






Whisper 是当前最先进的开源语音识别模型之一,毫无疑问,也是应用最广泛的模型。如果你想部署 Whisper 模型,Hugging Face推理终端能够让你开箱即用地轻松部署任何 Whisper 模型。但是,如果你还想叠加其它功能,如用于分辨不同说话人的说话人分割,或用于投机解码的辅助生成,事情就有点麻烦了。因为此时你需要将 Whisper 和其他模型结合起来,但对外仍只发布一个 API。
- 推理终端https://hf.co/inference-endpoints/dedicated
本文,我们将使用推理终端的自定义回调函数来解决这一挑战,将其它把自动语音识别 (ASR) 、说话人分割流水线以及投机解码串联起来并嵌入推理端点。这一设计主要受Insanely Fast Whisper的启发,其使用了Pyannote说话人分割模型。
- 自定义回调函数https://hf.co/docs/inference-endpoints/guides/customhandler
- Insanely Fast Whisperhttps://github.com/Vaibhavs10/insanely-fast-whisper#insanely-fast-whisper
- Pyannotehttps://github.com/pyannote/pyannote-audio
我们也希望能通过这个例子展现出推理终端的灵活性以及其“万物皆可托管”的无限可能性。你可在此处找到我们的自定义回调函数的完整代码。请注意,终端在初始化时会安装整个代码库,因此如果你不喜欢将所有逻辑放在单个文件中的话,可以采用 handler.py 作为入口并调用代码库中的其他文件的方法。为清晰起见,本例分为以下几个文件:
- 代码示例https://hf.co/sergeipetrov/asrdiarization-handler/
- handler.py : 包含初始化和推理代码
- diarizationutils.py : 含所有说话人分割所需的预处理和后处理方法
- config.py : 含 ModelSettings 和 InferenceConfig 。其中,ModelSettings 定义流水线中用到的模型 (可配,无须使用所有模型),而 InferenceConfig 定义默认的推理参数
从PyTorch 2.2开始,SDPA 开箱即用支持 Flash Attention 2,因此本例使用 PyTorch 2.2 以加速推理。
- PyTorch 2.2https://pytorch.org/blog/pytorch2-2/
主要模块
下图展示了我们设计的方案的系统框图:
