






用语言模型推断复杂问题中的隐含关系
文章目录
前言
常见词汇:
| inferring implicit-relations | 推断内隐/隐式关系 |
|---|---|
| implicit reasoning questions | 隐含推理问题 |
什么是隐含推理?
1、隐含推理是指人们在决策和解决问题时使用的无意识或自动的心理过程,而不一定意识到其行为背后的推理。隐含推理涉及利用过去的经验、社会规范、文化期望和其他背景知识,快速直觉地对周围的世界做出判断。
举个例子:“圣诞老人在夏天工作吗?”这个问题需要隐式推理,因为它涉及到知道与圣诞老人有关的节日是什么时候,但这从问题中并不明显。
2、区别于显示推理,后者涉及有意识、故意和系统地思考以得出结论。显性推理通常比隐含推理更慢、更费力,但在某些情况下也可以更准确、更可靠。
举个例子:“所有猫都有尾巴,汤姆是一只猫,所以汤姆有尾巴。”这个推理过程就是显式推理,因为我们已经明确知道“所有猫都有尾巴”这个逻辑关系,只需要根据这个关系得出结论即可。
一、摘要
现代语言理解系统面临的一个突出挑战是回答隐含推理问题[answer implicit reasoning questions]的能力,在这种情况下,回答问题所需的推理步骤在文本中没有明确提到。在这项工作中,我们通过将推理步骤的推理与执行分离,研究了当前模型与内隐推理问答(QA)任务斗争的原因。我们定义了一个隐式关系推理的新任务,并构建了一个基准IMPLICITRELATIONS,其中给定一个问题,模型应该输出一个概念-关系对列表,其中的关系描述了回答问题所需的隐式推理步骤。使用IMPLICITRELATIONS,我们评估了来自GPT-3家族的模型,并发现,虽然这些模型在内隐推理QA任务上挣扎,但它们通常在推断内隐关系方面成功(while these models struggle on the implicit reasoning QA task, they often succeed at inferring implicit relations.)。这表明,内隐推理问题的挑战并不仅仅源于需要计划一个推理策略,而是需要在进行推理的同时检索和推理相关信息(retrieving and reasoning over relevant information)。
二、介绍
回答内隐推理问题可以被视为一个两步过程:(a)推断回答问题所需的简单子问题,(b)检索相关知识片段(即回答子问题)并对它们进行推理以得出答案。

