







Addressing Visual Search in Open and Closed Set Settings
摘要:
- 在大图像中搜索小物体是一项对目前的深度学习系统具有挑战性的任务,在许多现实世界的应用中也很重要,如遥感和医学成像。
- 彻底扫描非常大的图像在计算上是很昂贵的,特别是在足以捕获小物体的分辨率下。一个感兴趣的物体越小,它就越有可能被杂波掩盖或被认为是不重要的。
- 我们在两个互补问题的背景下研究这些问题:封闭的物体检测和开放的目标搜索。首先,我们提出了一种从低分辨率要点图像中预测像素级目标的方法,然后用它来选择在高分辨率下进行局部目标检测的区域。这种方法的好处是不固定在一个预先确定的网格上,因此与现有的方法相比,需要更少的昂贵的高分辨率瞥见。其次,我们提出了一种新的开放集视觉搜索策略,该策略旨在寻找以前未曾见过的、由单一图像定义的目标类别的所有实例。我们通过概率、贝叶斯的视角来解释这两个检测问题,即我们的方法所产生的对象性图作为检测步骤的最大后验方法的先验因素。
- 我们评估了我们的补丁选择策略与这种目标搜索方法的结合以及我们的补丁选择策略与标准物体检测方法的结合的端到端性能。我们的方法中的两个元素都明显优于基线策略.
1.引言:
人工智能(AI),主要是通过深度学习(DL)的进展,最近在越来越多的任务上显示出巨大的成功。在图像分类[15, 13]、物体检测[22, 20]和图像分割[17, 23]等问题以及医疗诊断[6, 17]等应用中,人工智能方法已经达到或超越了人类和传统机器学习的能力[3]。其中,目前的人工智能/DL研究已经解决了诸如开放集识别[25,10](本研究的焦点之一)、隐私[27]、对抗性攻击[7]、低照度学习[19,5]和人工智能偏见[4]等问题。本研究特别关注使用卷积神经网络(CNN)进行物体检测。通过包括YOLO和Fast(er)-RCNN[22, 20, 21, 29]在内的算法,这项任务已经取得了很大进展。然而,大多数现有的物体检测器依赖于这样的假设:感兴趣的物体占据了搜索区域的很大一部分。相反,我们考虑的情况是,物体可能比图像尺寸小几个数量级(例如,每面有数千个像素的图像,而相关物体只跨越几十个像素)。这种情况经常发生在遥感应用中,包括卫星图像的视觉搜索(例如,在停车场寻找车辆)和显微镜图像(例如,在脑组织的电子显微镜成像中检测突触[28])。迄今为止(正如第2节中进一步讨论的那样),大多数基于DL的传统物体检测器在应用于遥感时都很困难。为了进一步加剧与检测小物体有关的挑战,大多数机器视觉技术在每边几百像素的图像上操作,例如ImageNet的224×224像素图像[8]。处理极高分辨率(vHR)图像需要额外的计算、时间和金钱,特别是在流媒体应用中。为了发挥作用,检测问题的方法必须以特定的应用方式有效地管理计算成本、内存和性能之间的权衡。彻底搜索这种vHR图像中出现的不同尺度的物体,促使了非传统方法的发展。依靠CNN的标准技术涉及处理完整图像的滑动窗口。这一过程的计算成本随着图像的大小呈四次方增加,产生了巨大的内存和计算足迹,最终变得难以承受。在实践中,计算预算可能是固定的,这导致了对如何优先选择窗口的选择。
