






上部介绍了我第一次学习UML的大致经历和体会,这一部分说说我这个项目开发中类的设计。
需要说明一下,把这些东西写出来,并不表明我以这些方案为最佳,我只是想把自己的工作回顾一下、总结得失,为将来工作提供借鉴。实际上在写这个回顾的时候,我已经发现不少值得再优化、改进之处。
一、 先来些背景介绍。
我在税局工作,以前的工作很有一部分是处理税收统计、分析方面的事务。自己从系统中导出数据,开发了一些小工具,完成年度(月度、季度)分类统计、对比分析、趋势预测等,分析结果做成Excel文件。
统计分析工作有三类,一类是基于日常管理需要,分析对比不同年度月度、季度等税收指标;第二类是考察税收年度变化趋势;第三类是针对企业所得税汇算清缴报告的专项分析。
每类统计要求生成多种表格。表格可能按时间周期、管理部门、也可能按税款属性、纳税人登记注册属性分类,计算分类统计指标。
一个大类又会切割成若干小类,而且理论上存在不断切割下去的可能。不过实际上也就切割一、两层,极个别会到三层,管理精细化还只到这种程度。
可能会在分类之间交叉统计,例如管理部门和注册行业是不同的分类方法,统计结果要求分解到每个管理部门的不同行业。
统计结果分类不见得与原始数据分类一致,所以涉及分类转换。
有些统计需要把多个表格合并到一个文件,有些合并到多个文件。某些表格要有配图。
为了便于配图,便于统计结果直接复制、粘贴用于其它目的,所有输出结果均以Excel文件存盘。
刚开始的时候这些工作完全手工处理,在探索分析思路、理顺统计过程中,零零散散编了些程序半自动化处理。现在有了时间,于是决定把这些零散软件整合归集到一起、实现全自动化处理。
二、 总体思路
看图一,这是总体思路顺序图。
与活动图相比,顺序图更能体现“对象”的作用,能体现出“对象”的活动。活动图对“过程”反映比较好,“对象”不够突出。既然是面向对象软件开发,那就拿顺序图出来吧。
另外,请留意结合上下文理解本文中“类”的具体含义,有时候是指统计上的分“类”,有时候是面向对象软件开发中的软件单元“类”的概念。
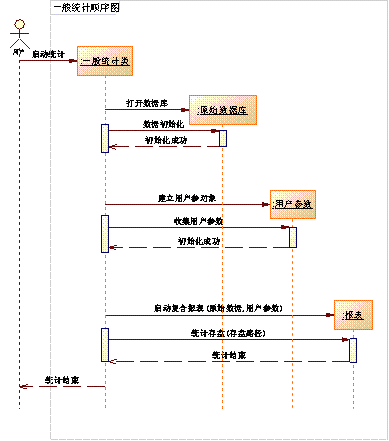
图一
1 、 用户启动某个统计过程。当前是一个抽象的“一般统计类”,实际统计工作开始的时候,用户启动的是该类的某个可实例化派生类。
2 、 “一般统计类”首先建立一个代表某个或某些数据库的对象,打开系统数据库,建立与数据库之间的通道,为将来通过这个对象请求数据、请求数据库服务做好准备。当前并不实际存取数据。
3 、 必要的数据环境初始化。不同的统计过程可能要引用不同参数初始化数据环境,某些编成工具(例如C++)支持类构造函数多态——以不同参数构造同一对象,则可将本步骤置入构造函数,在上一环节执行。某些编成工具不支持构造函数多态,则可以先建立对象,再调用对象的其它函数初始化数据环境。
4 、 建立用户参数对象。和数据环境一样,以对象代表用户对统计的某些个性化要求。
5 、 用户参数收集。与数据环境初始化类似,为不支持构造函数多态编程工具准备。
6 、 建立报表对象。抽象报表对象,以抽象数据库对象、抽象用户参数对象为参数,建立一个可以生成统计结果文件的抽象对象。由其派生的可实例化报表对象引用具体数据库对象、具体用户参数生成具体报表。
7 、 报表存盘。一份报表可能非常庞大,不见得适合驻留内存、全部生成后一次性存盘,所以采取一边计算、一边存盘的方式。
以上是抽象的概念思路,具体实现时各对象不一定严格按这个顺序活动,允许互为参数、交叉引用。咱们先撇开具体事务,从抽象概念开始,先决定宏观架构,再逐步具体化。
下面一个一个说明。
三、 一般统计类
