







开源的检索增强型生成(RAG)模型随着对大型语言模型中增强功能需求的增长而变得越来越庞大。
那它们是什么呢?RAG模型是密集检索(DPR)和序列到序列模型的结合。其设计目的是通过引入外部知识来增强LLMs的能力。这是通过检索与查询相关的文档,并使用这些文档来作为上下文发给LLM以得到最终生成结果实现的。
这个过程允许RAG模型产生更准确和上下文相关的输出,因为检索和生成组件一起进行了微调。这种方法在知识密集型的自然语言处理(NLP)任务中特别有效,在开放域问答等领域树立了新的基准。
现在你们对RAG模型有了相当好的了解,让我们来看几个开源社区中的实例。
1、NeMo Guardrails
该模型由 NVIDIA 打造,提供了一个开源工具包,旨在为基于大型语言模型的对话系统引入可编程的防护措施,以确保交互的安全性和可控性。这些防护措施使开发者能够设定模型在特定主题上的行为准则,避免讨论不希望的话题,并确保遵循对话设计的最佳实践。
工具包兼容多个 Python 版本,并带来了诸多优势,包括构建值得信赖的应用程序、安全地集成模型以及对对话流程的控制能力。此外,它还包含了一系列保护机制,用以防范如越狱(jailbreaks)和提示注入(prompt injections)等常见的大型语言模型安全漏洞,并支持与多种大型语言模型及类似 LangChain 这样的其他服务进行集成,增强了其功能性。若要获取关于如何安装、使用该工具包以及可用的防护措施类型的更多详细信息,欢迎访问 NeMo Guardrails 的 GitHub 页面。

Github:https://github.com/NVIDIA/NeMo-Guardrails
2、LangChain
LangChain 是一个开源工具,它提供了一种强化大型语言模型(LLM)以实现检索增强型生成的方法。该工具通过在对话模型中加入检索步骤来提升LLM的回应质量。这样的集成使得模型能够动态地从数据库或文档集合中检索信息,从而使其回应不仅更准确,而且与上下文更加相关。