目标:
因此,我们在这项工作中追求两个目标:在vHR图像中实现高性能的物体检测,并开发出可根据数据和计算能力扩展的方法。方法,以便根据数据和计算的限制来扩展 的限制。我们针对两种不同的检测情况来实现这些目标。(1) 封闭式物体检测,我们据此寻找 (1) 封闭式物体检测,我们搜索固定数量的预先确定的物体类别的实例。(2) 开放式目标引导的搜索,在这种情况下,算法必须找到仅由单一图像定义的目标类别的实例。
单一的图像。情景(1)与标准的物体检测情景最相似,在这种情景下,一个模型被训练并在一个已知的类别上测试。并在一组已知的类别上进行测试。
在场景(2)中,类别是不能提前知道的。类并不提前知道。在训练和 在训练和推理过程中,模型被呈现在一个单一的目标图像上,它必须从中推断出目标类别,然后在视频中检测该类别的实例。该类的实例在vHR搜索图像中。在这种情况下,目标类别是由其目标图像定义的 在每个迭代中都是由其目标图像定义的,因此不需要限制在 固定数量的类(因此问题的开放集性质 问题的开放性)
为了解决上述的挑战,在这两种情况下,在vHR图像中检测物体 为了解决上述两种情况下vHR图像中的物体检测问题,我们开发了一种方法来更有效地 "寻找 "属于感兴趣类别的物体(图1)。最近的工作[31] 使用深度强化学习(DRL)解决了这个问题的各个方面。相反,我们通过一种方法来解决这个问题,该方法可以识别出高潜在对象的区域。我们用概率的方法来解释VHR图像中的物体检测。vHR图像中物体检测的概率解释,即预测的物体性图作为检测算法的先验,使我们能够在最大后验中进行搜索。在最大后验(MAP)设置中进行搜索。
2.相关工作
最近的研究通过使用卷积神经网络解决了视觉数据中的物体检测问题。R-CNN[12]和Fast-RCNN[11]依靠选择性搜索来识别提议区域,而FasterRCNN[22]联合识别提议区域及其类别。另一方面,YOLO系列算法[20, 21, 2]将整个图像传递给一个检测网络。它们在一次传递中产生边界框和物体概率,从而导致了卓越的速度。最近,EfficientDet[29]使用了一些算法创新,以一种可量化的更有效的方式提供最先进的检测性能。然而,与之前的方法一样,EfficientDet在检测大而杂乱的场景中的小物体时也很困难。虽然所有这些方法在自然图像上都表现良好,但它们并不能立即适用于vHR图像。vHR图像需要大量降采样,或者至少是平铺,才能通过标准架构和传统GPU硬件进行处理。