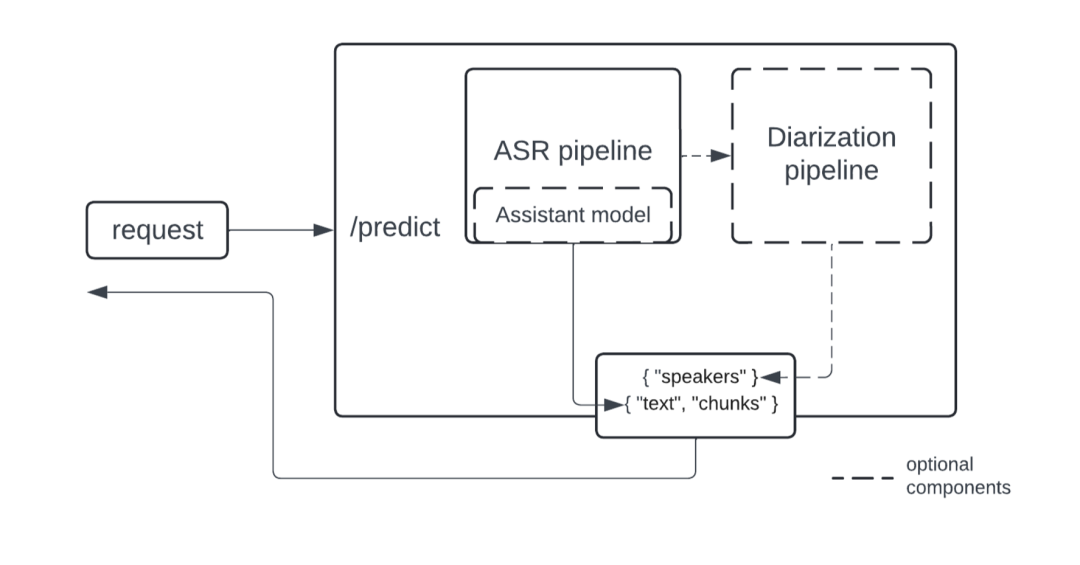 系统框图
系统框图
在实现时,ASR 和说话人分割流水线采用了模块化的方法,因此是可重用的。说话人分割流水线是基于 ASR 的输出的,如果不需要说话人分割,则可以仅用 ASR 的部分。我们建议使用Pyannote 模型做说话人分割,该模型目前是开源模型中的 SOTA。
- Pyannote 模型https://hf.co/pyannote/speaker-diarization-3.1
我们还使用了投机解码以加速模型推理。投机解码通过使用更小、更快的模型来打草稿,再由更大的模型来验证,从而实现加速。具体请参阅这篇精彩的博文以详细了解如何对 Whisper 模型使用投机解码。
- 使用推测解码使 Whisper 实现 2 倍的推理加速https://hf.co/blog/zh/whisper-speculative-decoding
投机解码有如下两个限制:
- 辅助模型和主模型的解码器的架构应相同
- 在很多实现中,batch size 须为 1
在评估是否使用投机解码时,请务必考虑上述因素。根据实际用例不同,有可能支持较大 batch size 带来的收益比投机解码更大。如果你不想使用辅助模型,只需将配置中的 assistantmodel 置为 None 即可。
如果你决定使用辅助模型,distil-whisper是一个不错的 Whisper 辅助模型候选。
- distil-whisperhttps://hf.co/distil-whisper
创建一个自己的终端
上手很简单,用代码库拷贝神器拷贝一个现有的带自定义回调函数的代码库。
- 代码库拷贝神器https://hf.co/spaces/huggingface-projects/repoduplicator
- 自定义回调函数https://hf.co/sergeipetrov/asrdiarization-handler/blob/main/handler.py
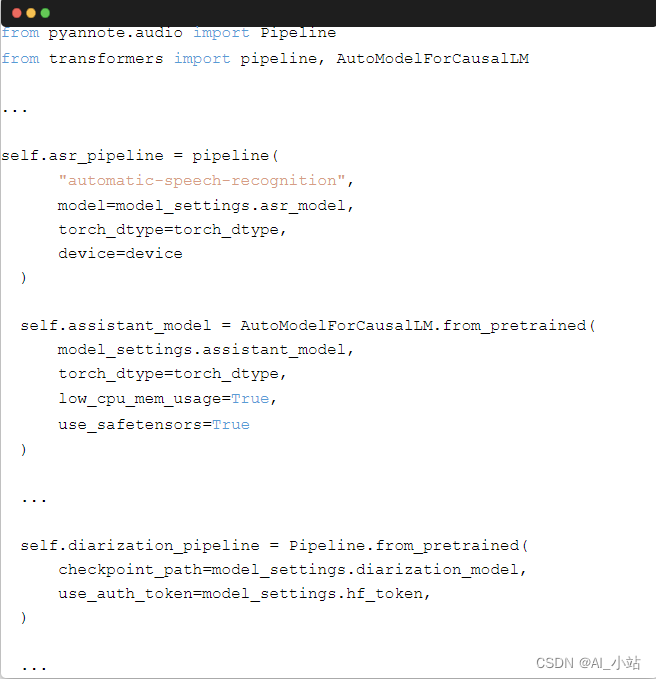
以下是其 handler.py 中的模型加载部分:
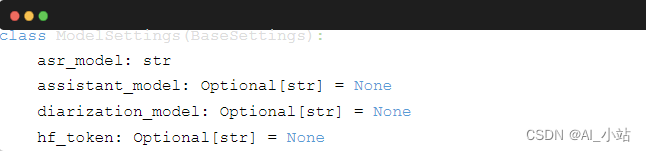
然后,你可以根据需要定制流水线。config.py 文件中的 ModelSettings 包含了流水线的初始化参数,并定义了推理期间要使用的模型:
如果你用的是自定义容器或是自定义推理回调函数的话,你还可以通过设置相应的环境变量来调整参数,你可通过Pydantic来达成此目的。要在构建期间将环境变量传入容器,你须通过 API 调用 (而不是通过 GUI) 创建终端。