图1说明了这种解耦。
为了回答上面的问题–“一个凳子对恐龙够到杏树顶端有用吗?”
我们需要使用关于Lusotitan恐龙和杏树almond tree的知识来推断相关的子问题与它们的高度有关。我们指的是关系高度,问题中没有提到的关系高度是一种隐性关系。曾经的隐性关系根据推断,我们可以检索相关事实,并推断出答案是“错误的”,因为恐龙比杏树高得多。
在这项工作中,我们将重点放在内隐关系上,并研究语言模型推断它们作为回答内隐推理问题的必要(尽管不够)步骤的能力。我们首先定义了隐式关系,并表明它们可以通过众包进行可靠的注释(注释隐式关系的示例见图1和表1)。为了表明隐式关系是常见的,我们从三个现有数据集(STRATEGYQA、CREAK和COMMONSENSEQA 2.0)中对隐式推理问题进行了组织和注释,这导致了IMPLICITRELATIONS,一个包含615个问题和2673个隐式关系注释的新评估基准。
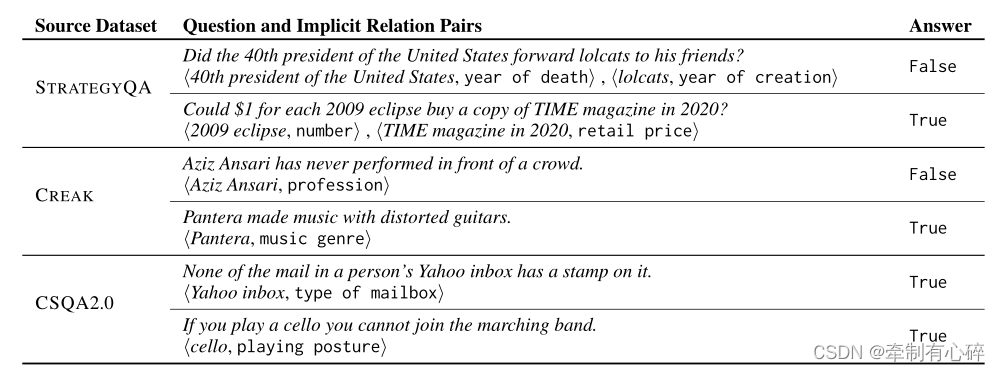
概念-关系对注释示例以及问题源数据集和答案。每个来源都展示了内隐推理问题的不同方面。
我们评估了大型lm,并表明它们相当好地推断了内隐关系,但仍然无法回答内隐推理问题。我们的工作促进了未来改进隐式关系推理的工作,并阐明了与开发能够处理隐式推理的模型相关的因素。从更广泛的角度来看,我们的工作加入了最近的社区努力,强调自然语言中普遍存在的缺失和隐含元素。然而,即使提供了黄金关系,推断隐式关系也不能提高下游QA任务的准确性。(人话:这些模型虽然不能很好地回答隐含推理问题,但它们能够理解句子之间的隐含关系)
那么LLM为什么能推断出隐含的关系,却不好回答隐含推理问答?
因为它们被训练用于生成和理解大量的文本数据,这些数据中包含了丰富的上下文信息和语义关系,这些信息可以帮助模型推断出文本之间的隐含关系。
但是,隐含推理问答任务通常要求模型在读入一些前提条件(premise)之后,根据前提条件推断出某个隐含的结论(hypothesis),这需要模型理解前提条件之间的关系并进行推断,然后才能回答问题。这个任务相对来说更加复杂,需要模型具有更强的逻辑推理能力。而GPT-3系列的模型通常缺乏对逻辑推理的显式建模,因此在处理这种类型的任务时表现不佳。
表明:内隐推理问题的挑战主要不是由于内隐关系推断,但可能是由于需要检索信息和推理。
三、隐式关系
复杂问题是需要多个推理步骤才能得到回答的问题。例如,“达尔文发表《物种起源》时,林奈还活着吗?”,包括获取两个日期,然后比较它们(如下图)。复杂QA中的一个突出挑战是推理步骤是隐含的,应该从问题中推断出来,这一问题最近引起了大量关注。例如,“林奈编辑了达尔文的《物种起源》草案吗?”涉及相同的推理步骤,但没有明确提及。因此,前者是一个明确的推理问题,而后者是一个隐含的推理问题。

提出了QDMR作为复杂问题的意义表示,将复杂问题q分解为m个推理步骤的序列D = (s1,…, sm),每一步si对应一个简单的自然语言问题。一个接一个地回答简单的问题会产生最终答案(见图2中的分解)。Geva等人(2021)收集了隐式推理问题的分解,作为STRATEGYQA数据集的一部分,重要的是,由于推理步骤的隐式性质,推断推理步骤的顺序具有挑战性。除了为内隐推理问题生成有效的分解外,我们还发现了一个额外的挑战,即当这些分解表示为子问题序列时,如何评估这些分解。具体来说,Geva等人(2021)在分解中区分了两种类型的推理步骤——检索步骤,需要检索事实(图2中的s1和s2),以及逻辑步骤,在之前的结果上执行逻辑推理(图2中的s3)。
在这项工作中,我们观察到推断分解的一个关键因素是确定回答问题所必需的隐式关系。具体来说,问题分解中的每个检索步骤通常可以表示为概念-关系对<c,r>,其中c是来自问题的指向概念的符号序列,r是该概念的关系。例如,图2步骤s2中的概念c为“Origin of Species”,关系r为其出版年份。
在此基础上,我们对复杂QA中的隐式关系给出了如下定义。
设q为隐式推理问题,用D = (s1,…, sm)将其分解为m个推理步骤的序列。让{si1,…, sin}是分解d中检索步骤的子集。我们将回答q的隐式关系定义为集合l的n个概念关系对<ci,ri>,其中每个概念关系对对应于一个特定的检索步骤。后续调查为什么它们在下游的QA任务中挣扎。
四、IMPLICIT-RELATIONS基准
在本节中,我们将描述创建IMPLICITRELATIONS的过程,IMPLICITRELATIONS是评估模型推断隐式关系能力的基准。
数据收集
我们策划了需要从三个最近的数据集推断隐含关系的问题:
- STRATEGYQA :是/否问题的数据集,需要隐含的多步推理。STRATEGYQA (STGQA)问题可以从维基百科中回答,并且在所需的推理技能和问题主题方面是多样化的。大型语言模型,如GPT3 ,被证明在STGQA (BIG-bench collaboration)上很挣扎。
- CREAK:包含true/false语句的数据集,需要关于现实世界实体的常识和知识。
- CSQA2 :包含是/否问题和真/假陈述的数据集。CSQA2问题涉及一般的常识推理。大多数问题不需要特定实体的知识。
从三个来源收集问题有两个目的。首先,它证明了推断隐式关系对于许多问题类型是必要的:在多步问题(STGQA)和单步问题(CREAK)中,在以实体为中心的问题(CREAK)和一般常识问题(CSQA2)中。其次,这些数据集是使用不同的协议创建的:STGQA和csq2在数据收集过程中使用循环模型,而CREAK没有。STGQA和CREAK要求注释者自由编写问题,而csq2采用游戏化机制。
来自不同数据收集管道的问题增加了经验结论与特定数据集无关的可能性。
我们使用Amazon Mechanical Turk来注释经过策划的问题的隐含关系。我们挑选了15名众包工作者来识别概念,这些概念是来自问题的符号序列,与回答问题相关,以及每个概念的对应关系(参见附录C中的注释指南)。注释者可以为每个问题指定最多4个概念-关系对,但在实践中,98.9%的概念-关系对≤2对。概念必须直接从输入的问题中提取,而关系则使用简洁的自然语言短语来表达。
对于STGQA和CREAK,它们通常需要关于实体的不常见知识,我们从原始数据源中提供了额外的上下文。对于STGQA,我们提供了事实和完整的问题分解。对于CREAK,我们提供了为什么该声明是正确或错误的解释。

