







引言
五种获取高效深度学习模型的方法:1)设计轻量级神经网络;2)剪枝;3)量化;4)神经架构搜索;5)知识蒸馏。
知识蒸馏通常是一种Teacher-Student训练架构,运用已经训练好的教师模型提供知识,然后学生模型通过蒸馏训练来获取教师的知识。知识蒸馏可以分为两种,一种是将复杂模型的知识蒸馏到轻量级模型中,核心要义是模型压缩;另一种是将同样复杂的模型知识蒸馏到复杂的模型中,核心要以是模型性能增强。
在本文的研究调查中,知识蒸馏不 仅可以用于模型压缩,它还能通过互学习和自学习等优化策略来提高一个复杂模型的性能. 同时,知识蒸馏可以利用无标签和跨模态等数据的特征,对模型增强也具有显著的提升效果.
先前的研究都没有关注到结构化特征知识,而它在知识架构中又是不可或缺的. 某个结构上的知识往往不是单一的,它们是有关联的、多个知识形式组合. 充分利用教师网络中的结构化特征知识对学生模型的性能提升是有利的,因此它在近两年的工作中越发重要
本文从不同视角给出了基于知识蒸馏的描述,在知识蒸馏的方法上,本文增加了知识合并和教师助理的介绍;在技术融合的小节,本文增加了知识蒸馏与自动编码器、集成学习和联邦学习的技术融合;在知识蒸馏的应用进展中,本文分别介绍了知识蒸馏在模型压缩和模型增强的应用,并增加了多模态数据和金融证券的应用进展;在知识蒸馏的研究趋势展望中,本文给出了更多的研究趋势,特别是介绍了模型增强的应用前景.
知识蒸馏的提出
早期的工作使用逻辑单元和类概率,逻辑单元是softmax激活的前一层,而类概率是逻辑单元通过softmax激活得来的,这些都属于硬目标知识,缺点是,类概率层的负标签输出的信息基本已经丢失. 将该类概率作为学生的监督信号,相当于让学生学习硬目标知识
软目标(带有温度参数T的类概率)

学生模型除了在使用教师模型的软目标进行监督之外,还需要为学生模型自身输出与数据集的标签进行监督,学习效果会更好。

知识蒸馏的框架
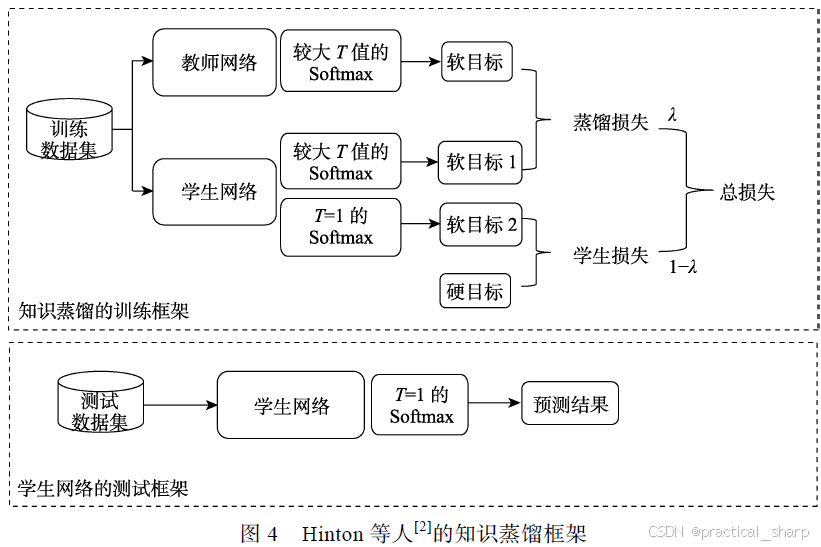
知识蒸馏的作用机制
软目标携带着比硬目标更多的泛化信息来防止学生模型过拟合
软目标为学生模型提供正则化约束
软目标为学生模型提供了特权信息,privileged information,指的是教师模型提供的解释,评论和比较等信息
软目标引导了学生模型优化的方向,软目标使学生模型比从原始数据中进行优化学习具有更高的学习速度和更好的性能
蒸馏的知识形式
最原始的知识蒸馏 vanilla knowledge distillation 仅仅从教师模型输出的软目标中学习除轻量级的学生模型。然而,当教师模型变得更深时,仅仅学习软目标是不够的. 因此,我们不仅需要获取教师模型输出的知识,还需要学习隐含在教师模型中的其它知识,比如中间特征知识. 本节总结了可以使用的知识形式有输出特征知识、中间特征知识、关系特征知识和结构特征知识.
