






0. 引言
vLLM(Virtualized Language Learning Model)是一种用于自然语言处理(NLP)的模型框架,旨在提高大规模语言模型(如GPT等)推理的性能和效率。
论文看这里:《Efficient Memory Management for Large Language Model Serving with PagedAttention》
代码看这里:https://github.com/vllm-project/vllm
本文结合论文详细介绍下为什么需要 vLLM,以及 vLLM 内部的原理是什么,带来了哪些提升。
1. 现状
在模型推理时, GPU 的内存分配如下: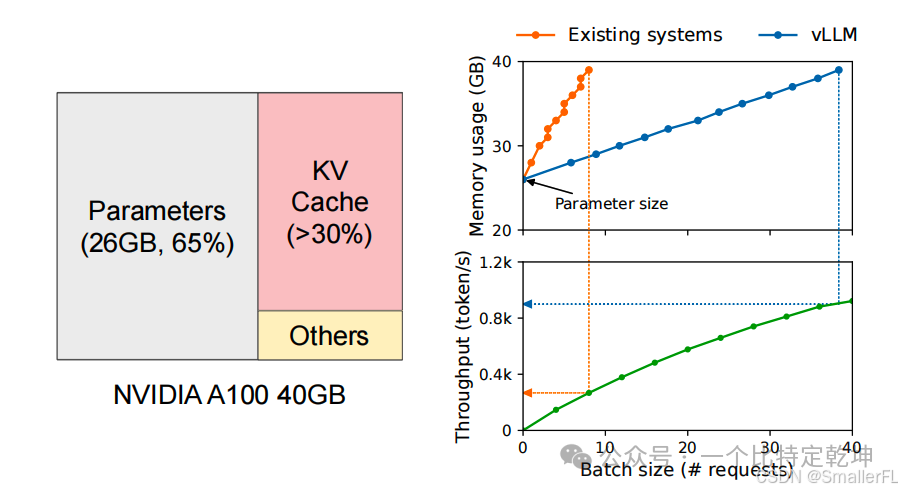 其中:
其中:
(1)Parameters 保留权重等参数,是静态的,这部分无法优化;
(2)KV Cache 是 Transformer 的 attention 机制引入的中间缓存,这部分下面会详细说明;
(3)Others 是临时激活函数使用,占用比例较小,优化空间不大。
从上面 GPU 的内存分配来看,KV Cache 是影响推理吞吐量的瓶颈,如果 KV Cache 管理不好,导致一次推理输出的数量太少,就会导致推理速度降低。
2. 技术前提
下面介绍 LLM 依赖的技术,了解技术前提才能看清 LLM 推理时会存在哪些问题。
2.1 基于 Transformer
现在的 LLM 基本上都基于 Transformer,如果不是基于Transformer,那么 vLLM 这套机制恐怕不能生效。
简单列出关键公式,注意力机制公式如下:

其中:

上面向量的维度情况:

2.2 自回归生成
大模型一般是基于语言模型,即根据前面的语句预测下一个字的概率:


这里的 、 向量涉及到 KV Cache 的核心,缓存的就是这些向量。
3. 存在哪些问题
3.1 KV Cache 太大
LLM 服务需要为每个请求维护一个键值(KV)缓存,用于存储模型在生成文本时的上下文信息。随着请求数量的增加,KV缓存的大小迅速增长,占用大量 GPU 内存。
对于13B 参数的模型,单个请求的 KV Cache 可能就需要数 1.6 GB的内存。这限制了同时处理的请求数量,进而限制了系统的吞吐量。
3.2 复杂的解码算法
