
s=sprintf('迭代%d次,聚类收敛;两类样本数量分别是%d、%d',k-1,size(S1,2),size(S2,2));
uiwait(msgbox(s,'提示','modal'));
break;
else
m1 = m1_new;
m2 = m2_new;
end
end
结果:迭代6次,聚类收敛,两类样本数目分别是59,41.
图表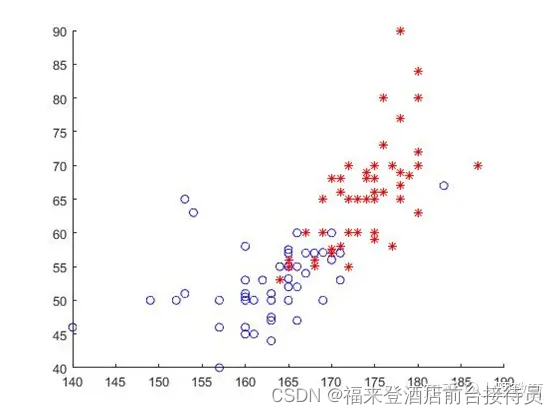
2)改变类别数,分别进行两类、三类、四类、五类聚类,画出聚类指标与类别数之间的关系曲线,探讨是否可以确定出合理的类别数目。
实验2 感知准则函数分类器
进一步了解分类器的设计概念,理解并掌握感知准则函数分类器的原理及方法,并用于实际的数据分类。
1实验原理
利用梯度下降法求解感知准则函数的解向量。
构造准则函数
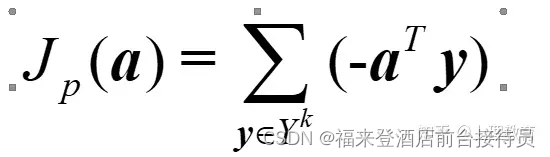
式中Yk是错分样本集合。
解向量求解的迭代形式
2实验内容
已知有两类数据w1和w2,w1中数据点的坐标对应一一如下:x1 =
0.2331 1.5207 0.6499 0.7757 1.0524 1.1974
0.2908 0.2518 0.6682 0.5622 0.9023 0.1333
-0.5431 0.9407 -0.2126 0.0507 -0.0810 0.7315
0.3345 1.0650 -0.0247 0.1043 0.3122 0.6655
0.5838 1.1653 1.2653 0.8137 -0.3399 0.5152
0.7226 -0.2015 0.4070 -0.1717 -1.0573 -0.2099
y1=
2.3385 2.1946 1.6730 1.6365 1.7844 2.0155
2.0681 2.1213 2.4797 1.5118 1.9692 1.8340
1.8704 2.2948 1.7714 2.3939 1.5648 1.9329
2.2027 2.4568 1.7523 1.6991 2.4883 1.7259
2.0466 2.0226 2.3757 1.7987 2.0828 2.0798
1.9449 2.3801 2.2373 2.1614 1.9235 2.2604
z1=
0.5338 0.8514 1.0831 0.4164 1.1176 0.5536
0.6071 0.4439 0.4928 0.5901 1.0927 1.0756
1.0072 0.4272 0.4353 0.9869 0.4841 1.0992
1.0299 0.7127 1.0124 0.4576 0.8544 1.1275
0.7705 0.4129 1.0085 0.7676 0.8418 0.8784
0.9751 0.7840 0.4158 1.0315 0.7533 0.9548
w2数据点的对应的三维坐标为
x2 =
1.4010 1.2301 2.0814 1.1655 1.3740 1.1829
1.7632 1.9739 2.4152 2.5890 2.8472 1.9539
1.2500 1.2864 1.2614 2.0071 2.1831 1.7909
1.3322 1.1466 1.7087 1.5920 2.9353 1.4664
2.9313 1.8349 1.8340 2.5096 2.7198 2.3148
2.0353 2.6030 1.2327 2.1465 1.5673 2.9414
y2 =
1.0298 0.9611 0.9154 1.4901 0.8200 0.9399
1.1405 1.0678 0.8050 1.2889 1.4601 1.4334
0.7091 1.2942 1.3744 0.9387 1.2266 1.1833
0.8798 0.5592 0.5150 0.9983 0.9120 0.7126
1.2833 1.1029 1.2680 0.7140 1.2446 1.3392
1.1808 0.5503 1.4708 1.1435 0.7679 1.1288
z2 =
0.6210 1.3656 0.5498 0.6708 0.8932 1.4342
0.9508 0.7324 0.5784 1.4943 1.0915 0.7644
1.2159 1.3049 1.1408 0.9398 0.6197 0.6603
1.3928 1.4084 0.6909 0.8400 0.5381 1.3729
0.7731 0.7319 1.3439 0.8142 0.9586 0.7379
0.75480.73930.67390.86511.36991.1458
3实验要求
代码:
clc;clear;close all
x1 =[
0.2331 1.5207 0.6499 0.7757 1.0524 1.1974
0.2908 0.2518 0.6682 0.5622 0.9023 0.1333