从学生解题的角度,输出特征知识提供了解题的答案,中间特征知识提供了解题的过程,关系特征知识提供了解题的方法,结构特征知识则提供了完整的知识体系.
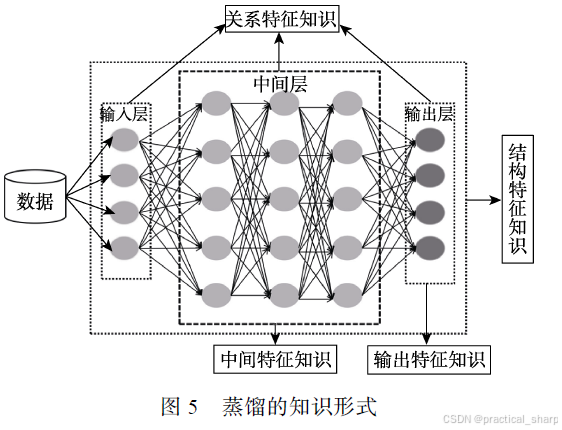
输出特征知识:指的是教师模型的最后一层特征,主要包括逻辑单元和软目标的知识。输出特征知识蒸馏的主要思想是促使学生能够学习到教师模型的最终预测,以达到和教师模型一样的预测性能. 不同计算机视觉任务的最后一层特征的表示含义是不同的,如下表所示

中间特征知识:教师的中间特征状态知识可以用于解决教师和学生模型在容量之间存在的“代沟”(Gap)问题,其主要思想是从教师中间的网络层中提取特征来充当学生模型中间层输出的提示(Hint).
如果网络较深的话,单单学习教师的输出特征知识是不够的. 复杂教师和简单学生模型在中间的隐含层之间存在着显著的容量差异,这导致它们不同的特征表达能力
它不仅需要利用教师模型的输出特征知识,还需要使用教师模型隐含层中的特征图知识. 最早使用教师模型中间特征知识的是FitNets[27],其主要思想是促使学生的隐含层能预测出与教师隐含层相近的输出,学生模型学习教师中间隐含层的损失定义为

不难看出,中间特征的知识蒸馏是要最小化教师与学生之间的中间特征映射距离,这一目标和度量学习的思想很相似. 知识蒸馏中应用最广的度量学习算法是KL 散度,如用于最小化教师与学生模型输出的相对概率分布
关系特征知识:指的是教师模型不同层和不同数据样本之间的关系知识. 关系特征知识蒸馏认为学习的本质不是特征输出的结果,而是层与层之间和样本数据之间的关系. 它的重点是提供一个恒等的关系映射使得学生模型能够更好的学习教师模型的关系知识
A gift from knowledge distillation: fast optimization, network minimization and transfer learning