LLM 服务通常提供多种解码算法供用户选择,如贪婪解码、采样解码和束搜索(beam search)。这些算法对内存管理的复杂性有不同的影响。
例如,在并行采样中,多个输出可以共享相同的输入提示的 KV 缓存,而在束搜索中,不同候选序列的KV缓存可以部分共享,这要求内存管理系统能够动态调整内存分配。
3.3 未知的输入和输出长度
LLM 服务的输入和输出长度是变化的,这要求内存管理系统能够适应不同长度的提示。随着请求的输出长度在解码过程中增长,所需的 KV 缓存内存也会增加,可能会耗尽用于新请求或现有的内存。
现有的 LLM 服务系统通常采用静态连续内存分配策略,会带来三个方面的内存浪费: (1)预留浪费(reserved)。为每个请求预留最大可能序列长度的内存,然而实际请求的长度可能远小于最大长度;
(1)预留浪费(reserved)。为每个请求预留最大可能序列长度的内存,然而实际请求的长度可能远小于最大长度;
(2)内部碎片(internal fragmentation)。内存分配的低效率还会导致内存碎片,进一步降低内存的可用性;
(3)外部碎片(external fragmentation)。有些内存由于过小,无法使用,这些内存则直接浪费了。
4. vLLM 方案
为了解决这些挑战,vLLM 提出了一种新的注意力算法 PagedAttention,并构建了一个高效的内存管理系统:KV Cache Manager,通过分页技术来管理 KV Cache,从而提高内存的利用效率,减少内存浪费,并支持更复杂的解码算法。这种方法允许在非连续的物理内存中存储连续的键和值,使得内存管理更加灵活,能够更有效地处理 LLM 服务中的内存挑战。
下面是 vLLM 的架构: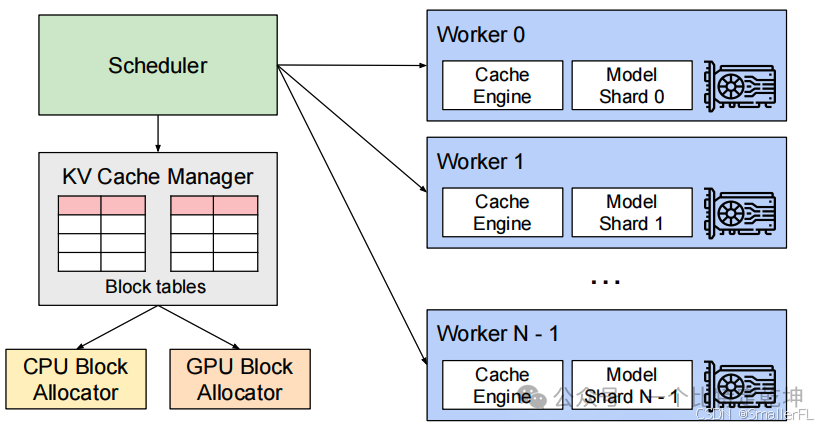
4.1 PagedAttention
PagedAttention 是一种受操作系统中虚拟内存和分页技术启发的注意力算法。它允许将连续的 和 向量存储在非连续的内存空间中。这一点与传统的注意力算法不同,后者通常要求 和 向量在内存中连续存储。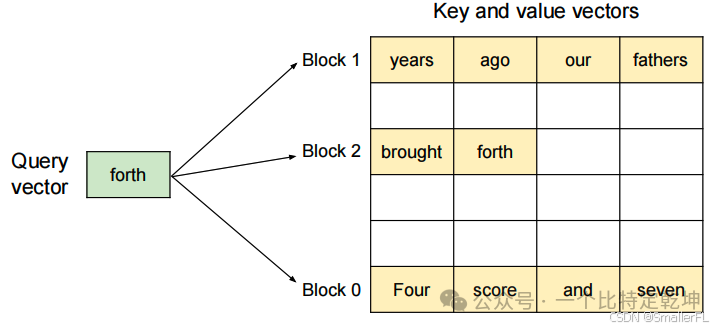
