






因此今天给大家分享一个新的方法。也就是通过部署在本地的大模型进行文本内容提取。
安装 Ollama
通过 Ollama 可以快速在本地部署一些常用的大模型。可以根据自己的系统从这里安装下载:https://github.com/ollama/ollama
MacOS 下载 Ollama 链接: https://ollama.com/download/Ollama-darwin.zip
Windows 下载 Ollama 链接: https://ollama.com/download/OllamaSetup.exe
Windows 用户对安装有问题的可以参考这个推文:https://blog.csdn.net/scj0725/article/details/138087028
安装完之后就可以打开 DOS(Windows 用户)或 Terminal(Mac 用户)使用相应的模型了,这里使用的是 llama3.1 模型:
ollama run llama3.1
第一次运行的时候是安装改模型,会需要等待较长时间,后续再运行就很快了。默认安装的是 8B 参数的模型,还有 70B 和 405B 两种,这两个我也都试了,70B 的在我的电脑上运行速度极其慢(散热风扇狂转),405B 的完全无法运行,大家就不用再尝试了。
然后就可以进行提问和对话了:
如果有兴趣继续探索的话,也可以安装个用户界面(现在这种是命令访问)。
Mac 用户可以安装 Enchanted APP:
Windows 用户可以参考这个:https://github.com/open-webui/open-webui 安装用户界面,较为复杂。不建议尝试。
使用 API 调用
Ollama 可以通过 API 进行调用,这也是我们可以在 Stata 中调用的原因。打开 Ollama 之后就可以使用类似下面的 curl 语句进行调用了(在 Stata 中可以使用 !curl 调用 curl):
!curl http://localhost:11434/api/generate -d '{"model": "llama3.1", "prompt": "介绍一下微信公众号RStata", "stream": false}'
可以在结尾加上 -o temp.json 把输出的结果保存为 temp.json 文件:
!curl http://localhost:11434/api/generate -d '{"model": "llama3.1", "prompt": "介绍一下微信公众号RStata", "stream": false}' -o temp.json
提取历年政府工作报告中的经济增长目标
由此我们便可以提取历年政府工作报告中的经济增长目标了。附件中的 78-24政府工作报告 存放了 1978~2024 年历年的政府工作报告 txt 文件。首先我们把这些 txt 文件读取到 Stata 中:
*- 读取政府工作报告文本
clear all
set maxvar 12000
set obs 47
gen year = 1977 + _n
gen content = ""
forval i = 1/`=_N' {
local temp = fileread("78-24政府工作报告/`=year[`i']'.txt")
replace content = `"`temp'"' in `i'
}
*- content 里面包含了换行符,我们可以把换行符替换成空白
gen temp = ustrregexs(0) if ustrregexm(content, "\n")
replace content = subinstr(content, temp, "", .)
*- 去除空格和双引号
replace content = subinstr(content, " ", "", .)
replace content = subinstr(content, `"""', "", .)
drop temp
save mydata, replace
读取到的结果是这样的:
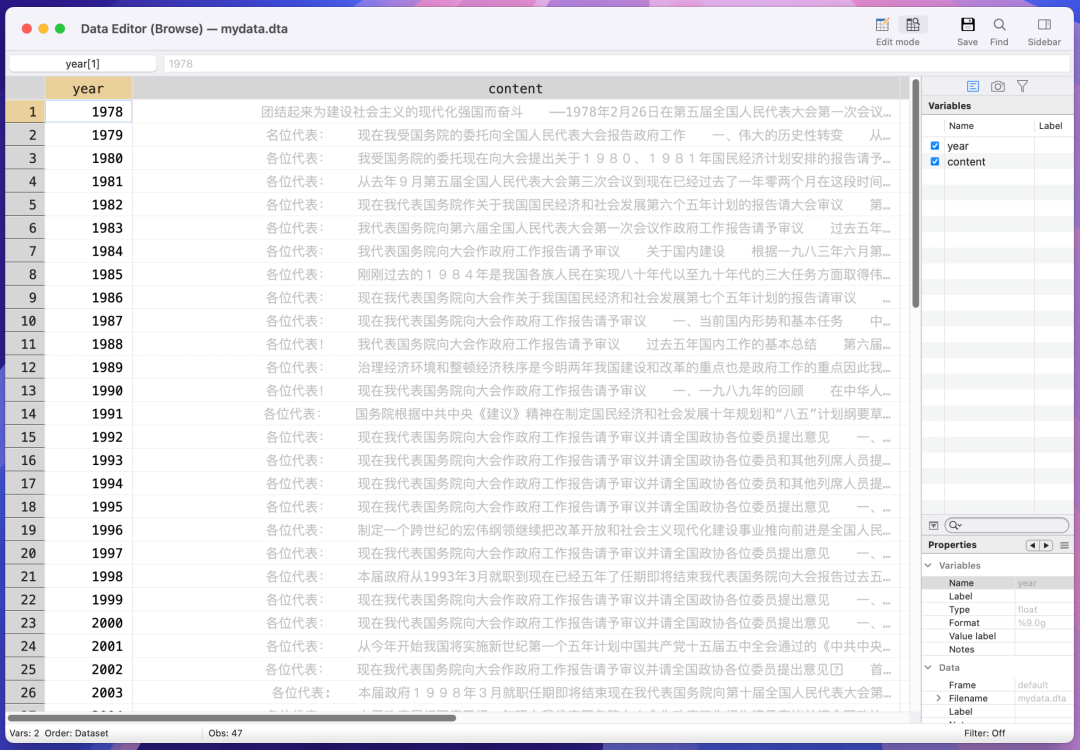
