







Trick 1:CPU offload (CPU卸载)
用额外的通讯开销换取显存。对于模型计算的中间结果(activation,优化器状态等),暂时放到内存(CPU)中,计算需要的时候再放回显存(GPU)中,需要占用传输带宽;
Trick 2:checkpointing (recompute,重计算)
用额外的计算换取显存。即在前向传播时,删除一些暂时用不到的中间激活结果以降低内存,在反向传播时,再根据需要临时进行前向计算恢复;
Trick 3:量化压缩
量化通过减少参数表示的位数来减小模型存储量和计算量,通常会带来一定的模型精度的损失;
Trick 4:通信算子

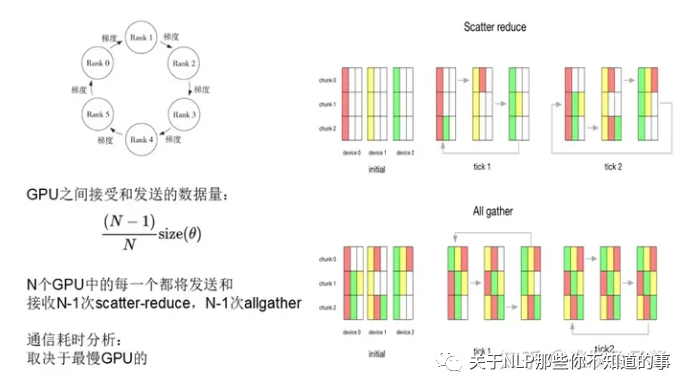
Trick 5:Ring ALL reduce
Scatter Reduce,每个服务器将参数分为N份,在相邻服务器传递,传递N-1次(Scatter),每个服务器将得到的参数累积起来(Reduce);
All Gather,将每一份参数的累积同步到所有服务器上去;
总的来说ALLreduce就是对所有服务器上的数据做一个规约操作(如最大值、求和),再将数据写入服务器,如图:
Trick 6:混合精度
模型通常使用float32精度进行训练,随着模型越来越大,训练的硬件成本和时间成本急剧增加。采用float16精度进行训练可以解决这一问题。但是随着模型的训练,梯度值太小小,超出float16表示的精度,导致权重都不再更新,模型难以收敛。
因此模型训练采用混合精度,即训练中模型权重以及梯度使用float16,优化器参数使用float32。同时优化器保存一份float32的权重,以及两个参数状态(均值和方差)。具体的更新步骤如下图:模型使用float16进行前向传播,计算损失值。然后反向传播得到float16的梯度;通过优化器将float16的梯度转化成float32精度的权重更新量;更新float32的权重;将float32的权重转换成float16;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