算法原理:(1)KV缓存分块:PagedAttention 将每个序列的 KV Cache 划分为多个 KV 块(KV blocks)。每个块包含了固定数量的 token 的 和 向量。(2)非连续存储:与传统方法不同,PagedAttention 允许这些 KV 块在物理内存中非连续地存储。这种设计使得内存管理更加灵活。(3)按需分配:PagedAttention 按需分配 KV 块,这减少了内存碎片,并允许跨请求或同一请求内不同序列之间的内存共享。
4.2 KV Cache Manager
KV Cache Manager 是 vLLM 系统中的一个核心组件,负责以分页的方式高效管理 KV Cache。这一管理器的设计灵感来源于操作系统中的虚拟内存管理技术,特别是分页机制。
主要功能:
(1)逻辑与物理块映射:它维护一个块表(block table),记录逻辑 KV 块与物理 KV 块之间的映射关系。这种分离允许动态地增长 KV Cache 内存,而无需预先为其所有位置分配内存。
(2)动态内存分配:KV Cache Manager 根据需要动态地分配物理 KV 块,这消除了现有系统中的大部分内存浪费。
(3)内存共享:通过页级内存共享,KV Cache Manager 支持在不同请求之间共享 KV Cache,进一步减少内存使用。
下面是一个例子说明 KV Cache Manager 和 PagedAttention 的工作机制: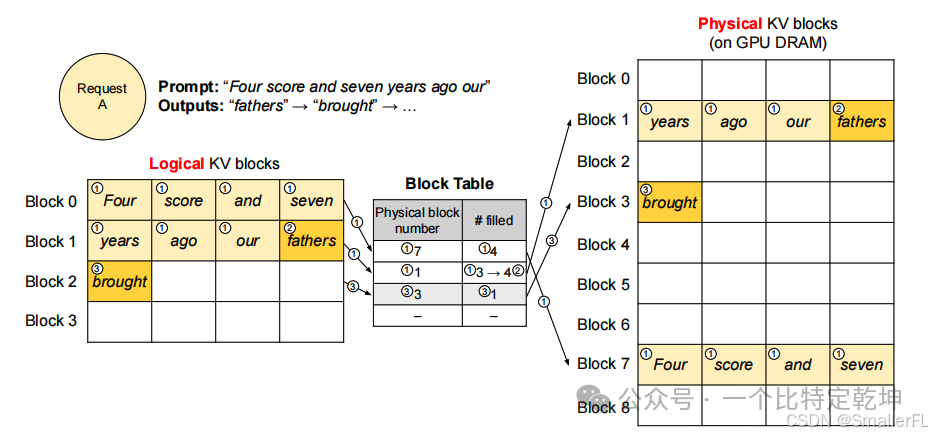 (1)一个 Block 最大存储 4 个 token。开始输入
(1)一个 Block 最大存储 4 个 token。开始输入Four score and seven years ago our 一共7个token,因此逻辑 KV 块 Block 0 填充前4个,对应于物理 KV 块的 Block 7;剩下3个 token 填充逻辑 KV 块 Block1,对应于物理 KV 块的 Block 1,但是并没有填满,对应的 Block Table 的 #filled 写入3;
(2)当自回归生成下一个 token fathers 后,物理 KV 块的 Block 1 同时写入,并且对应的 Block Table 的 #filled 由 3 改写成 4;
(3)自回归生成下一个 token brought 后,流程类似,不再赘述。
4.3 其他解码场景
4.3.1 Parallel sampling
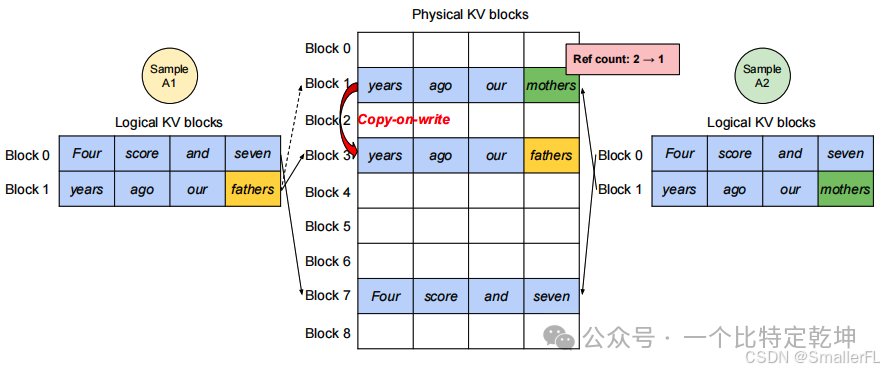 (1)有 A1 和 A2 并行采样,A1 和 A2 的逻辑 Block 0 的内容一致,实际上在物理 KV 块中只会存一份,对应 Block 7,此时 Block 7的引用计数是 2;