测试一个年份的
我们先随便找一个年份的报告文本测试下效果:
local temp = substr("`=content[20]'", 1, 3000)
!curl http://localhost:11434/api/generate -d '{"model": "llama3.1", "prompt": "提取下面文本中的经济增长预期目标并以一个两列的markdown表格展示,一列是目标类型,一列是目标的值,不要显示无用信息:“`temp'”", "stream": false}' -o temp.json
虽然这里没有输入文本长度的限制,但是输入太长的文本会返回无意义的结果,所以每次我只处理 1000 个字(由于每个汉字在 Stata 中的长度是 3,所以这里是 3000)。再读取处理得到的结果:
insheetjson using "temp.json", showr flatten
clear all
gen str1000 response = ""
insheetjson response using "temp.json", columns("response")
更多关于 json 文件处理的内容可以学习这个课程:
Stata 网络数据爬取:JSON篇:https://rstata.duanshu.com/#/brief/course/c6de9fae65df4eeb814d2275545e224d
然后我们循环处理该年的整篇报告文档:
use mydata, clear
di strlen("`=content[20]'")
*> 46776
cap mkdir "res20"
forval i = 1(3000)`=strlen("`=content[20]'")' {
if !fileexists("res20/`i'.json") {
local temp = substr("`=content[20]'", `i', 3000)
!curl http://localhost:11434/api/generate -d '{"model": "llama3.1", "prompt": "提取下面文本中的经济增长预期目标并以一个两列的markdown表格展示,一列是目标类型,一列是目标的值,不要显示无用信息:“`temp'”", "stream": false}' -o res20/`i'.json
}
}
这样所有的结果就都存放到 res20 文件夹里面了,再读取合并:
clear all
gen str1000 response = ""
local files: dir "res20" files "*.json"
local j = 0
foreach i in `files' {
insheetjson response using "res20/`i'", columns("response") offset(`j')
local j = `j' + 1
}
gen file = _n
order file

然后再稍加处理:
split response, parse("\n")
drop response
gather response*
drop if mi(value)
drop if !index(value, "|")
drop var
split value, parse("|")
drop value
drop value1
foreach i of varlist _all {
cap format `i' %10s
}
drop if index(value2, "---")
replace value2 = subinstr(value2, "*", "", .)
replace value2 = subinstr(value2, " ", "", .)
replace value3 = subinstr(value3, " ", "", .)
drop if value2 == "目标类型" | value2 == "类型"
drop if mi(value3) | value3 == "?"
