







近一个月也陆续写了几篇读书笔记了(还夹带技术向的效率工具分享),但其实一直还更想聊一聊自己工作能力圈相关的内容。作为一名半路出家的码农,还一路误打误撞入了算法的坑,现在又从事着AGI(通用人工智能)相关的工作,我最拿得出手的话题领域自然是「人工智能」。这是一门涵盖了多个领域知识和技能的交叉学科(涉及计算机科学、数学、神经科学,乃至心理学、语言学甚至哲学),而本人的水平和精力十分有限,仅仅是通过平时的工作管中窥豹,因此希望尽可能以通俗的语言来分享一些自己的粗浅见解和思考,如果有任何错误还请大家批评指正,也非常欢迎一同交流探讨。
要聊人工智能,自然是绕不开这两年风头无两的大模型了,我们就毫无悬念地从这个话题说起吧。但由于我主要从事的还是自然语言理解方面的工作,对Stable Diffusion、Sora之类的图/视频生成大模型不甚了解,因此下面聊的主要还是语言大模型。
无论是第一梯队的GPT4(顺带diss一下不再open的「CloseAI」)、Claude(Anthropic),还是国内疯狂追赶前者的百度文心一言(这里也吐槽下这个拗口的名字,我经常搞不清到底是「文心一言」还是「文言一心」)、阿里通义千问、最近火出圈儿的Kimi Chat,亦或是以Meta(大多人可能还是更加习惯Facebook这个名字吧)的Llama为代表的开源模型大家族,相信大模型已经或多或少地走进了大家的生活里,哪怕是通过那些靠贩卖焦虑来割韭菜的短视频或者公众号文章。但除了相关从业者之外,相信大部分人都并不太知晓这些横空出世的大模型是如何使得曾经的「人工智障」智能助手们忽然如同打通了任督二脉一般,一跃成为了「可能让很多人失业的」效率工具的。我尝试绕过晦涩的技术细节,用更加通俗易懂的白话或比喻来解答这个问题。
NTP(Next Token Prediction)的奇迹
基于神经网络技术的数据驱动模型是需要经过「训练」得到的,这个「训练」在我看来很像是学生做题 ,而大模型的训练更是分了好几个不同的阶段,我接下来先要介绍的是名为「预训练」的第一阶段。
在这个过程中它其实一直在重复着同一个任务,那就是预测一个句子的下一个输出(以下称为token,于中文而言是下一个汉字,于英文而言是下一个单词,值得注意的是标点符号也算在内),我们称之为「Next Token Prediction」(以下简称NTP)。举个例子:
👉 刘德华是香港著名的_
如果让我们来判断下一个token最适合填什么,比较常见的选择可能会是:「歌(手)」,「演(员)」,「艺(人)」等等。假设填入的是「艺」,那么我们将得到:
👉 刘德华是香港著名的艺_
这时候继续往下填的话,大概率会是「人」。乍一看是不是很像在做完形填空题,没错,NTP其实就是一种特殊的「完形填空」,稍稍回忆下中学时做过的英语完形填空,大概是长这个样子的:
👉 ... The professor was very __ 8 __ and decided to study it further. ...