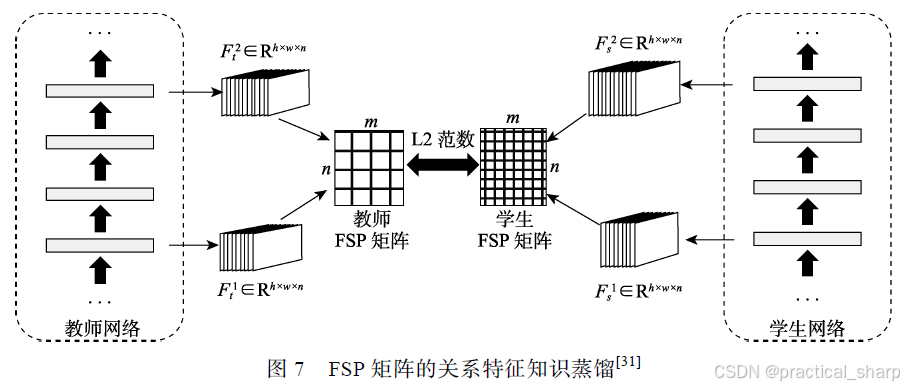
最早的关系特征知识蒸馏可以追溯到Yim 等人[31]的“Flow of Solution Procedure”(FSP)矩阵,其中通过模仿教师生成的FSP 矩阵来实施对学生模型训练的指导. FSP 矩阵的知识蒸馏可视化结构如图7 所
Park 等人[32]提出了基于样本的角度关系和距离关系蒸馏
关系特征知识蒸馏不仅可以利用不同网络层的关系,还可以使用数据样本间的关系. 我们将基于关系的特征知识蒸馏分为三类:基于网络层的关系、基于样本间的关系和相关任务的关系知识蒸馏
基于网络层的关系蒸馏:FSP矩阵[31],雅可比矩阵[33],径向基函数计算层间的相关性[34]
样本间的关系特征知识蒸馏:额外利用了不同样本之间的关系知识,即把教师模型捕捉到的数据内部关系迁移到学生模型中. 学习排名算法[35]–样本间相似性知识,相互关系知识[32]和相关性知识[36]。基于样本的关系知识蒸馏不仅传递了单个样本的信息,而且传输多个样本间的关系知识,使学生模型形成与教师相同的关系
任务相关的关系知识蒸馏:指的是与特定任务相关的关系蒸馏方式,如通过度量长距离跨度视频在外观和几何信息上的关系特征来执行视频目标检测.
结构特征知识:指的是教师模型的完整知识体系,不仅包括教师的输出特征知识,中间特征知识和关系特征知识,还包括教师模型的区域特征分布等知识。很抽象,先不了解。
知识蒸馏的方法:知识合并,多教师学习,教师助理,跨模态蒸馏,相互蒸馏,终身蒸馏,自蒸馏
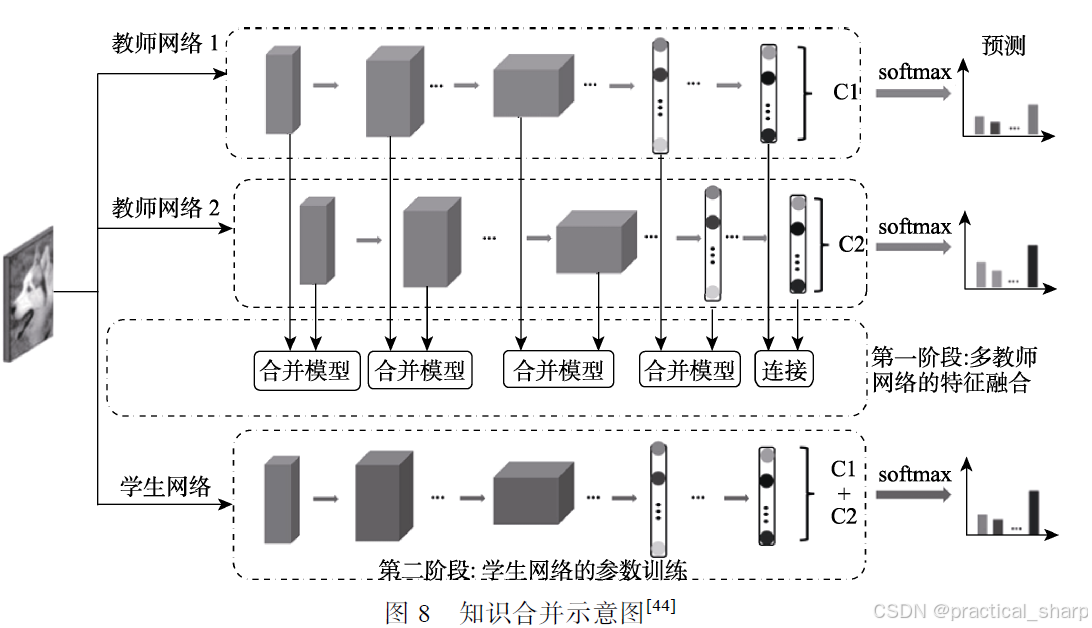
知识合并 Knowledge Amalgamation:指的是将多个教师或多个任务的知识迁移到单个学生模型中,从而使其可以同时处理多个任务。知识合并的重点是学生应该如何将多个教师的知识用于更新单个学生模型参数,并且训练结束的学生模型能处理多个教师模型原先的任务.