由于统计中分类的循环、分解、迭代是最明显的特征,所以一开始很自然设想在软件中设置这样一个控制类一口气实现这个目的。
采用面向对象的软件开发方法一个很重要的出发点就是提高软件的灵活性。这有两种含义,一种是可扩展性,也就是说在已有的基础上派生、衍生的能力;另一种是可适应性、可重用性,也就是说能适用于不同环境、包括未知环境的能力。
一般来说为了提高类的可扩展性,提高派生潜力,总是趋向给类设计一个便于变化的精巧内部结构。但所谓精巧、优化、最佳一定是相对与已知或特定环境而言,一旦环境发生变化,内部的精巧结构反而可能会成为累赘,妨碍类的派生。例如为城市路况设计的汽车减震装置装到哪个小汽车里去都适用,小轿车、城市SUV、MPV等等,体积小、重量轻、生产成本低、安装维护方便。但却可能完全无法用于军队作战越野车,因为路况差别太大,设计思路完全不同。
我开发这个软件的时候很快就遇上这个问题。
原来几个软件是分开独立开发的,针对的是特定具体问题,一个控制类一路派生下去,解决所有问题。
但整合在一起发现这条路行不通。因为报表之间的内在区别还是很大的,表面上格式差不多,数据来源、运算过程、循环迭代次数五花八门。由一个统一的类涵盖、包容所有这些差异太困难,会把这个类自身搞得很复杂,而且结构一复杂质量没法保证,很难把全部可能性都罗列出来一一测试一遍。
所以,后来调整了一下思路,分成两级控制。第一级称为一般统计类,负责接受用户指令,启动统计,初始化数据环境,这是主过程控制。然后触发第二级控制——报表,这是次级过程控制,控制循环、分解、迭代,生成不同文件。
这也正好与用户的视角一致,因为用户只看到一个过程、几个文件。
四、 原始数据库类
这个类一是把所有对系统数据的存取集中到一起。统计对象五花八门,即可能是数据库中实际存在的物理数据、真实数据,也可能是物理数据组合、运算后的逻辑数据、虚拟数据,例如数据库中常见的视图、别名之类。即使是实际存在的物理数据,也可能存在不同版本。编程调试的时候往往会尝试不同的数据指向、数据来源,那么集中在这个类里调整就可以了。
二是负责核心统计计算。目前还找不出有比SQL更适合大数据集、不确定规模数据集检索、统计的工具。所以我把核心统计计算都安排在数据库里、由SQL指令完成,计算完成后才被其它软件读取、存盘输出。
数据在数据库里计算生成,计算过程对外屏蔽,从数据库之外的角度看,仍然只是数据存取问题。
接口开放、过程屏蔽,软件不直接访问数据库,与数据库耦合度降低,便于调试,便于软件重复利用,提高了双方灵活性。
五、 用户参数
用户参数也可能来自不同渠道,有可能来自交互应答,有可能来自批量参数文件,有可能还要对用户参数予以加工、改造,生成逻辑、虚拟用户参数。所以设置一个统一的类负责处理这方面事项。
从概念上来说,对用户参数的读取与数据库读取很类似,对用户参数的改造、加工还有可能要结合系统数据库数据,而且以逻辑数据——例如视图——的方式提供下一步使用可能更方便,所以在实际软件开发方案中,“用户参数”是“原始数据库”的一个派生类。
六、 报表
这个类负责接受主控“一般统计类”传递过来的数据对象、用户参数,完成特定的统计过程,生成结果文件。
从用户的角度讲,一次统计只有一个结果,是一份报表,不管它是一个文件还是多个文件,甚至一张表。
但从软件开发的角度讲,是一个结果集,若干个独立的表构成一个文件,若干文件构成一份报表。
前面说过,核心统计计算安排在数据库里、由SQL指令完成。所以这个类的实际工作是把统计目的分解成一张张表,从数据库读取数据,填充这些表,然后调整表格格式、插入图表,合并表格到文件,把文件统一存入指定文件夹,完成一份报表。