-0.5431 0.9407 -0.2126 0.0507 -0.0810 0.7315
0.3345 1.0650 -0.0247 0.1043 0.3122 0.6655
0.5838 1.1653 1.2653 0.8137 -0.3399 0.5152
0.7226 -0.2015 0.4070 -0.1717 -1.0573 -0.2099];
y1=[
2.3385 2.1946 1.6730 1.6365 1.7844 2.0155
2.0681 2.1213 2.4797 1.5118 1.9692 1.8340
1.8704 2.2948 1.7714 2.3939 1.5648 1.9329
2.2027 2.4568 1.7523 1.6991 2.4883 1.7259
2.0466 2.0226 2.3757 1.7987 2.0828 2.0798
1.9449 2.3801 2.2373 2.1614 1.9235 2.2604];
z1=[
0.5338 0.8514 1.0831 0.4164 1.1176 0.5536
0.6071 0.4439 0.4928 0.5901 1.0927 1.0756
1.0072 0.4272 0.4353 0.9869 0.4841 1.0992
1.0299 0.7127 1.0124 0.4576 0.8544 1.1275
0.7705 0.4129 1.0085 0.7676 0.8418 0.8784
0.9751 0.7840 0.4158 1.0315 0.7533 0.9548];
x2 =[
1.4010 1.2301 2.0814 1.1655 1.3740 1.1829
1.7632 1.9739 2.4152 2.5890 2.8472 1.9539
1.2500 1.2864 1.2614 2.0071 2.1831 1.7909
1.3322 1.1466 1.7087 1.5920 2.9353 1.4664
2.9313 1.8349 1.8340 2.5096 2.7198 2.3148
2.0353 2.6030 1.2327 2.1465 1.5673 2.9414];
y2 =[
1.0298 0.9611 0.9154 1.4901 0.8200 0.9399
1.1405 1.0678 0.8050 1.2889 1.4601 1.4334
0.7091 1.2942 1.3744 0.9387 1.2266 1.1833
0.8798 0.5592 0.5150 0.9983 0.9120 0.7126
1.2833 1.1029 1.2680 0.7140 1.2446 1.3392
1.1808 0.5503 1.4708 1.1435 0.7679 1.1288];
z2 =[
0.6210 1.3656 0.5498 0.6708 0.8932 1.4342
0.9508 0.7324 0.5784 1.4943 1.0915 0.7644
1.2159 1.3049 1.1408 0.9398 0.6197 0.6603
1.3928 1.4084 0.6909 0.8400 0.5381 1.3729
0.7731 0.7319 1.3439 0.8142 0.9586 0.7379
0.7548 0.7393 0.6739 0.8651 1.3699 1.1458];
xx1 = [x1(:) y1(:) z1(:)]';
xx2 = [x2(:) y2(:) z2(:)]';
m1=mean(xx1,2);
m2=mean(xx2,2);
s1=zeros(3,3);
for i=1:size(xx1,2)
s1 = s1 + (xx1(:,i)-m1)*(xx1(:,i)-m1)';
end
s2=zeros(3,3);
for i=1:size(xx2,2)
s2 = s2 + (xx2(:,i)-m2)*(xx2(:,i)-m2)';
end
sw=s1+s2;
w=inv(sw)*(m1-m2);
w=w/sqrt(w'*w)
g1 = w'*xx1;;
g2 = w'*xx2;;
r1=ones(size(g1));
r2=ones(size(g2));
hold on
plot(g1,r1,'b*')
plot(g2,r2,'r+')
t =[1 1.5 0.6; 1.2 1.0 0.55; 2.0 0.9 0.68; 1.2 1.5 0.89;0.23 2.33 1.43];
yt=w'*t';
rt1=1.1*ones(size(yt));
w0=w'*(m1+m2)/2;
plot(yt(find(yt>w0)),rt1(yt>w0),'b+')
plot(yt(find(yt<w0)),rt1(yt<w0),'r*')
a=axis;
a(3)= 0.99;
回答:
1) 求出解向量,验证用其能否将原始样本进行类别区分。
解向量w =
[-0.3612
0.9071
-0.2163]
可以对样本进行正确分类.