ren value2 variable
ren value3 value
drop file
gen year = 1997
order year
save 1997提取结果, replace
list in 1/10
*> +----------------------------------------------------------------------------------------+
*> | year variable value |
*> |----------------------------------------------------------------------------------------|
*> 1. | 1997 提高就业率 开辟多种渠道扩大就业 |
*> 2. | 1997 加快城镇住房商品化 改善居民住房条件 |
*> 3. | 1997 完善出口退税制度 大力推行外贸代理制 |
*> 4. | 1997 维护国内市场竞争秩序 加强对外商投资企业的服务、管理和监督 |
*> 5. | 1997 稳步增长城乡人民收入 解决群众生活中的突出问题 |
*> |----------------------------------------------------------------------------------------|
*> 6. | 1997 提高对外开放水平 增加对外贸易持续增长保持进出口基本平衡 |
*> 7. | 1997 努力开拓新的市场 强化企业财务管理逐步建立会计师事务所审核制度 |
*> 8. | 1997 加强农村卫生基础设施建设 改善农村卫生基础设施建设防治地方病扩大广播电视覆盖面 |
*> 9. | 1997 解决温饱问题 助力发展生产解决温饱问题 |
*> 10. | 1997 新建住房面积 11亿平方米 |
*> +----------------------------------------------------------------------------------------+
这样就提取到了所有的相关结果。
循环所有年份的
在此基础上再循环所有年份:
use mydata.dta, clear
cap mkdir "res"
forval z = 1/`=_N' {
forval i = 1(3000)`=strlen("`=content[`z']'")' {
if !fileexists("res/`i'_`=year[`z']'.json") {
local temp = substr("`=content[`z']'", `i', 3000)
!curl http://localhost:11434/api/generate -d '{"model": "llama3.1", "prompt": "提取下面文本中的经济增长预期目标并以一个两列的markdown表格展示,一列是目标类型,一列是目标的值,不要显示无用信息:“`temp'”", "stream": false}' -o res/`i'_`=year[`z']'.json
}
}
}
这个过程可能会非常耗时,我用了一整夜才运行完。
然后合并所有的 json 文件:
clear all
gen str2000 response = ""
local files: dir "res" files "*.json"
local j = 0
gen file = ""
foreach i in `files' {
insheetjson response using "res/`i'", columns("response") offset(`j')
replace file = "`i'" in `=_N'
local j = `j' + 1
}
order file
save rawjsondata, replace
再整理下:
use rawjsondata, clear
split response, parse("\n")
drop response
gather response*
drop if mi(value)
drop if !index(value, "|")
drop var
gen v1 = ustrregexs(1) if ustrregexm(value, "(.+)\|(.+)")
gen v2 = ustrregexs(2) if ustrregexm(value, "(.+)\|(.+)")
drop value
foreach i of varlist _all {
cap format `i' %10s
replace `i' = subinstr(`i', "|", "", .)
replace `i' = subinstr(`i', "|", "", .)
replace `i' = subinstr(`i', "*", "", .)
replace `i' = subinstr(`i', "#", "", .)
}
drop if index(v1, "---")
drop if v1 == "目标类型" | v1 == "类型"
drop if mi(v2) | inlist(v2, "不明确", "不详")
ren file year
replace year = ustrregexs(1) if ustrregexm(year, "_(.*)\.")
destring year, replace
compress
foreach i of varlist _all {
cap format `i' %10s
}
save tidydata, replace
list in 1/10
*> +------------------------------------------------------------------------------------------+
*> | year v1 v2 |
*> |------------------------------------------------------------------------------------------|
*> 1. | 1978 目标类型 目标值 |
*> 2. | 1978 促进全国的安定团结达到天下大治 实现 |
*> 3. | 1978 抓纲治国战略决策一年初见成效的要求 成功实现 |
*> 4. | 1978 把我国建设成为农业工业国防和科学技术现代化的伟大的社会主义强国 本世纪内完成 |
*> 5. | 1978 在一个不太长久的时间内改变我国社会经济技术方面的落后状态 几十年内完成 |
*> |------------------------------------------------------------------------------------------|
*> 6. | 1978 把揭批“四人帮”这场伟大斗争进行到底 完成 |
*> 7. | 1978 恢复和发扬党的优良传统和作风 实现 |
*> 8. | 1978 巩固无产阶级专政的任务落实到基层 完成 |
*> 9. | 1978 提高我国的国际威望 空前提高 |
*> 10. | 1979 目标类型 目标的值 |
*> +------------------------------------------------------------------------------------------+
这样得到的是所有相关的结果,如果只想要经济增长率的目标,可以筛选下:
use tidydata, clear
keep if index(v1, "增长") & ustrregexm(v1, "(国民)|(经济)|(生产)|(GDP)")
keep if ustrregexm(v2, "%")
gsort year
drop if ustrregexm(v1, "(能源)|(工业)|(农业)|(播种)")
save 待手动筛选, replace
不过看起来还需要后续的手动筛选。不过相信到这里也能节省不少工作量了。特别是要处理的文档特别多的时候。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 6532
6532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