因此最终统计结果可能有三种,第一种是只有一个单表文件;第二种是一个多表组合文件,文件只有一个,但包含多张表格。第三种多个文件,一次统计结果有多个文件组成。
对于第三种结果来说,只要第二种结果归集在一起,就自然形成了,无需其它操作,所以不必再考虑编程。
因此,只需从“报表”类设计派生出两子类——单表文件和组合文件。
我这次统计结果都是Excel文件,Excel里表是运行状态下的概念,存盘的时候只能以文件的形式存在,所以我把表和单表文件作为一个概念处理。
查手册,Excel内部表和图表是相互独立、无依赖关系的不同类对象。只不过绝大部分情况下我们都是把图表嵌在表里,而且是根据表来作图,所以完全没有意识到它们的相互独立性,还以为图依附于表。
这样看来似乎应该也给图一个单独的概念。但思前想后,我这次还没有单图文件,图还都是嵌入在表里的。所以最终还是没有设计独立的单图文件类,还是在单表文件类里处理图表问题。
组合文件是单表文件的合并,生成组合文件必然要先生成单表文件,这样看上去组合文件应该从单表文件派生。但我的思路中这两类对象处理的着重点完全不同,各有自己鲜明特点。
首先,从功能上来看,单表文件负责生成表格、图表、调整格式。组合文件负责统计分类的转换、分解、循环、迭代,分类的转换、分解、迭代可能不会仅限一、两次,那么这个迭代、循环关系就变得很复杂,需要小心谨慎处理。
其次,单表文件也不会是最终简单类,还会继续派生,组合文件如果从单表文件派生,那么它应该从哪个节点开始派生呢?现在只有Excel文件,将来还可能会有Word文件、影音文件,将来怎么办?
所以,单表文件和组合文件之间不应该是派生关系,而应该是组合、聚合关系。
七、 其它类
1 、 多表Excel文件管理类
Excel多表合并到一个文件也是一类非常独特的操作,可能涉及同名表格(Excel里的Worksheet)处理问题,插入之前,首先检索是否存在同名表格,如果存在,是删除旧表、还是重命名新表;插入是否存在顺序要求等。
所以尽管只有组合文件存在这些需求,我还是安排了一个独立的类——多表Excel文件管理类——来实现这些功能,把这个类的一个对象实例作为多表文件类的一个属性成员,专门负责处理表格合并。
2 、 行列转换表
行列转换也是表格处理中常见典型操作。行列转换把原来的属性值转变为属性,这会带来表格结构、格式、排列顺序的变化,所以有必要单独处理。
3 、 视图
现实世界不可能直接存在我们想要的所有数据,我们往往需要变换角度考察现实数据,对现实数据进行加工、改造,这就是逻辑数据、虚拟数据,而且数据量还可能很大。
视图就是数据库中的逻辑数据、虚拟数据,是现实数据改造后的结果。设置这个类负责虚拟数据资源的配置和回收。
八、 类图回顾
类划分到这里,整个软件的宏观架构已经出来了,如图二。
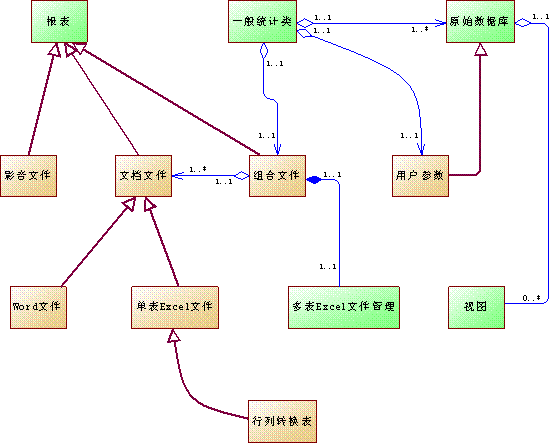
图二
从图中大致可以看出软件的运行历程:一般统计类对象创建原始数据库和用户参数对象,传递到组合文件类对象;组合文件类对象指示数据库对象对数据进行分解、转换,结果以数据库视图的形式存在,启动单表文件类对象;单表文件类对象再次指示数据库执行有关统计指令,并提取统计结果存盘,调整格式,存盘文件返回给组合文件类对象;组合文件对象合并报表,返回统计类对象,结束一次统计。
图中绿色部分属于根基类,其它类由此派生。
派生可实例化“类”与具体业务关系密切,将来我会提取一些具有普遍参考价值的开发体会,另发博文,欢迎指正、沟通、交流。















 687
687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









