





 论文介绍了一种名为SPADE的方法,用于解决语义图像合成中归一化层处理语义信息的问题。通过学习性地调整归一化过程,SPADE允许激活在生成网络中更好地保留语义布局。实验在COCO-Stuff, ADE20K和Cityscapes上展示了优越的合成效果。生成器简化设计,多模态合成和风格迁移应用广泛。
论文介绍了一种名为SPADE的方法,用于解决语义图像合成中归一化层处理语义信息的问题。通过学习性地调整归一化过程,SPADE允许激活在生成网络中更好地保留语义布局。实验在COCO-Stuff, ADE20K和Cityscapes上展示了优越的合成效果。生成器简化设计,多模态合成和风格迁移应用广泛。
论文笔记:SPADE(CVPR 2019)-Semantic Image Synthesis with Spatially-Adaptive Normalization
SPADE DEMO

github地址:SPADE
demo的github地址:Imaginaire
Semantic Image Synthesis with Spatially-Adaptive Normalization.
Project page | Paper | Online Interactive Demo of GauGAN | GTC 2019 demo | Youtube Demo of GauGAN
Taesung Park, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu.
In CVPR 2019 (Oral).
前言
因为在之前的方法中直接将语义分割布局作为输入输入到网络进行处理会使得归一化层将语义信息抹去,为了解决这个问题,本文提出了使用输入布局来通过一个空间自适应、学习的转换来调节归一化层中的激活的方法,可以有效地在整个网络中传播语义信息。
本文在COCO-Stuff,ADE20K和Cityscapes上进行了实验。
语义图像->真实图像
Spatially-adaptive denormalization


输入一张语义分割图mask投影到插入空间,通过卷积产生调制参数γ和β。不同于以往的条件归一化方法,这里的γ和β是tensor类型的参数,具有空间维度的信息,再以element-wise的方式相乘并加到归一化的activation上。


m是语义分割图,N是一个batch的样本,Ci是第i层的通道,Hi是第i层的activation map的高,Wi是第i层的activation map的宽,hi代表对一批N样本的深度卷积网络第i层的activation,
μ
c
i
\mu_c^i
μci和
σ
c
i
\sigma_c^i
σci是第i层上通道c的activation的均值和方差。
γ
c
,
y
,
x
i
(
m
)
\gamma_{c,y,x}^i(m)
γc,y,xi(m)和
β
c
,
y
,
x
i
(
m
)
\beta_{c,y,x}^i(m)
βc,y,xi(m)是归一化层的学习调制参数,他依赖语义分割图并随位置
(
y
,
x
)
(y,x)
(y,x)变化。本文用
γ
c
,
y
,
x
i
(
m
)
\gamma_{c,y,x}^i(m)
γc,y,xi(m)和
β
c
,
y
,
x
i
(
m
)
\beta_{c,y,x}^i(m)
βc,y,xi(m)表示在第i层的activation map转换为
(
c
,
y
,
x
)
(c,y,x)
(c,y,x)的比例值和偏差值的函数。
本文使用简单的两层卷积网络实现
γ
c
,
y
,
x
i
(
m
)
\gamma_{c,y,x}^i(m)
γc,y,xi(m)和
β
c
,
y
,
x
i
(
m
)
\beta_{c,y,x}^i(m)
βc,y,xi(m)(附录)。
SPADE generator
使用SPADE时,不需要将语义分割图提供给生成器的第一层,因为学习的调制参数已经编码了足够的关于标签布局的信息。因此,本文丢弃了生成器的编码器部分,简化成了更加轻量级的网络。新的生成器可以将随机向量作为输入,从而实现一个简单而自然的多模态合成方法。