利用 LangChain 的功能,开发者能够开发出更智能的对话代理,这些代理能够接入并使用广泛的外部信息资源。想要深入了解如何通过 LangChain 实现检索功能,你可以访问它们的官方网站,那里提供了丰富的文档资料和实例,帮助你掌握如何有效利用这一工具。
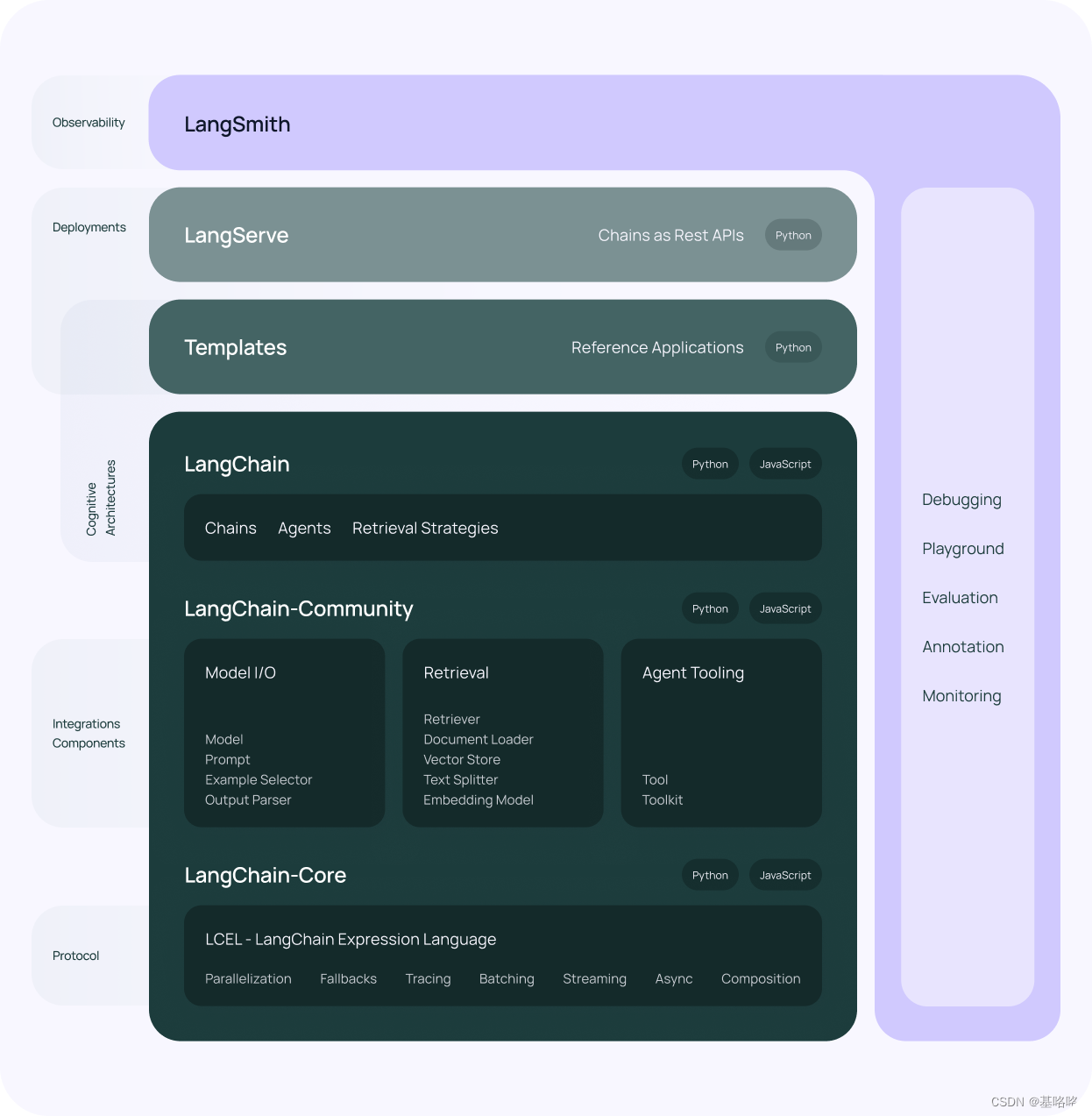
官方文档:RAG | 🦜️🔗 Langchain
3、LlamaIndex
LlamaIndex 是一个先进的工具包,专门用于构建检索增强型生成(RAG)应用程序,它赋予开发者通过查询和检索各种数据源中的信息来增强大型语言模型(LLM)的能力。该工具包推动了复杂模型的构建,这些模型能够访问、理解和整合来自数据库、文档集以及其他结构化数据源的信息。LlamaIndex 支持进行复杂的查询操作,并能够与其他人工智能组件无缝集成,提供了一种灵活而强大的解决方案,用于开发充满知识内涵的应用程序。
如果您想了解更多关于 LlamaIndex 的详细信息、掌握其高级概念并获取入门指南,建议您访问其官方文档。官方文档将为您提供全面的资源和指南,帮助您充分利用 LlamaIndex 工具包的强大功能,构建出更加智能和高效的应用程序。
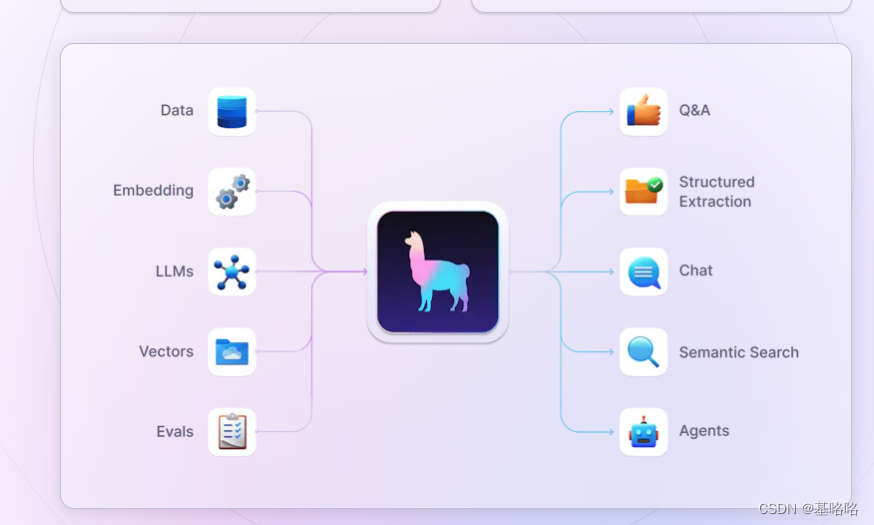
官网:LlamaIndex, Data Framework for LLM Applications
4、Verba
Verba 是一款得到 Weaviate 支持的开源检索增强型生成(RAG)聊天机器人。它通过提供一个端到端、用户友好的界面,极大地简化了用户探索数据集和提取有价值洞察的过程。Verba 支持本地部署,并且能够与 OpenAI、Cohere 和 HuggingFace 等大型语言模型(LLM)提供商进行集成,其易于设置和能够处理多种数据类型的多功能性使其在同类产品中显得尤为突出。