我们在CREAK和CSQA2中每个示例收集了5个注释,在STGQA中收集了3个注释。由于事实和问题分解的可用性,STGQA在注释器之间显示出高度的一致性(见表2)。CREAK和csq2显示出更多的可变性,因此,我们每个示例收集了更多的注释。为了确保质量,我们手动验证了注释过程中创建的所有示例,过滤掉了不符合任务要求的注释。
数据分析
表2提供了收集数据的统计信息。IMPLICITRELATIONS由615个带注释的问题组成,每个数据集约200个,其中来自每个数据源的100个示例用作测试集,其余用作开发集。
concept agreement:我们手动分析了来自每个数据源的20个随机示例,以评估注释者之间对概念和关系的一致性。当至少有三个注释者在一个示例中标识了相同的概念时,我们声明了概念一致。我们发现,77%的概念是由注释者所认同的,只有不到10%的概念是由单个注释者所提取的。
Relation agreement: 评估关系的一致性更具挑战性,因为关系是词汇上可能不同的短语。我们为每个例子标记了注释的关系是否只是在词汇上不同,还是由于回答问题的多种推理策略而不同。在76%的示例中,所有注释器之间的关系在词汇上相同或不同,例如,“平均价格”和“成本”的关系。在24%的例子中,使用了多种推理策略,这将导致不同的推理和检索步骤(见表2)。
总的来说,我们的分析表明,隐式关系可以被可靠地注释。
五、实验设置
现在我们来评估大型lm推断问题中隐含关系的能力。为此,我们使用IMPLICITRELATIONS中的例子在一个少量的上下文学习设置中,其中给定几个输入-输出示例和一个测试输入,LM预计会生成所需的输出。我们关注的是上下文内学习的最新进展,特别是涉及一般常识推理的任务
输入给定问题和对应的n个概念关系对集合,具体输入格式为:

前缀“问题”和“隐含推理”是任意选择的,并在所有实验中保持固定。对于每个测试问题,从开发集中随机抽取k个示例,并且对于每个示例,选择单个随机注释。在我们的实验中,我们用k = 16.
为了解释来自问题中出现的概念或推理捷径的相关性,我们定义了一个“仅概念”基线,在这里,我们不测试模型是否可以从整个问题中推断出隐含的关系,而是测试它从问题中出现的glod概念集推断出它们的能力。对于这个基线,我们使用与以前相同的输入,但将每个问题qi和测试问题q *替换为一组带注释的概念。虽然glod概念的同一性为推断隐含关系提供了有用的信息,但我们希望能够访问完整问题的模型表现得更好。
评估
推断内隐关系包括识别概念和关系。现在我们为这个任务定义评估指标。
概念提取:我们的输出是一组概念关系对。设Cpred为LM预测的概念集合,设Ci为注释器i标注的glod集合。假设标注的概念是原问题的token,我们可以使用编辑举例将每个预测的概念c∈Cpred与Ci的一个概念进行匹配,当最佳匹配的编辑距离大于0.8时,声明匹配。在概念匹配之后,我们以典型的方式计算召回率和精度,并对所有注释器取最大值。事后的手动分析验证了没有由于使用编辑距离而发生不正确的概念匹配。
 图3:给定预测的概念-关系对( P)和黄金概念-关系对(G),我们通过使用编辑距离(1)对齐预测的概念和黄金概念来评估关系,并计算匹配的关系嵌入之间的余弦相似度(2关系覆盖率是相似度> τ(3)的黄金关系的比例。
图3:给定预测的概念-关系对( P)和黄金概念-关系对(G),我们通过使用编辑距离(1)对齐预测的概念和黄金概念来评估关系,并计算匹配的关系嵌入之间的余弦相似度(2关系覆盖率是相似度> τ(3)的黄金关系的比例。
关系覆盖:由于关系是具有高度词汇可变性的短语,因此字符串匹配不是一种可行的策略。为了克服这个问题,我们利用了对齐概念的能力,并使用关系嵌入而不是关系字符串。图3描述了我们对两组预测(Rpred)和注释(Rgold)关系的评估过程。首先(图3,步骤1),我们使用概念对齐预测的和glod概念-关系对(就像用于概念评估的那样)。然后(图3,步骤2),我们嵌入每个关系短语,使用句子transformer all-mpnet-base-v2 ,并计算匹配关系嵌入之间的余弦相似度(如果没有匹配关系,则将其定义为零)。最后(图3,步骤3),如果余弦相似度高于阈值τ,我们考虑一个黄金关系rgold覆盖,并计算关系覆盖率,即被覆盖的glod关系的比例。在这个过程中,我们对每个注释评估模型预测,并将最大值作为最终的关系覆盖率。

表3. 每个数据源的开发集中概念-关系对的平均数量。对于模型生成的配对,我们报告平均超过3个种子。
我们关注的是覆盖范围(而不是精度),因为我们关心的是一个模型是否能揭示隐性关系,但预测额外的关系基本上是无害的。此外,由于我们使用上下文学习,产生的概念关系对的平均数量与黄金概念关系对的平均数量相似.(表3)
为了设置关系嵌入相似性的阈值τ,我们注释了100个开发示例的预测关系是否在语义上等价于匹配的黄金关系。我们选择τ = 0.51,这将导致5%的假阳性率(预测两个不同的关系是等效的)和12%的假阴性率(预测两个等效关系是不同的)。所有报告的结果都是三个随机种子的平均值。
六、LLM可以推断隐含关系

表4显示了隐式关系推断的结果。首先,该模型成功地识别了问题中的相关概念,在所有数据集上实现了较高的概念召回率和精度。这不仅限于命名实体,也可以在概念更抽象的情况下实现,如CSQA2(表1)。更重要的是,GPT-3很好地推断了隐式关系,分别在STGQA、CREAK和CSQA2上实现了0.53、0.54和0.59的关系覆盖得分。此外,在三个数据集上,暴露于完整问题的模型的表现显著优于只暴露于glod概念的模型,分别为21、21和40点。这表明概念包含相关信息,但访问完整的问题允许LM推断推理策略,进而推断隐含关系。
语境中 In-Context的例子的影响
虽然前面提到的结果是令人鼓舞的,但有两个潜在的(非分离的)原因:(a) LM“理解”隐式关系推断的任务,或者(b) LM观察上下文中的例子并使用它们来猜测目标问题的隐式关系(“软复制”)。我们研究这些原因的影响。
为了量化上下文示例的效果,我们使用与目标问题的隐含关系相似或不相似的示例,而不是随机选择它们。
我们首先将每个例子表示为一个嵌入向量,通过(a)连接所有注释关系,即r1,……, rn,使用sentence transformer计算向量表示,以及(b)平均所有注释器的嵌入向量。然后,对于每个例子,我们选择两组上下文中的例子:(a)相似:前k个最相似的例子(使用余弦相似度),(b)不相似:我们丢弃33%最相似的例子,并从其余的例子中随机抽样。在这两种情况下,我们在测试时使用glod隐式关系,因此这个实验仅用于分析。