将基于DL的物体检测器应用于高空图像的早期工作[24, 9, 32, 26, 18, 16, 30]集中在一些挑战上,包括尺度变化非常大,需要旋转不变性,以及训练数据量有限。虽然在解决这些挑战方面已经取得了进展,但图像分辨率的问题在很大程度上留给了天真的开窗/倾斜或多尺度方法。这些方法在大图像上显示了更好的检测结果,但没有解决效率问题。最近的工作[31]允许使用DRL在vHR图像中进行目标对象检测。这种方法在潜在搜索区域的固定网格上使用两阶段的选择过程,作为解决效率问题的一种方式。每个高分辨率(HR)网格瓦片要么被下采样,要么被传统的检测网络原生处理,并使用学习到的策略来进行低分辨率与高分辨率的判断。DRL代理被训练为选择图像中哪些区域以低分辨率(LR)处理,哪些区域以高分辨率(HR)处理,以便在效率和检测性能之间取得最佳平衡。在这里,我们提供了一种方法,允许对HR窗口(也被称为瞥见)进行灵活的采样,作为固定网格方法的替代。
我们的方法并不排除使用DRL对这些瞥见进行采样,但我们的重点是找到一种VHR图像的表示方法,以方便瞥见选择和随后的物体检测。为了实现这一目标,我们开发了一种从低分辨率(LR)要点图像中估计物体性的方法,然后指导我们的瞥见取样方法。最后,我们展示了这种方法如何在MAP框架中用于开放集搜索。
3.方法
我们讨论了vHR开销图像中物体检测的补充方法。特别是,我们解决了封闭和开放场景下的物体检测问题,使用基于低分辨率要点图像的物体性估计来指导搜索和检测过程。
3.1有效的封闭目标检测
3.1.1目标评估
我们首先开发了一种方法,使我们的模型能够以低分辨率(和低计算成本)检查整个场景,产生一个显著性地图来指导随后的高分辨率物体检测。具体来说,我们训练一个深度神经网络(DNN)来产生一个物体密度图;也就是说,产生一个图来编码包含我们想要检测的类别的物体的区域的可能性。在实践中,给定一个高分辨率的基础级语义分割,Sc,我们产生一个二进制分割Sb,将类级标签转换为代表物体存在或不存在的二进制标签(例如,对于每个像素,Sb(i, j) = 1,如果Sc(i, j) ∈ {1, ., C},Sb(i, j)=0,否则)
为了训练预测模型,我们通过将原始vHR图像IvHR从原始分辨率(如4000x4000)调整到低分辨率(如128x128)来生成低分辨率的gist图像Ig,并以类似的方式缩放Sb以得到固定尺寸的gist掩码Sg,(wgist,hgist)。为方便起见,按照惯例,我们假定图像是正方形的(即wgist = hgist = dgist)。比例因子,α,被定义为