(1)有 A1 和 A2 并行采样,A1 和 A2 的逻辑 Block 0 的内容一致,实际上在物理 KV 块中只会存一份,对应 Block 7,此时 Block 7的引用计数是 2;
(2)当 A1 和 A2 的 Block 1 都是 years ago our 时,对应于物理 KV 块的 Block 1,此时 Block 1的引用计数是 2;
(3)在生成阶段时,A1、A2 生成下一个字的结果不一样,A1 是 fathers 而 A2 是 mothers,这样 Block 1 会触发写时复制(copy on write),复制一份到 Block 3,同时 Block 1 填入 mothers,Block 3 填入 fathers。Block 1的引用由2计数减1,变成1。
4.3.2 Beam search
与并行解码不同,束搜索(beam search)不仅支持共享初始提示块,还支持不同候选之间的其他块共享,并且随着解码过程的推进,共享模式会动态变化,类似于操作系统中由复合分叉创建的进程树。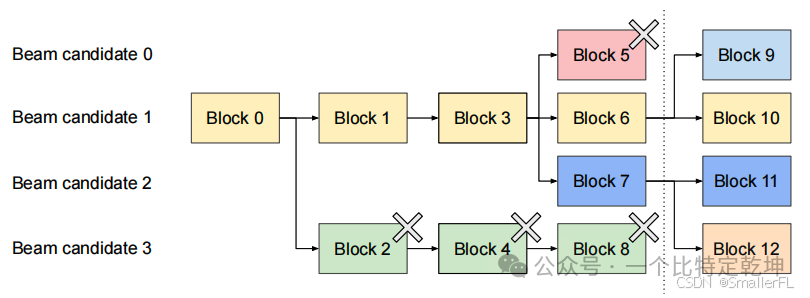
根据上图,介绍 vLLM 如何管理 Beam search 的 KV 块其中束宽 k = 4。
(1)图中,虚线左边是迭代之前,右边是迭代后的结果
(2)在虚线所示的迭代之前,每个候选序列已经使用了4个完整的逻辑块。
Beam candidate 0 是 Block 0 -> Block 1 -> Block 3 -> Block 5
Beam candidate 1 是 Block 0 -> Block 1 -> Block 3 -> Block 6
Beam candidate 2 是 Block 0 -> Block 1 -> Block 3 -> Block 7
Beam candidate 3 是 Block 0 -> Block 2 -> Block 4 -> Block 8
所有束候选共享第一个块,即 Block 0。从第二个块开始,候选3与其他候选不同。候选0-2共享前3个块,并在第4个块处发散。