(8) A. glad B. surprised C. worried D. happy
我们根据空位的「上下文」(可能是所在句子、段落甚至整篇文章),从给定候选项中选择一个最恰当的答案。而再回过头来看NTP任务的设定,其特殊就在于填空时我们总是只能看到「左边的上文」也就是前面说了什么,而没有任何「下文」的约束,同时也没有限定候选项,这个看似很小的差别却恰恰引发了巨大的变化,并且奠定了大模型多样化生成能力的基础:
-
首先由于没有了下文和候选项的约束,预测结果的多样性会大大提高,哪怕是同一个上文也可以有多种 next token 的结果,有点像单选变多选的感觉
-
没有下文的束缚之后 ,next token的预测可以无止境地进行下去,只要每次将新预测的token和上文拼接起来做下一次预测即可(在专业术语里我们称之为「自回归」,这个特性其实并没有直接体现在训练中,而是在应用阶段,后文我会再提到)
「出题方式」确定了,那么预训练的「题库」从何而来呢?其实稍稍想想就会发现题目随处可得。一切文字的记录都可以生成 NTP 的「完形填空」,只需要取一段文本并在任意位置截断,断点左侧作为上文,断点右侧第一个字作为答案,其余内容扔掉,我们就得到了一道填空题(训练数据):
👉 哈利·波特是一部脍炙人口的魔幻小说系列作品,主角是一个名叫哈利·波特的年|轻巫师,他在11岁的时候才发现自己是巫师。
按照这样的方式,任何文本数据不论类型、语种,都能够生成大量的训练数据。OpenAI几乎爬取了互联网上能够获取的全部文本语料,可想而知由此构建的「题库」是多么庞大。
接下来,大模型就开始了漫长的「刷题」之路。随着模型预先初始化时的参数量不同,这个过程耗时几周到几个月不等。完成之后,我们便得到了第一阶段训练的成果——一个具备了超强文本生成能力的基础大模型。我们可以把这个阶段的它认为是一个十分会「接话」的「话唠」,只要给出任意的上文,它都可以进行下一个 token 的预测,配合上面提到的「自回归」方法,理论上我们可以让它一直预测生成下去。加上每次的预测它其实都可以给出多个最可能的 next token,那么如果我们每轮都在多个候选的基础上继续,就可以发散出许多丰富多样的生成结果,下面是一个直观的图示(画图太费劲,这里就偷懒从论文里扒了个英文的图来借用了🤣)。
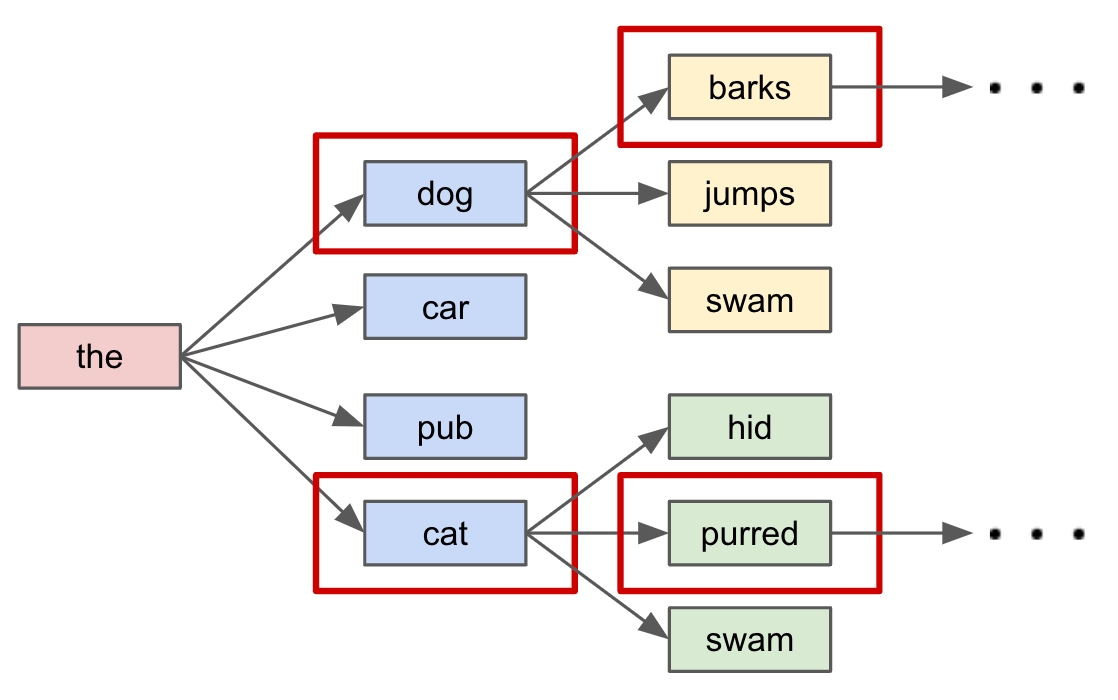
这一节的最后提一下,巨量的「题库」是大模型生成能力习得的关键之一,另一个关键是模型的参数量(大家不妨简单地类比为脑神经元的数量),只有这二者都具备一定的规模时模型才能涌现出卓越的能力,这也是大模型之「大」的由来。至于这个现象的原因,就要涉及到大模型的「Scaling Law」理论,这里我就不展开了,感兴趣的话大家可以自行探索。
大模型的「深造」
上面的「话唠」距离我们现在看到的 ChatGPT 之类的 AI Assistant 还有很大的差距,因为它还不能很好地理解来自人类的指令,为了实现这一点就需要借助第二阶段的训练对它进行「深造」了。沿用前面的比喻来讲,这个阶段更像是针对诸多更高级的「特定题型」(任务)进行的「专项训练」,专业的叫法是「SFT(Supervised Finetuning)」。比如下面这个是要求对一组物体进行分类的简单任务(「例题」):
{
"instruction": "通过对给定的物品列表进行聚类,创建一个分类任务。",
"input": "苹果,橙子,香蕉,草莓,菠萝",
"output": "类别 1:苹果,橙子\n类别 2:香蕉,草莓\n类别 3:菠萝",
"text": "以下是一个描述任务的指令,配对一个提供进一步上下文的输入。写一个适当地完成请求的答案。\n\n### 指令:\n通过对给定的物品列表进行聚类,创建一个分类任务。\n\n### 输入:\n苹果,橙子,香蕉,草莓,菠萝\n\n### 答案:\n类别 1:苹果,橙子\n类别 2:香蕉,草莓\n类别 3:菠萝",