根据上述的结果并判断(1,1.5,0.6)(1.2,1.0,0.55),(2.0,0.9,0.68),(1.2,1.5,0.89),(0.23,2.33,1.43),属于哪个类别。
第一类: (1,1.5,0.6), (1.2,1.0,0.55), (1.2,1.5,0.89)
第二类: (2.0,0.9,0.68), (2.0,0.9,0.68)
2) 图示分类结果。
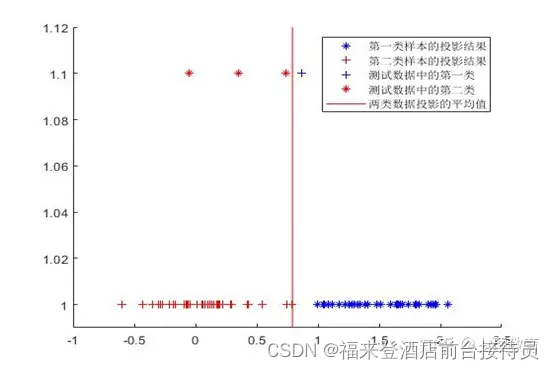
实验3 贝叶斯分类器
本实验旨在让同学对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识,理解二类分类器的设计原理。
1实验原理
最小风险贝叶斯决策可按下列步骤进行:
(1)据贝叶斯公式计算出后验概率:
(2)利用计算出的后验概率及决策表
(3)对(2)中得到的a个条件风险值进行比较,找出使其条件风险最小的决策就是最小风险贝叶斯决策。
2实验内容
假定某个局部区域细胞识别中正常(w1)和非正常(w2)两类先验概率分别为
正常状态:P(w1)=0.9;异常状态:P(w2)=0.1。
现有一系列待观察的细胞,其观察值为x:
-3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531
-2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752
-3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682
-1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532
已知类条件概率密度曲线如下图: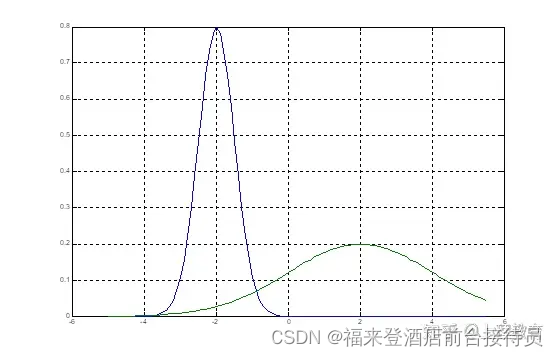

3 实验要求
用matlab完成分类器的设计,要求程序相应语句有说明文字。
clc;clear;close all
x=[-3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531
-2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752
-3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682
-1.5799 -1.4885 0.7431 -0.4221 -1.1186 4.2532];
pw1=0.9; pw2=0.1;
e1=-2; a1=0.5;
e2=2; a2=2;
m=numel(x); %得到待测细胞个数
pw1_x=zeros(1,m); %存放对w1的后验概率矩阵
pw2_x=zeros(1,m); %存放对w2的后验概率矩阵
results=zeros(1,m); %存放比较结果矩阵
for i = 1:m
%计算在w1下的后验概率
pw1_x(i)=(pw1*normpdf(x(i),e1,a1))/(pw1*normpdf(x(i),e1,a1)+pw2*normpdf(x(i),e2,a2)) ;
%计算在w2下的后验概率
pw2_x(i)=(pw2*normpdf(x(i),e2,a2))/(pw1*normpdf(x(i),e1,a1)+pw2*normpdf(x(i),e2,a2)) ;
end
for i = 1:m
if pw1_x(i)>pw2_x(i) %比较两类后验概率
result(i)=0; %正常细胞
else
result(i)=1; %异常细胞
end
end
a=[-5:0.05:5]; %取样本点以画图
n=numel(a);
pw1_plot=zeros(1,n);
pw2_plot=zeros(1,n);
for j=1:n
pw1_plot(j)=(pw1*normpdf(a(j),e1,a1))/(pw1*normpdf(a(j),e1,a1)+pw2*normpdf(a(j),e2,a2));
%计算每个样本点对w1的后验概率以画图
pw2_plot(j)=(pw2*normpdf(a(j),e2,a2))/(pw1*normpdf(a(j),e1,a1)+pw2*normpdf(a(j),e2,a2));
end
figure(1);
hold on %holds the current plot and all axis properties so that subsequent graphing commands add to the existing graph.