由于下采样的结果,我们预计要点图像会失去一些类的信息,甚至有可能将小的物体减少到无法识别的程度(例如,减少到一个像素)。 然而,我们的目的是要产生捕捉物体可能性的密度图,而不是真正的分割。我们发现,要点图像保留了足够的背景来支持这些预测(例如,纹理、共同出现的较大物体等)。
使用要点图像,我们训练一个U-Net[23],从要点图像中产生物性密度图π。将U-Net表示为f,那么f : Ig → π,其中πij∈ [0, 1] ∀ i, j. 我们将我们的训练损失定义为真实物体掩码和预测之间的二进制交叉熵。
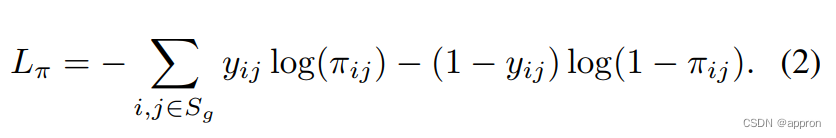
这里yij是像素(i,j)处的真实物体性值,πij是同一位置的物体性预测,代表相应位置被感兴趣的物体占据的可能性。在无法获得地面真实分割的情况下,另一种方法是将边界盒注释转换为相同形状的高斯密度,并归一化为在中心有一个1的峰值。补充实验表明,当高质量的地面真相稀少时,这是一个有效的替代方法。
3.1.2区域选择
鉴于物性图是一种先验,我们的目标是通过尽可能少的高分辨率瞥见来有效地实现物体检测。为了将物性图对检测的好处与使用更复杂的瞥视选择策略(如DRL)的结果区分开来,我们采取了以下简单而高效的方法。首先,我们定义由下游物体检测器确定的适当的瞥见图像尺寸。假设输入图像为方形,我们用dglimpse来表示最终的瞥视分辨率。根据这个定义,我们可以通过d′ glimpse = ceil(α - dglimpse)来确定gist图像中的相应尺寸。
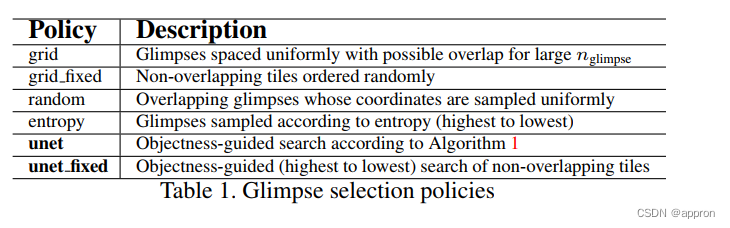
考虑到相对于要旨图像的瞥见大小,我们试图定义一个对瞥见进行采样的策略,以最大限度地检测出感兴趣的对象。我们最初关注的是基于规则的政策,它是确定的和可解释的。我们简单而有效的策略在算法1中描述。该方法迭代地对瞥见的物体进行采样,使总的可用物体数量最大化。这个策略允许瞥见的物体相互重叠,但可以通过增加或减少β项来轻松修改(例如,β=-(d′瞥见2)可以防止任何瞥见的重叠)。

在算法1的循环中的每一步,我们寻找下一步要瞥见的地方,以便采样的瞥见能使其中包含的总对象性最大化。为了加快搜索速度,我们首先计算当前地图π的积分图像。

从这个表格中,我们可以通过简单地对Sπ的移位(根据d′LR)版本进行求和,找到最大值的位置,从而轻松地搜索出具有最大对象性的一瞥。使用Python风格的符号来说明对Sπ进行四次移位操作的索引,在所有搜索位置(x,y)上具有最大对象性的一瞥可以根据以下方式找到。
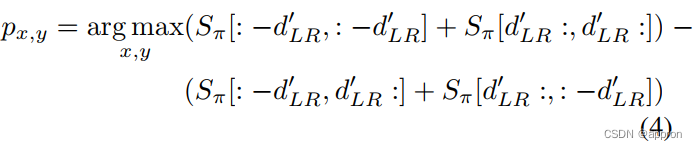
3.1.3目标检测
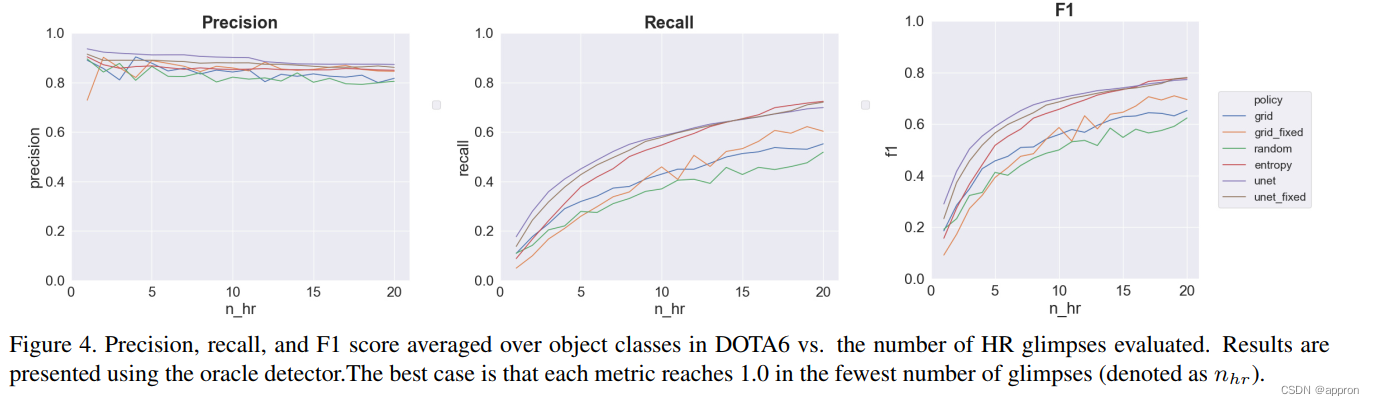