(3)在虚线所示的迭代之后,所有块(Block9~12)都来自于候选1和2。由于原始候选0和3不再在候选之列,它们的逻辑块被释放,相应物理块的引用计数减少。vLLM 释放所有引用计数达到0的物理块(Block 2、4、5、8)。然后,vLLM 为新候选分配新的物理块(Block 9-12)来存储新的 KV 缓存。
(4)现在,所有候选共享Block 0、1、3;候选0和1共享Block 6,候选2和3进一步共享 Block 7。
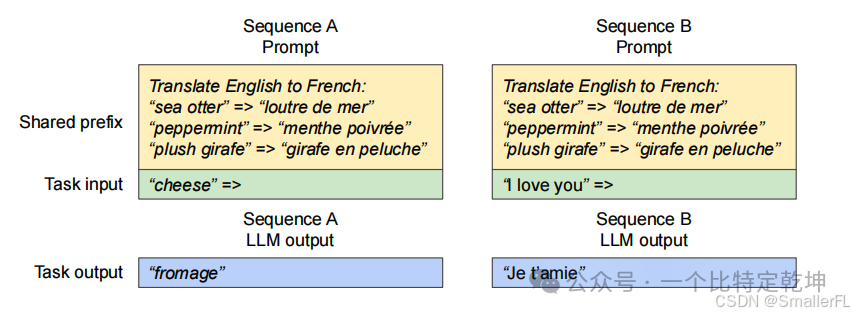
4.3.3 共享前缀
共享前缀是指在多个用户请求中重复出现的文本序列,这些序列通常位于请求的开始部分。在大型语言模型的应用中,如机器翻译或聊天机器人,用户经常提供包含指令和示例输入输出的长描述。这些描述被连接到实际任务输入以形成请求的提示(prompt)。
 在这里插入图片描述
在这里插入图片描述
vLLM 系统通过以下方式优化 共享前缀 的处理:
(1)预存储KV缓存:vLLM 可以预先存储共享前缀的 KV Cache,这样在处理包含该前缀的请求时,就不需要重新计算这部分的 KV Cache,从而减少冗余计算。
(2)映射逻辑块到物理块:在用户输入提示包含共享前缀时,vLLM 可以将提示的逻辑块映射到预先缓存的物理块。这样,只有用户特定任务输入的部分需要在模型中进行处理。
(3)提高效率:通过这种方式,vLLM 可以更高效地利用内存和计算资源,因为共享前缀的计算只需进行一次,而不是在每个请求中重复进行。
共享前缀的应用场景包括:
(1) 机器翻译:用户可能会提供一个包含翻译指令和几个示例翻译对的长描述。这些描述的开始部分(即共享前缀)在多个请求中是相同的。
(2)聊天机器人:在聊天应用中,用户与机器人的交互历史可能会被用作上下文,以便生成更准确的响应。这些交互历史的一部分可能会在多个请求中重复出现。
5. 结论
 在这里插入图片描述
在这里插入图片描述
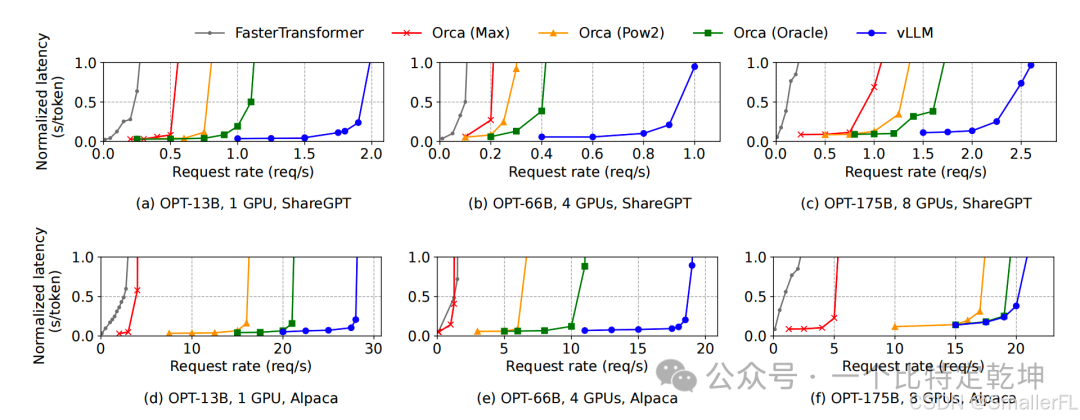
评估表明,与 FasterTransformer 和 Orca 等最先进的系统相比,vLLM 在相同的延迟水平下将流行 LLM 的吞吐量提高了2-4倍。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 1096
1096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









