






节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
AI 助手无缝地回忆过去的互动并将它们整合到正在进行的对话中的愿景推动了将聊天记录与LangChain集成,为提升对话人工智能体验提供了一种变革性的解决方案。
在本文中,我们将探讨将聊天记录纳入 LangChain 的复杂性,赋予AI系统利用过去互动获取丰富上下文和连贯性的能力。
通过对定义、好处、代码实现见解的探索,以及前瞻性的展望,我们揭示了这种整合的潜力,以塑造对话人工智能的未来。
定义
将聊天记录与 LangChain 集成,围绕着赋予AI系统记住过去对话并利用它们来影响当前交互的能力。它涉及将历史消息无缝地融入正在进行的对话中,为用户创造了丰富的交互画面。
整合的好处
将聊天记录与LangChain集成产生了多种好处,彻底改变了对话人工智能的格局:
增强上下文理解:通过利用过去的交互,AI系统能够更深入地理解用户查询,从而提供更加细致和与上下文相关的响应。
提高连贯性:无缝地整合聊天记录有助于在对话中保持连续性,消除了与独立交互经常相关的不连贯性。
个性化用户体验:通过访问历史数据,AI系统可以根据个人用户偏好和过去的交互定制响应,促进更加个性化和吸引人的体验。
高效任务执行:通过参考过去的讨论,AI系统可以简化任务执行,为用户提供及时和高效的帮助。
代码实现
将聊天记录与LangChain集成的实现需要一个结构化的方法:
步骤 I:安装库
%pip install --upgrade --quiet langchain langchain-community langchainhub langchain-openai chromadb bs4
步骤 II:初始化 OPENAI KEY
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
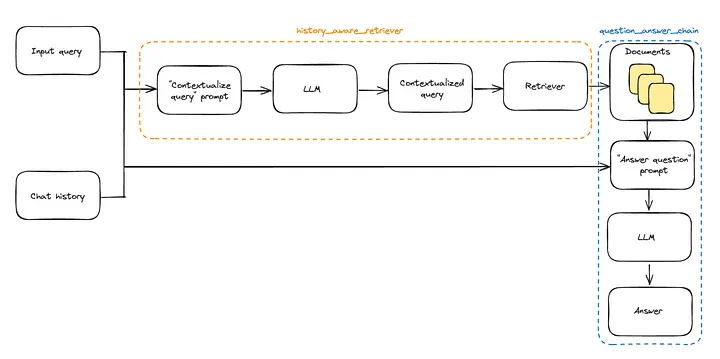
步骤 III:具有聊天记录的 Langchain
import bs4
from langchain import hub
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
### 构建检索器 ###
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
### 上下文化问题 ###
contextualize_q_system_prompt = """给定一个聊天记录和最新的用户问题,可能在聊天记录中引用上下文,请制定一个能够理解而不需要聊天记录的独立问题。如果需要,重新构思问题,否则返回原样。"""
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)
### 回答问题 ###
qa_system_prompt = """您是一个用于问答任务的助手。使用检索到的上下文来回答问题。如果不知道答案,只需说不知道。最多使用三个句子,保持回答简洁。\n\n{context}"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)
### 有状态地管理聊天记录 ###
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
conversational_rag_chain = RunnableWithMessageHistory(
rag_chain,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
output_messages_key="answer",
)
conversational_rag_chain.invoke(
{"input": "什么是任务分解?"},
config={
"configurable": {"session_id": "abc123"}
}, # 在 `store` 中构建一个键 "abc123"。
)["answer"]
输出:
'Task decomposition is a technique used to break down complex tasks into
smaller and simpler steps. This approach helps agents or models handle
difficult tasks by dividing them into more manageable subtasks. It can be
achieved through methods like Chain of Thought (CoT) or Tree of Thoughts,
which guide the model in thinking step by step or exploring multiple reasoning
possibilities at each step.'
结论
总的来说,将聊天记录与 LangChain 集成代表了对话式人工智能的范式转变,为用户提供了更加沉浸式和引人入胜的体验路径。通过利用过去交互的力量,AI 系统可以超越传统的界限,提供个性化、与上下文相关的回应,与用户在更深层次上产生共鸣。
随着我们继续推动人工智能创新的界限,将聊天记录与 LangChain 融合为对话式人工智能的无限潜力作证。拥抱交互式人工智能体验的未来,在那里每一次对话都是一次旅程,每一次交互都留下了深刻的印象。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 5727
5727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