- Pydantichttps://docs.pydantic.dev/latest/concepts/pydanticsettings/
你还可以在代码中硬编码模型名,而不将其作为环境变量传入,但 请注意,说话人分割流水线需要显式地传入 HF 令牌 (hftoken )。出于安全考量,我们不允许对令牌进行硬编码,这意味着你必须通过 API 调用创建终端才能使用说话人分割模型。
提醒一下,所有与说话人分割相关的预处理和后处理工具程序都在 diarizationutils.py 中。
该方案中,唯一必选的组件是 ASR 模型。可选项是: 1) 投机解码,你可指定一个辅助模型用于此; 2) 说话人分割模型,可用于对转录文本按说话人进行分割。
部署至推理终端
如果仅需 ASR 组件,你可以在 config.py 中指定 asrmodel 和/或 assistantmodel ,并单击按钮直接部署:
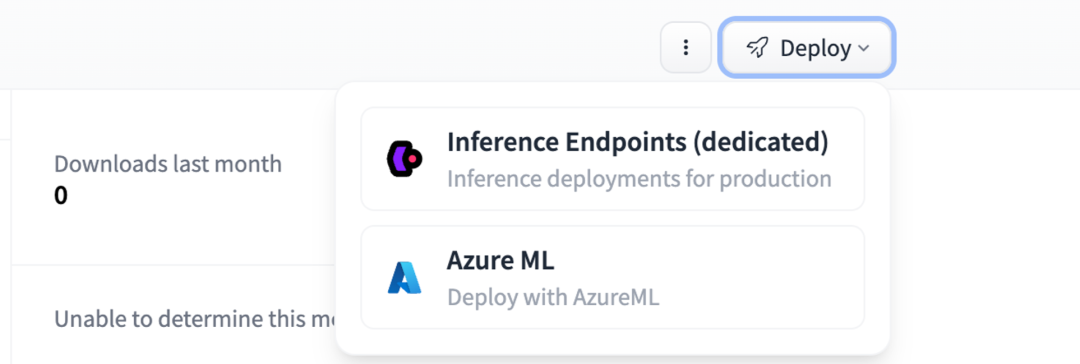 一键部署
一键部署
如要使用环境变量来配置推理终端托管的容器,你需要用API以编程方式创建终端。下面给出了一个示例:
- API 地址https://api.endpoints.huggingface.cloud/#post-/v2/endpoint/-namespace-

何时使用辅助模型
为了更好地了解辅助模型的收益情况,我们使用k6进行了一系列基准测试,如下:
- k6https://k6.io/docs/
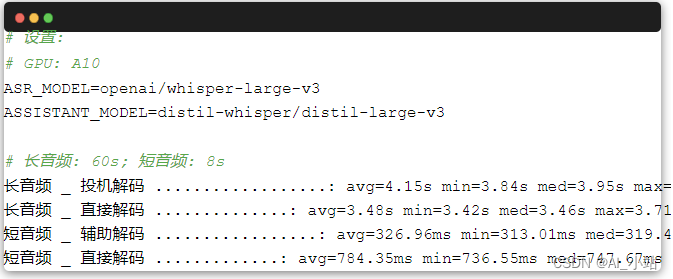
如你所见,当音频较短 (batch size 为 1) 时,辅助生成能带来显著的性能提升。如果音频很长,推理系统会自动将其切成多 batch,此时由于上文述及的限制,投机解码可能会拖慢推理。
推理参数
所有推理参数都在 config.py 中:
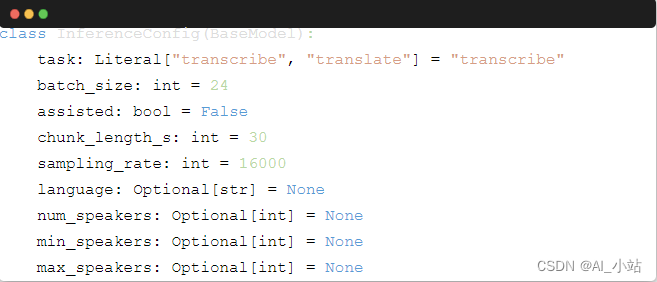
当然,你可根据需要添加或删除参数。与说话者数量相关的参数是给说话人分割流水线的,其他所有参数主要用于 ASR 流水线。samplingrate 表示要处理的音频的采样率,用于预处理环节; assisted 标志告诉流水线是否使用投机解码。请记住,辅助生成的 batchsize 必须设置为 1。
请求格式
服务一旦部署,用户就可将音频与推理参数一起组成请求包发送至推理终端,如下所示 (Python):
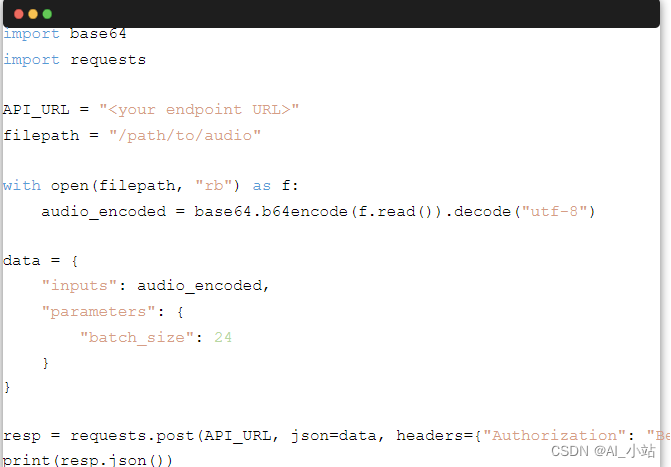