plot(a,pw1_plot,'c+',a,pw2_plot,'r-.');
for k=1:m
if result(k)==0
plot(x(k),-0.1,'bp'); %正常细胞用五角星表示
else
plot(x(k),-0.1,'r*'); %异常细胞用*表示
end
end
% plot(a,normpdf(a,e1,a1))
% plot(a,normpdf(a,e2,a2))
legend('正常细胞后验概率曲线','异常细胞后验概率曲线','正常细胞','异常细胞');
xlabel('样本细胞的观察值');
ylabel('后验概率');
title('后验概率分布曲线');
grid on
2) 根据例子画出后验概率的分布曲线以及分类的结果示意图。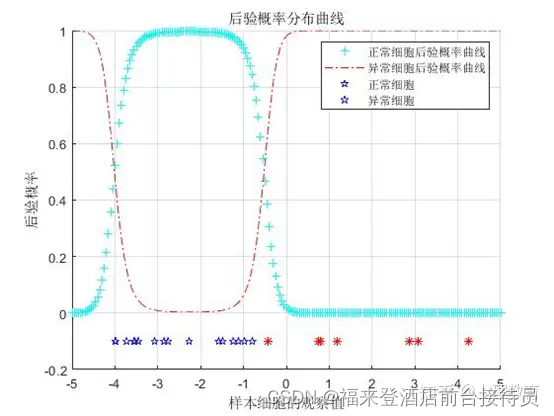
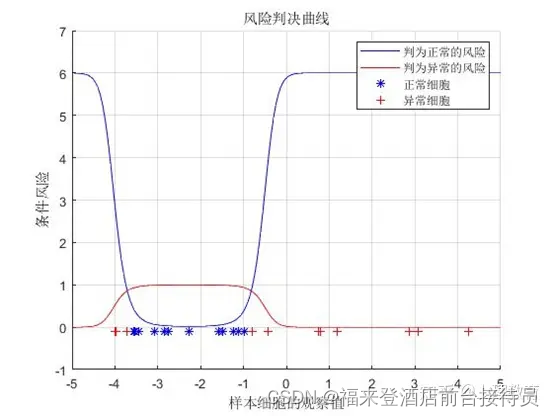
3)1) 如果是最小风险贝叶斯决策,决策表如下:
最小风险贝叶斯决策表:
| 状态 决策 | ||
| α1 | 0 | 6 |
| α2 | 1 | 0 |
请重新设计程序,画出相应的后验概率的分布曲线和分类结果,并比较两个结果。
matlab代码:
clc;clear;close(figure(2));
x=[-3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531
-2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752
-3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682
-1.5799 -1.4885 0.7431 -0.4221 -1.1186 4.2532];
pw1=0.9; pw2=0.1;
m=numel(x); %得到待测细胞个数
R1_x=zeros(1,m); %存放把样本X判为正常细胞所造成的整体损失
R2_x=zeros(1,m); %存放把样本X判为异常细胞所造成的整体损失
result=zeros(1,m); %存放比较结果
e1=-2;a1=0.5;
e2=2; a2=2;
%类条件概率分布px_w1:(-2,0.25) px_w2(2,4)
r11=0;r12=6;
r21=1;r22=0;
%风险决策表
% for i=1:m
% %计算两类风险值
% R1_x(i)=r11*pw1*normpdf(x(i),e1,a1)/(pw1*normpdf(x(i),e1,a1)+pw2*normpdf(x(i),e2,a2))+r12*pw2*normpdf(x(i),e2,a2)/(pw1*normpdf(x(i),e1,a1)+pw2*normpdf(x(i),e2,a2));
% R2_x(i)=r21*pw1*normpdf(x(i),e1,a1)/(pw1*normpdf(x(i),e1,a1)+pw2*normpdf(x(i),e2,a2))+r22*pw2*normpdf(x(i),e2,a2)/(pw1*normpdf(x(i),e1,a1)+pw2*normpdf(x(i),e2,a2));
% end
R1_x=r11*pw1*normpdf(x,e1,a1)./(pw1*normpdf(x,e1,a1)+pw2*normpdf(x,e2,a2))+r12*pw2*normpdf(x,e2,a2)./(pw1*normpdf(x,e1,a1)+pw2*normpdf(x,e2,a2));