Verba 的核心功能涵盖了无障碍的数据导入、高效的高级查询处理能力,以及通过语义缓存技术来加速查询速度,这些都使得它成为构建复杂 RAG 应用程序的理想工具。无论是在数据的初始导入阶段,还是在后续的查询和分析过程中,Verba 都能提供稳定而高效的性能,帮助用户更好地利用大型语言模型的强大功能。
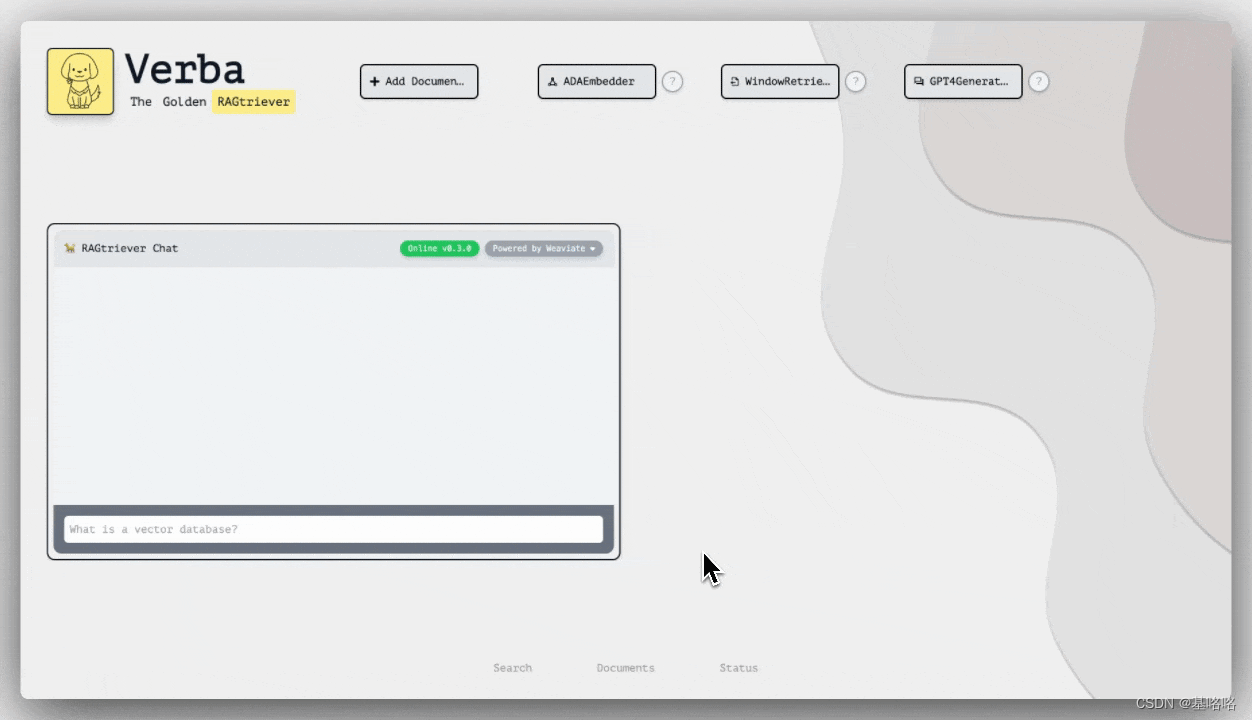
Github:https://github.com/weaviate/Verba
5、Haystack
该框架是一个全面的LLM编排工具,旨在构建高度可定制且适合生产环境的应用程序。它通过促进模型、向量数据库、文件转换器等多种组件的互联,将它们融合成一个能够与数据进行互动的统一管道。得益于其先进的检索技术,Haystack非常适合用于开发那些需要检索增强型生成、问题解答、语义搜索或对话代理功能的应用程序。Haystack采用了技术无关的方法,这样用户就能够根据项目需求自由选择或切换不同的技术解决方案和供应商,确保了最大的灵活性和适应性。

6、Phoenix
由 Arize AI 精心打造的 Phoenix 是一款专注于人工智能领域可观测性和评估的工具套件。它提供了一系列强大的工具,例如 LLM Traces,这些工具旨在帮助用户深入理解和高效排除大型语言模型(LLM)应用程序中的问题;同时,LLM Evals 工具则专注于评估应用程序的准确性和潜在的有害内容。
Phoenix 还提供了嵌入分析功能,允许用户深入探索数据集群和性能指标,同时支持 RAG(检索增强型生成)分析,以优化和提升检索增强型生成流程的效率和准确性。除此之外,Phoenix 还鼓励进行结构化数据分析,以便于进行 A/B 测试和漂移分析,从而确保模型的稳定性和可靠性。