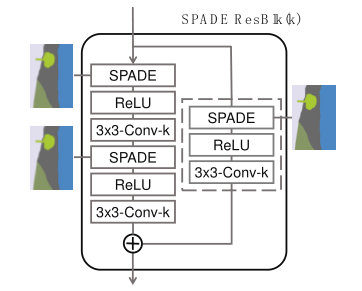
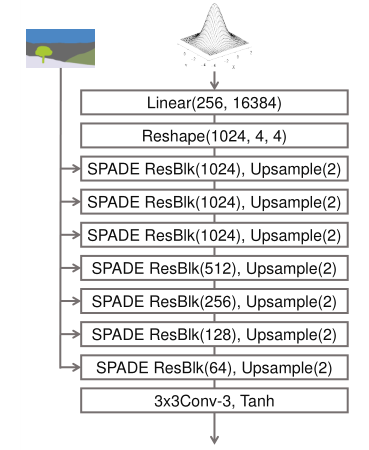
本文使用的生成器架构使用了几个带有上采样层的ResNet blocks,所有归一化层的调制参数由SPADE学习得到。由于每个residual block在不同的尺寸下运行,所以本文对语义分割图进行下采样来匹配residual block的空间分辨率。
生成器使用与pix2pixHD相同的多尺度判别器和除了最小平方损失之外的损失函数,将最小平方损失换成了hinge loss。
左图是SPADE ResBlk,在每个归一化层使用原始语义分割图调制activation。右图为生成器的架构图,去掉了pix2pixHD的下采样部分,并在每个上采样层使用SPADE ResBlk,并拥有比pix2pixHD更少的参数量。
SPADE discriminator

本文使用的判别器基于pix2pixHD使用的判别器,使用语义分割图与真是图像的连接为输入。
Multi-modal synthesis
附加一个编码器,将真实图像编码成随机向量,输入到生成器中,与生成器形成一个VAE,其中编码器尝试捕获图像的样式,生成器通过SPADE将样式和语义分割的信息结合以重建原始图像。编码器在测试时用作捕获目标图像的样式,以实现风格迁移。在训练中,添加了KL散度损失。

本文的图像编码器包含一系列步长为2的卷积层,最后通过两个linear层输出一个均值向量 μ \mu μ和方差向量 σ \sigma σ

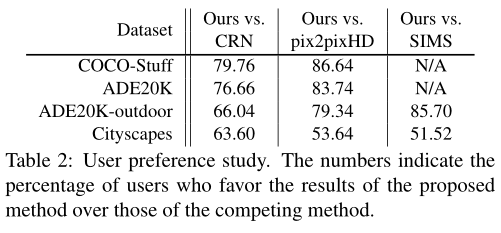
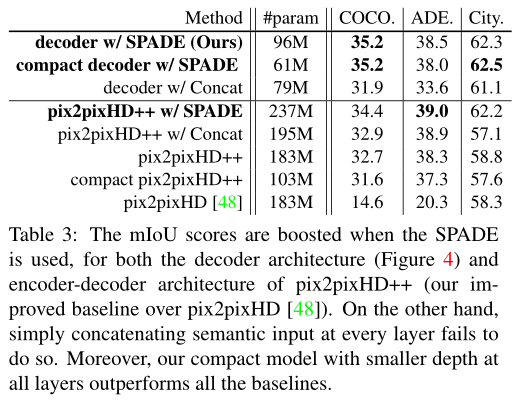
实验结果


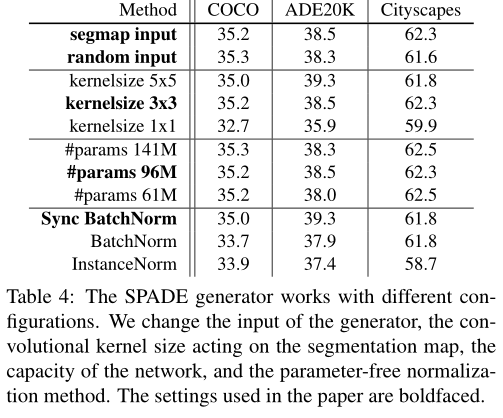

















 2679
2679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