R2_x=r21*pw1*normpdf(x,e1,a1)./(pw1*normpdf(x,e1,a1)+pw2*normpdf(x,e2,a2))+r22*pw2*normpdf(x,e2,a2)./(pw1*normpdf(x,e1,a1)+pw2*normpdf(x,e2,a2));
result(R2_x<R1_x)=1; %第二类比第一类风险小,判为异常细胞,用1表示
a=[-5:0.05:5]; %取样本点以画图
% n=numel(a);
% R1_plot=zeros(1,n);
% R2_plot=zeros(1,n);
% for j=1:n
% R1_plot(j)=r11*pw1*normpdf(a(j),e1,a1)/(pw1*normpdf(a(j),e1,a1)+pw2*normpdf(a(j),e2,a2))+r12*pw2*normpdf(a(j),e2,a2)/(pw1*normpdf(a(j),e1,a1)+pw2*normpdf(a(j),e2,a2));
% R2_plot(j)=r21*pw1*normpdf(a(j),e1,a1)/(pw1*normpdf(a(j),e1,a1)+pw2*normpdf(a(j),e2,a2))+r22*pw2*normpdf(a(j),e2,a2)/(pw1*normpdf(a(j),e1,a1)+pw2*normpdf(a(j),e2,a2));
% %计算各样本点的风险以画图
% end
R1_plot=r11*pw1*normpdf(a,e1,a1)./(pw1*normpdf(a,e1,a1)+pw2*normpdf(a,e2,a2))+r12*pw2*normpdf(a,e2,a2)./(pw1*normpdf(a,e1,a1)+pw2*normpdf(a,e2,a2));
R2_plot=r21*pw1*normpdf(a,e1,a1)./(pw1*normpdf(a,e1,a1)+pw2*normpdf(a,e2,a2))+r22*pw2*normpdf(a,e2,a2)./(pw1*normpdf(a,e1,a1)+pw2*normpdf(a,e2,a2));
figure(2);
hold on
plot(a,R1_plot,'b',a,R2_plot,'r');
x0=x(result==0);
x1=x(result~=0);
vx0=ones(size(x0))*(-0.1);
vx1=ones(size(x1))*(-0.1);
plot(x0,vx0,'b*'); %正常细胞用五角星表示
plot(x1,vx1,'r+'); %异常细胞用*表示
axis([-5 5 -1 7]);
legend('判为正常的风险','判为异常的风险','正常细胞','异常细胞');
xlabel('样本细胞的观察值');
ylabel('条件风险');
title('风险判决曲线');
grid on
return
实验4PCA特征提取
主成分分析(PCA)是常用的特征降维方法。实验目的在于加深学生对PCA原理的理解,通过实际的数据处理掌握PCA的处理流程、验证PCA的性质,体会其在模式识别中的作用。
1实验原理
PCA是寻求方差最大的投影方向对原始数据进行变换,得到一组相互之间不相关的新特征。投影方向可取样本数据协方差矩阵的特征向量,各特征向量的重要程度利用其对应的特征值来衡量。
变换矩阵W由样本协方差矩阵的特征向量构成。可更改构成变换矩阵的向量个数,从而得到不同数量的特征,实现特征降维。
2实验内容
利用Iris数据集进行实验。该数据集以鸢尾花的特征作为数据来源,由3种不同类型的鸢尾花的50个样本数据构成。
样本特征(属性):
Sepal.Length(花萼长度),单位是cm;
Sepal.Width(花萼宽度),单位是cm;
Petal.Length(花瓣长度),单位是cm;
Petal.Width(花瓣宽度),单位是cm;
