







论文地址:Semantic Image Synthesis with Spatially-Adaptive Normalization
一篇很有意思的文章,是NVIDIA公司出品,讲语义图像合成的改进,使用了一个space的normalization

语义图像合成就是给一个语义图像,如上图的第一行,然后使用这个语义图像合成现实图像

目前呢,normalization分为两种,一种是uncondition的,就如Instance Normalization、Layer Normalization (LN) 、Group Normalization (GN) 、andWeight Normalization(WN),Batch Normalization等,就是使用输入来进行权重的学习,然后作用到输入上
还有一种是condition的,是使用额外的输入(condition)来进行权重的学习,然后作用在输入上
图2就是本文所提出的方法,叫做SPatially-Adaptive(DE)normalization1 (SPADE),跟batch normal一样,是作用在channel上的
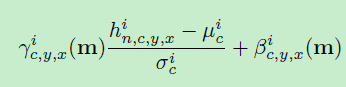 ,用公式表达就是这样
,用公式表达就是这样
如图所示,就是先对输入进行一个batch normal,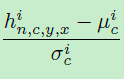 也就是这个部分,对于输入进行一个均值和方差的计算
也就是这个部分,对于输入进行一个均值和方差的计算
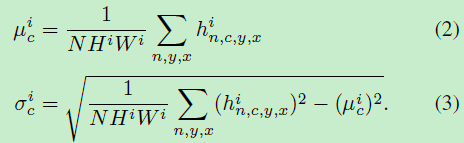 ,然后进行归一化,随后使用额外的输入(condition)来进行
,然后进行归一化,随后使用额外的输入(condition)来进行 和
和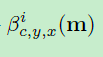 这两个参数的学习,注意,这两个参数在batch normal中是一个vector,也就是不包含空间信息的,在SPADE中是一个tensor,也就是包含空间信息的,然后这两个参数是使用conv来学习到的,最后将进行归一化的输入对这两个参数进行element-wise的相乘和相加,得到最后的输出
这两个参数的学习,注意,这两个参数在batch normal中是一个vector,也就是不包含空间信息的,在SPADE中是一个tensor,也就是包含空间信息的,然后这两个参数是使用conv来学习到的,最后将进行归一化的输入对这两个参数进行element-wise的相乘和相加,得到最后的输出
其实这个SPADE的方法,给我的感觉,就是一个attention模块嵌入到了batch normal中
文中提到说,SPADE有效的原因,最直接的是因为可以更好的直接提供语义信息,在每次normal都使用到了原始的语义信息
因为这个SPADE的方法,因此本文的网络就不再需要encoder了

整个网络的结构如上图所示,原始的生成网络都是用encoder-decoder的模式,比如pix2pixHD,先使用多个下采样进行encoder,然后在使用上采样进行decoder得到最后的结果,本文的生成网络只需要decoder,在每一步SPADE的时候,用上语义信息















 2031
2031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