Phoenix 倡导的以笔记本为中心的方法论,不仅适用于实验性项目的开发,也同样适用于生产环境的部署。这种方法强调了易于部署的特性,旨在为用户提供持续的可观测性和监控能力,确保人工智能系统的透明度和可控性。对于对 Phoenix 感兴趣的用户,可以在其官方 GitHub 页面上找到更多的详细信息和实用资源,以便更好地利用这一工具进行人工智能项目的管理和优化。
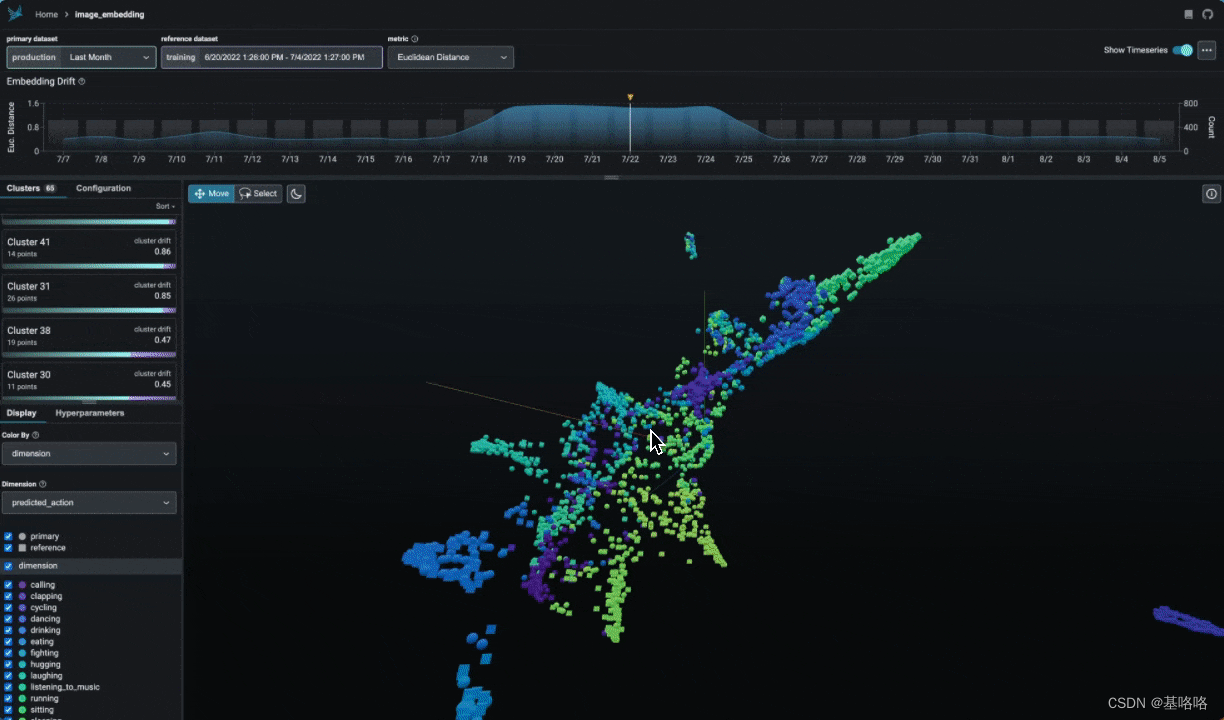
Github:GitHub - Arize-ai/phoenix: AI Observability & Evaluation
7、MongoDB
MongoDB 是一款高效、灵活的开源 NoSQL 数据库平台,其设计核心在于实现卓越的可扩展性和优化性能。通过采用文档导向的数据模型,MongoDB 能够兼容 JSON 风格的数据结构,为用户提供了高度的灵活性和流畅的数据处理体验。这种特性使得 MongoDB 在构建 Web 应用程序、进行实时数据分析以及处理大规模数据集等领域备受青睐。
此外,MongoDB 提供了强大的查询功能、全面的索引选项、数据复制和分片技术,确保了系统的高可用性和可伸缩性。对于热衷于在其项目中整合 MongoDB 的开发者和技术人员,他们可以在 MongoDB 的 GitHub 页面上获取更多详尽的信息和丰富的资源,以便更深入地了解和应用这一技术。

Github:https://github.com/mongodb/mongo
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 4832
4832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









