







前言
Normalization在深度学习中往往指的是对激活层的输入进行归一化。
BN(batch normalization)

论文:Batch Normalization: Accelerating Deep Network Training b
y Reducing Internal Covariate Shift
目的:加快学习速率,避免梯度消失的问题。
internal covatiate shift:统计学习中的一个很重要的假设就是输入的分布是相对稳定的。如果这个假设不满足,则模型的收敛会很慢,甚至无法收敛。所以,对于一般的统计学习问题,在训练前将数据进行归一化或者白化(whitening)是一个很常用的trick。但这个问题在深度神经网络中变得更加难以解决。在神经网络中,网络是分层的,可以把每一层视为一个单独的分类器,将一个网络看成分类器的串联。这就意味着,在训练过程中,随着某一层分类器的参数的改变,其输出的分布也会改变,这就导致下一层的输入的分布不稳定。分类器需要不断适应新的分布,这就使得模型难以收敛。对数据的预处理可以解决第一层的输入分布问题,而对于隐藏层的问题无能为力,这个问题就是Internal Covariate Shift。 而Batch Normalization其实主要就是在解决这个问题。
除此之外,一般的神经网络的梯度大小往往会与参数的大小相关(仿射变换),且随着训练的过程,会产生较大的波动,这就导致学习率不宜设置的太大。Batch Normalization使得梯度大小相对固定,一定程度上允许我们使用更高的学习率。

注意点:测试阶段BN的均值和方差不再是基于batch计算的,而是使用固定的统计参数(根据训练阶段各mini-batch计算出的均值和方差得到

在训练的时候会不断计算一个滑动均值和方差供测试时使用。sample_mean和sample_var是当前样本的计算结果,running_mean和running_var是保存的上轮batch的计算结果。 测试时直接用训练时保存的结果进行计算。
BN的正则化效应:测试时的归一化的均值和方差都是通过训练期间的滑动均值得到,所以训练时的不确定性会被平均并且带给测试时的归一化过程,
LN(layer normalization)


论文:https://arxiv.org/pdf/1607.06450.pdf
IN(instance normalization)


CIN(conditional instance normalization)
论文:A Learned Representation for Artistic Style
介绍:IN是学习一个单一的仿射参数集(
γ
\gamma
γ和
β
\beta
β).而CIN是为每个风格学习一个仿射参数集。 多种风格训练网络应该是很多种风格的一些计算是可以共享的,譬如一些印象派的绘画其实有相似的笔触只是颜色不同而已,如果用之前的方法训练一系列N个风格单独的模型肯定是比较浪费的。因此,论文提出了训练一个条件风格转移网络来支持多种风格。这里主要的区别就是这一个网络是一个条件网络,它的输入是除了之前的content 图片还需要有个需要应用的style的id,但同时支持N-style风格。具体做法就是在模型化一个风格时,对每个具体的风格在归一化之后进行特定的缩放和平移。

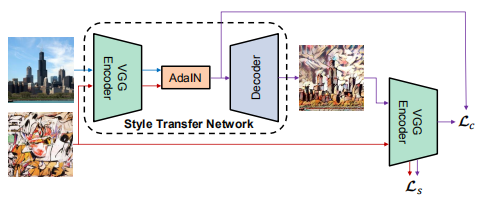
AdaIN(adaptive instance normalization)
论文:Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
介绍:AdaIN中没有可学习的仿射参数,即仿射参数不是通过学习得到。AdaIN接收两个信息源:内容输入
x
x
x和风格输入
y
y
y,将
x
x
x的通道级(channel-wise)均值和标准差匹配到
y
y
y的通道级均值和标准差上:
A
d
a
I
N
(
x
,
y
)
=
σ
(
y
)
(
x
−
μ
(
x
)
σ
(
x
)
)
+
μ
(
y
)
A d a I N(\mathbf{x}, \mathbf{y})=\sigma(\mathbf{y})\left(\frac{\mathbf{x}-\mu(\mathbf{x})}{\sigma(\mathbf{x})}\right)+\mu(\mathbf{y})
AdaIN(x,y)=σ(y)(σ(x)x−μ(x))+μ(y)
SPADE(spatial adaptive normalization)
论文:Semantic Image Synthesis with Spatially-Adaptive Normalization
论文链接:https://openaccess.thecvf.com/content_CVPR_2019/papers/Park_Semantic_Image_Synthesis_With_Spatially-Adaptive_Normalization_CVPR_2019_paper.pdf
论文解决的任务:在给定一张语义分割图时合成对应的实际图像,英文名为semantic image synthesis
出发点:在传统的图像到图像的迁移模型中,类似pix2pix或者pix2pixHD这样的算法中都是将语义分割图直接作为生成网络的输入进行计算,而这些生成网络中常用的传统归一化层(BN)容易丢失输入语义图像中的信息,因此提出了新的归一化层:Spatially-Adaptive Normalization来解决这个问题

SPADE是在BN的基础上做了修改,bn的
γ
\gamma
γ和
β
\beta
β都是网络预测值,并且都是单维的向量,向量的每个值代表对应维度。在SPADE中,
γ
\gamma
γ和
β
\beta
β是三维的,由通道维度还有宽和高维度组成,因此公式1中
γ
\gamma
γ和
β
\beta
β下标包含c,y,x三个符号,这也是spatially-adaptive的含义,翻译过来就是在空间上是有差异的,或者叫自适应的。假如是BN,那么γ和β的下标只有c,也就是通道,显然,BN这种不区分空间维度的计算方式容易丢失输入图像的信息。















 5248
5248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