这里的 “parameters” 字段是一个字典,其中包含你想调整的所有 InferenceConfig 参数。请注意,我们会忽略 InferenceConfig 中没有的参数。
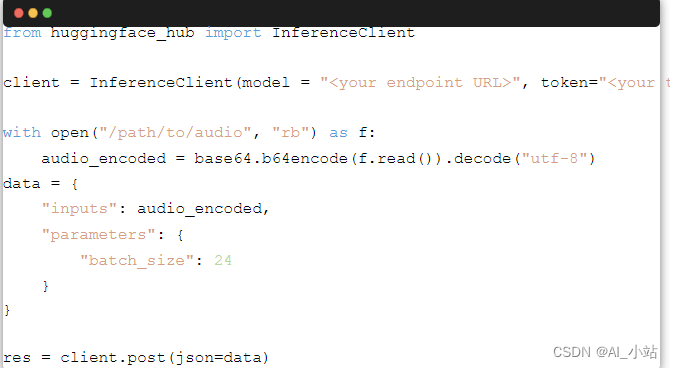
你还可以使用InferenceClient类,或其异步版来发送请求:
- InferenceClienthttps://hf.co/docs/huggingfacehub/en/packagereference/inferenceclient#huggingfacehub.InferenceClient
- 异步版https://hf.co/docs/huggingfacehub/en/packagereference/inferenceclient#huggingfacehub.AsyncInferenceClient
总结
本文讨论了如何使用 Hugging Face 推理终端搭建模块化的 “ASR + 说话人分割 + 投机解码”工作流。该方案使用了模块化的设计,使用户可以根据需要轻松配置并调整流水线,并轻松地将其部署至推理终端!更幸运的是,我们能够基于社区提供的优秀公开模型及工具实现我们的方案:
- OpenAI 的一系列Whisperhttps://hf.co/openai/whisper-large-v3模型
- Pyannote 的说话人分割模型https://hf.co/pyannote/speaker-diarization-3.1
- Insanely Fast Whisper 代码库https://github.com/Vaibhavs10/insanely-fast-whisper/tree/main,这是本文的主要灵感来源
本文相关的代码已上传至这个代码库中,其中包含了本文论及的流水线及其服务端代码 (FastAPI + Uvicorn)。如果你想根据本文的方案进一步进行定制或将其托管到其他地方,这个代码库可能会派上用场。
- Fast Whisper Server 代码库https://github.com/plaggy/fast-whisper-server
英文原文: https://hf.co/blog/asr-diarization
原文作者: Sergei Petrov,Vaibhav Srivastav,Pedro Cuenca,Philipp Schmid
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 588
588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