表5显示了不同上下文内示例集的关系覆盖率,以及LM预测的隐式关系之一从上下文内示例复制的情况的比例。当提出不同的例子时,就会有轻微的差别性能下降,最显著的是STGQA。然而,与仅使用概念相比,结果仍然显著提高。此外,该模型成功地预测了隐含关系,而几乎不复制上下文中的示例。在类似设置中,所有数据集的性能都有所提高,同时复制率也大大提高。这表明,设计检索相似提示符的方法可以提高性能。
为了进一步研究复制和性能之间的关系,我们标记了每个示例,以确定模型是否从上下文示例复制以及推断的隐式关系的覆盖范围。然后,我们计算点二列相关性(Tate, 1954),以检查复制是否与性能相关,并发现相关性很低(所有数据集< 0.1),表明复制不能解释模型性能。
总的来说,这个实验表明,虽然模型可以利用上下文中的例子来提高性能,但LM不仅仅是复制和执行隐式关系推断。
跨数据集上下文示例:
如果lm可以推断隐式关系,即使在上下文示例和目标问题来自不同的数据集时,我们也应该期望高性能。为了测试这一点,我们评估了来自CREAK和CSQA2的问题的性能,当上下文示例来自所有3个数据集时。在STGQA上的测试不能很好地工作,因为示例中的隐式关系的数量通常是两个,而在CREAK和CSQA2中通常是一个(参见表3),因此LM输出一个隐性关系,导致关系覆盖率差。

表6显示,总体而言,所有数据源的关系覆盖率仍然很高,这表明LM确实推断出隐式关系,而不管源数据集中的问题和推理类型如何。概念召回率和精度也相对稳定,除了在上下文示例中使用STGQA时,因为模型倾向于输出两个概念-关系对,降低了精度。因此,LM对上下文示例中出现的输出概念关系对的数量很敏感,但成功地推断了隐式关系。
模型尺寸的影响
最近的工作已经表明,lm的推理能力随着模型大小而提高。我们评估了gbt -3家族模型的这种影响:ada, babbage, curie和davinci,这些模型估计分别有350M, 1.3B, 6.7B和175B参数。text-davinci,迄今为止评估的模型,是一个最近的LM,训练方式不同。

表7展示了STGQA的结果。增加模型大小可以提高关系覆盖率和概念召回率,但对概念精度没有显著影响。从居里夫人到达芬奇的关系覆盖范围略有增加。将此与curie和davinci之间参数的数量级差异进行比较表明,推断隐含关系并不能解释许多推理和常见性QA基准中的性能改进。最小的模型往往会产生结构误差没有正确地学习任务。
七、QA的隐性关系

考虑到lm能够很好地推断内隐关系,一个自然的问题是它们是否能提高回答内隐推理问题的表现。为了检验这一点,我们创建了三个实验设置:问题+预测:语境中的例子是问题、隐含关系和真/假答案的三元组;给模型一个问题,并要求模型返回隐式关系和答案。Question + gold:与预测的Question +类似,不同的是模型被给定目标问题和gold隐含关系,并被要求返回答案。仅提问:上下文示例是成对的问题和答案,模型被给定一个问题并被要求提供答案。我们报告的种子平均超过7颗。结果参见图4。
总的来说,获取黄金或预测的关系都不会提高准确性。这表明LMs在处理隐式推理问题(如检索和推理)方面缺少额外的能力。这与关于思维链提示的研究一致,该研究发现,在问题中添加推理过程的解释并不能提高GPT-3和LaMDA的STGQA表现。然而,最近Chowdhery等人使用思维链提示实现了STGQA的改进,但使用了更大的540b参数PaLM。
表9:IMPLICITRELATIONS中的glod注释(G)和预测§概念关系对以及STRATEGYQA中的问题(Q)和答案(A)的示例。


总结
我们提出隐式关系推理的任务,它解耦推理步骤的推理从他们的执行。我们引入了IMPLICIT-RELATIONS,这是一个基准测试,包含2000多个注释的隐式关系。我们发现,大型lm可以推断出多种类型问题和推理技能之间的内隐关系,但这种成功并不能转化为回答内隐推理问题的改进。我们的工作揭示了大型LMs在解决内隐推理问题时所缺失的能力,并为提高模型推断内隐关系的能力提供了有价值的资源。

















 311
311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