典型知识合并方法:将多个教师模型的特征知识进行融合,然后将所获得的融合特征作为学生模型学习参数的指导[44,45]
另一种知识合并方法:学生模型同时向多个教师模型学习多个任务的特征
并非所有的教师模型对多任务表示学习都能产生有利的影响. 为了解决这个问题,Shen 等人[46]引入了选择性学习,将多个教师模型中给出置信度最高的预测作为学生模型的学习目标,以降低错误的监督信息对学生模型的误导.
多教师学习:知识合并和多教师学习(Learning from MultipleTeachers)都属于“多教师-单学生”的网络训练结构.它们的相同点是,知识合并和多教师学习都是学习多个教师模型的知识,但是它们的目标却是不一样的. 知识合并是要促使学生模型能同时处理多个教师模型原先的任务,而多教师学习是提高学生模型在单个任务上的性能
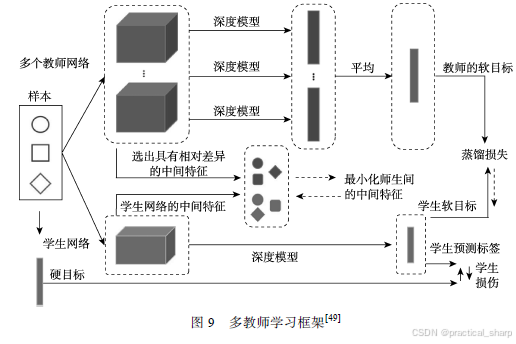
单单学习软目标是不够的,充分利用多个教师模型的中间特征知识很有利于学生模型的学习. 目前有投票策略,平均权重和非线性变换等方法能够从多个网络中获得单个网络的中间特征表示.
教师助理:教师和学生模型由于容量差异大导致它们存在着“代沟”. “代沟”既可以通过传递教师的特征知识去缓解,也可以使用教师助理(Teacher Assistant)网络去协助学生模型学习
跨模态知识蒸馏
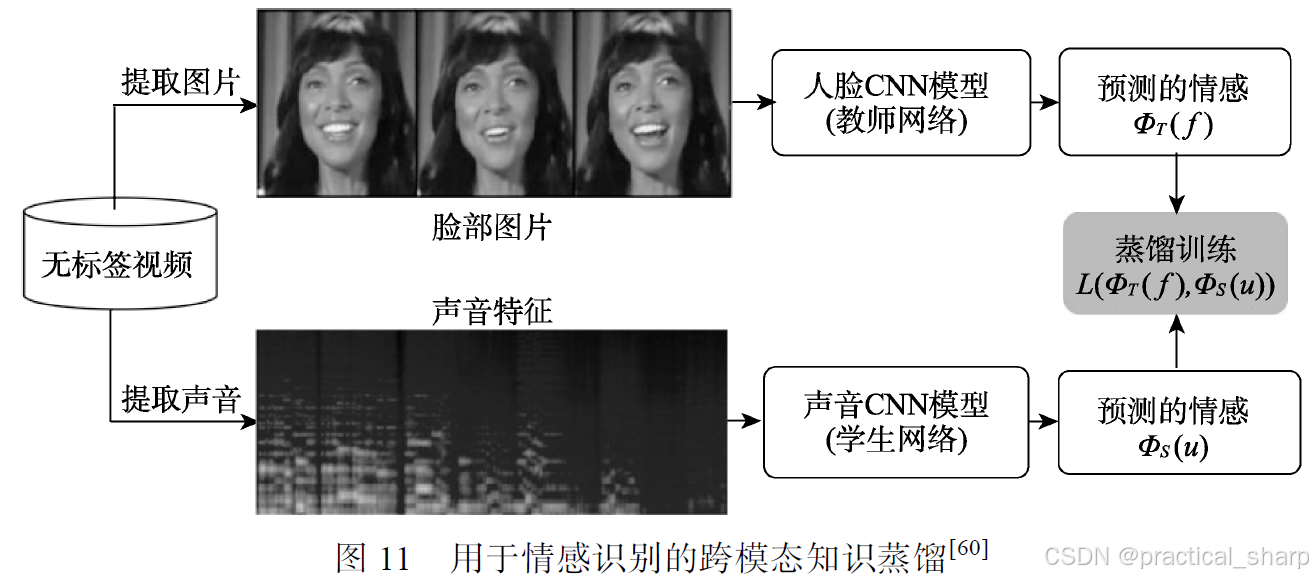
跨模态知识蒸馏的早期代表性工作:
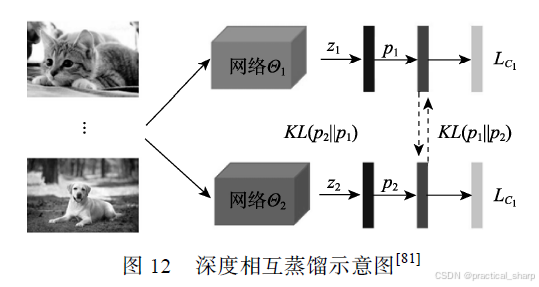
相互蒸馏:指的是让一组未经训练的学生模型同时开始学习,并共同解决任务.其意义在于没有强大教师的情况下,学生模型可以通过相互学习的集成预测来提高性能
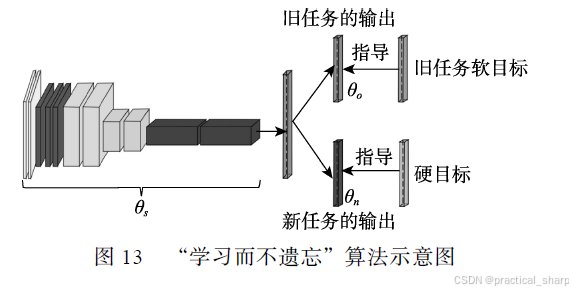
终身蒸馏 Lifelong Distillation:终身学习也称为持续学习或增量学习,使用知识蒸馏方法来实现终身学习,称之为终身蒸馏,核心要义是通过知识蒸馏来保持旧任务和适应新任务的性能,其重点是训练新数据时如何保持旧任务的性能来减轻灾难性遗忘
自蒸馏 Self-Distillation:单个网络被同时用作教师和学生模型,让单个网络模型在自我学习的过程中通过知识蒸馏去提升性能.
第一类自蒸馏是使用不同样本信息进行相互蒸馏,其它样本的软标签可以避免网络过度自信的预测,甚至能通过最小化不同样本间的预测分布来减少类内距离,不太懂。