种类:Iris Setosa(山鸢尾)、Iris Versicolour(杂色鸢尾)、Iris Virginica(维吉尼亚鸢尾)。
鸢尾花数据的特征维数是4,利用PCA进行降维、结合最近邻法完成分类。
3实验要求
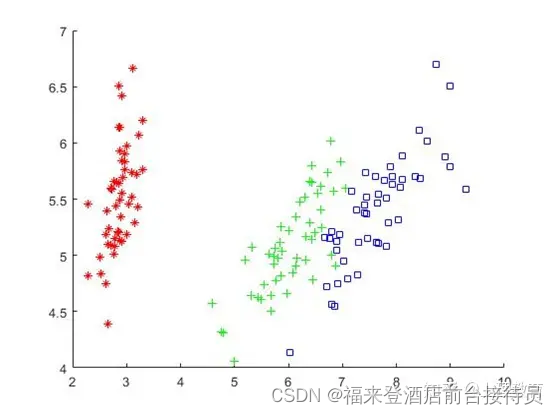
1) 利用最近邻法针对Iris原始特征进行分类;
三类模式,四维特征
代码:clc;clear;close all
clc;clear
load Iris;
X = Iris(2:5,:);
S=cov(X');
[V,D]=eig(S);
分类结果:
2) 利用PCA进行数据降维、再用最近邻法分类;
代码:
%ÆäËûʵÏÖ·½Ê½
% % % X_D = X - repmat(mean(X,2),1,size(X,2));
% % % [V1,D1]=eig(X_D*X_D');
% % %
% % % %ÖÐÐÄ»¯ºóµÄÑù±¾Êý¾Ý
% % % [UU,SS,VV] = svd(X_D);
lamda = diag(D);
lamda = flipud(lamda);
V=fliplr(V);
W=V(:,1:4);
y = W'*X;
Xr = W*y;
Sy=cov(y');
figure(1);hold on;
plot(y(1,1:50), y(2,1:50),'r*');
plot(y(1,51:100), y(2,51:100),'g+');
plot(y(1,101:150), y(2,101:150),'bs');
结果:
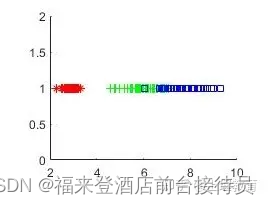
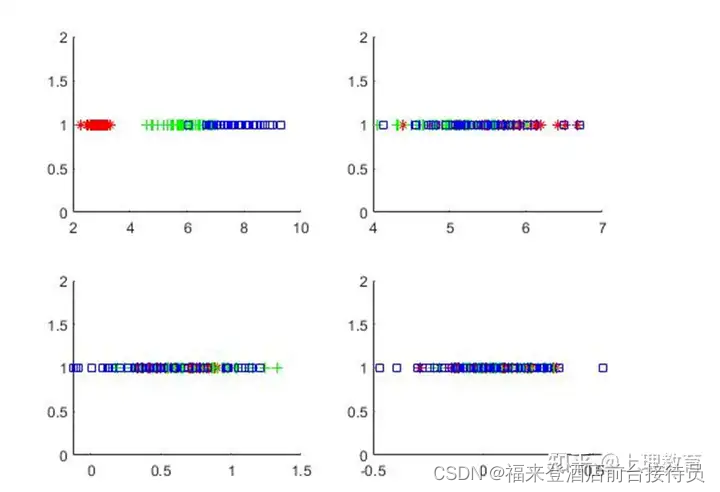
3) 针对原始特征和变换之后的新特征,更改用参与分类的特征分量、比较结果。
代码:
% figure(2);hold on;
% plot(X(3,1:50), X(1,1:50),'r*');
% plot(X(3,51:100), X(1,51:100),'g+');
% plot(X(3,101:150), X(1,101:150),'bs');
figure(2);
subplot(2,2,1); d=1; hold on;
plot(y(d,1:50), ones(1,50),'r*');
plot(y(d,51:100),ones(1,50),'g+');
plot(y(d,101:150), ones(1,50),'bs');
subplot(2,2,2); d=2; hold on;
plot(y(d,1:50), ones(1,50),'r*');
plot(y(d,51:100),ones(1,50),'g+');
plot(y(d,101:150), ones(1,50),'bs');
subplot(2,2,3); d=3; hold on;
plot(y(d,1:50), ones(1,50),'r*');
plot(y(d,51:100),ones(1,50),'g+');
plot(y(d,101:150), ones(1,50),'bs');
subplot(2,2,4); d=4; hold on;
plot(y(d,1:50), ones(1,50),'r*');
plot(y(d,51:100),ones(1,50),'g+');
plot(y(d,101:150), ones(1,50),'bs');
结果
资料仅供学习使用
编者能力有限,如有错误欢迎留言交流
编者的其他专栏:
关注编者了解更多
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