一旦选择了LR瞥见的区域,就从vHR图像中选择相应的HR区域,并输入到基于DL的物体检测器(例如YOLO),该检测器产生检测列表。物体检测器经过预训练,以检测出一组封闭的物体类别,给定的瓦片与HR瞥见的大小相同。这个瞥见/探测过程不断重复,直到满足三个条件中的一个。(1) 整个图像已被处理,(2) 瞥见的累计物体覆盖率超过预定的阈值(例如,大于95%的物体覆盖率),或者(3) 处理的瞥见数量满足预定的计算预算(例如,最多10个瞥见)。
3.2高效的开放集物体检测和目标引导的搜索
现在我们来看看基于目标的开放集搜索的任务。 在这种情况下,目标是在图像中搜索支持所需目标对象存在的瓦片(子图像),同时只依靠该目标的单一实例图像(我们在此表示为o)。在训练和推理的过程中,检测器模型会收到一张目标图像,它必须从中隐含地推断出一个以前未见过的目标类别,以及一张搜索图像,它必须在其中定位目标物体的实例,并产生一组包含该目标的瓷砖位置。
考虑一组通过将原始图像平铺成一组子图像平铺得到的候选搜索位置,并将其坐标表示为(i,j)。为了实现最佳开放集搜索的目标,我们将特定目标物体在该位置被发现的可能性lo(i, j)作为标准。我们通过比较典范物体图像o和瓦片T(i, j)的网络嵌入表示f来估计这个可能性。
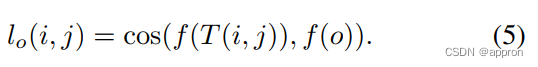
我们使用ResNet50的倒数第二层作为嵌入函数f(.)来计算这个深度相似性lo(i, j)。 我们进一步考虑使用最大后验标准的精炼方法,其中我们将整合在特定瓦片(坐标(i, j))上的对象性概率πi,j(在公式(2)中)解释为任何感兴趣的对象存在于该瓦片的先验。那么,由此产生的目标物体存在于该瓦片中的后验概率po(i, j)就是。
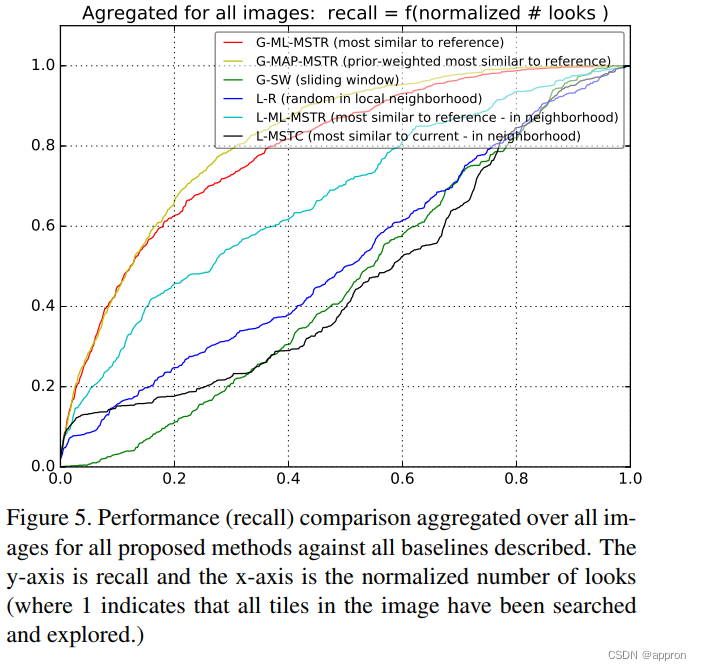
我们使用上述这些指标,通过访问瓷砖的深度相似性来获得一个等级排序。我们的搜索策略被简单地选择为按lo(i, j)或po(i, j)的递减顺序访问瓷砖。我们把按可能性lo(i, j)排序的全局搜索称为G-ML-MSTR("全局搜索/搜索与参考文献最相似"),把按aposteriori概率po(i, j)排序的全局搜索称为G-MAP-MSTR。
4.实验


 结论
结论
本研究对封闭式物体检测和开放式目标搜索进行了研究。它提出了一种从低分辨率要点图像中预测像素级物体性的方法,然后用它来选择高分辨率区域进行物体检测,并在贝叶斯方法中进行开放式视觉目标搜索。物体性引导的方法被认为对提高vHR图像处理的效率有好处。这对于选择HR瞥见和作为先验纳入开放集目标搜索都是如此。与基线方法相比,这两种方法都被证明能提高性能。















 9715
9715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