另一类是单个网络的网络层间进行自蒸馏. 最通常的做法是使用深层网络的特征去指导浅层网络的学习[92],其中深层网络的特征包括了网络输出的软目标.

应用在多模态学习中的知识蒸馏称之为多模态蒸馏 Multimodal Distillation,核心要义是利用不同模态数据的信息为目标任务提供互补的线索,从而提高学生网络的性能
跨模态蒸馏通常是将不同模态数据的特征隐含地嵌入在单个模态数据的学生网络中,提高使用单个模态数据作为输入的学生网络在预测时的性能. 多模态蒸馏则是使用知识蒸馏整合多种模态数据的信息,提高模型泛化的能力,学生网络在预测时可以使用不同的模态数据. 因此,在通常情况下,跨模态蒸馏是多模态蒸馏的一个特例.
知识蒸馏的研究趋势展望
如何确定何种知识是最佳的?基于中间特征,基于输出特征,基于关系,基于结构
如何确定教师模型中网络层中何处的知识是最佳的?
如何定义最佳的师生结构?
如何衡量师生间特征的接近程度?KL 散度、均方误差(Mean Squared Error,MSE)和余弦相似性.
不同损失函数的作用范围是不一样的. 例如,通过KL 散度衡量的两个随机分布上的相似度是非对称的. 余弦相似性强调两个向量的特征在方向上的差异,却没有考虑向量大小. MSE 在高维特征中的作用不明显,且很容易被随机特征混淆[4]. 因此,衡量师生间特征接近程度的方法是多样化的,我们需要根据特定的问题和场景选取最合适的损失函数。
蒸馏的知识形式、方法和融合技术还需要深入探索
拓展阅读
[1] Knowledge distillation: A survey
[2] Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks
[3] Knowledge distillation in deep learning and its applications
[4] CVPR 2017: A gift from knowledge distillation: fast optimization, network minimization and transfer learning
[5] CVPR 2019: Relational knowledge distillation

















 1072
1072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