}
这里的 instruction、input、output 就好比是「例题」的题干、条件以及标准答案,最后会通过一个模板合并成 text 文本。通过人工撰写+标注的方式构造了大量的这类「例题」,量级在几十到几百万,虽然远不及前面预训练阶段,但由于是人工生成且对质量有很高的要求,因此成本也是相当高昂的。这些「例题」涵盖了各类我们希望大模型掌握的主流「题型」(任务),例如翻译文本、根据要求写代码、对文本进行重点总结、知识问答等等等等。
这些高质量的 text 会用和前面的预训练阶段一样的方式让大模型进行学习,但这次它以这些高质量「例题」的「题干」和「条件」作为上文进行NTP,不断地让自己的输出内容接近「标准答案」,从而「习得」了这些五花八门任务的解决方法(其实还是一种纸上谈兵)。那么当我们以同样的表达方式(模板)给出希望大模型解答的问题的时候,它便更有可能照葫芦画瓢地给出类似的解答过程。而这里通用的「表达方式」或者说「模板」就是我们常常耳闻的 Prompt。
大家肯定在不少地方看到过关于 Prompt 模板的分享,教大家如何借助高质量的 Prompt 来给大模型 assistant 下达指令,得到更优质的反馈。这些高质量的 Prompt 模板一般都描述简洁清晰且表达更接近前面的 SFT 数据集。这其实也很好理解,当拿到的新「题目」越是和「题库」里曾经练习过的「例题」雷同,大模型自然越能举一反三地套用「解题思路」来更好地完成答题。
大模型的「模拟考」
其实截止到上一阶段,我们就已经得到了一个可以帮助我们解决问题的大模型 AI assistant 了。但在同等参数和训练数据量级下,有些 assistant的能力却优于其它,原因是它们还进行了下一个阶段的训练,技术上把这个阶段称为 RLFH(Reinforcement Learning Human Feedback),即人类反馈强化学习,而延续前面的比喻来说,我愿称之为「模拟考」。
这个阶段其实还分为了两个步骤。
首先,在大模型之外又训练了一个RM(Reward Model) 即奖励模型,它的参数量级远小于大模型本身且并不会根据指令给出反馈,事实上它只进行一项任务,那便是对大模型生成的内容打分。大家可以把这个 RM 看作一个无情的「阅卷老师」,会严格地对大模型的「解题」过程和结果进行评估,给出一个客观的得分。篇幅有限, RM 的训练方式这里也不继续展开了。
接下来在这个 RM 的监督之下,大模型再次重复上一阶段的做题过程,但要尽可能地从「阅卷老师」手里获得更高的得分,这也是为何我将这个阶段比作「模拟考」了。解答思路、过程、最终答案等处处都是得分点,只有各个环节都尽力做到最优,才能最终获得高分,这也就迫使大模型在输出反馈的时候必须精益求精。
经历了「模拟考」洗礼的大模型,更大程度地发挥了自己的能力,自然在面对人类指令时能获得更好的效果。这个阶段其实还有一个重要的「得分点」——生成内容的安全性,但其本质上和大模型的能力无关,所以放到以后的篇章里再做分享。
小结
大模型的炼成之路就介绍到这里了,是不是像极了一个应试教育学子的成长历程。实际的实现过程其实涉及到了许多复杂的概念和技术,这里为了能更白话地阐释原理,我使用了很多简化的类比,难免有失严谨,若有专业人士路过还请多多担待。如果我的文章能让一些非专业领域内的朋友对大模型的原理有一个初步的理解,那也就达到我的目标了。
欢迎大家关注+转发+点赞👻

















 745
745











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











