






在人工智能迅速发展的背景下,尤其是语言模型机器(LLMs)已成为许多应用的真正支柱,从自然语言处理和机器翻译到虚拟助手和内容生成。GPT-3及其继任者的出现标志着AI发展的一个重要里程碑,开启了一个时代,在这个时代中,机器不仅能理解,还能以惊人的熟练度生成类似人类的文本。然而,在这场AI革命的表面之下,隐藏着一个关键的缺失元素,这个元素有潜力解锁更大的AI能力:存储层。
关于LLMs的客观真理
让我们用一个LLM概述来设定背景。以下是过去几年中的一些亮点。
LLMs是有史以来最先进的AI系统
LLMs及其衍生作品有潜力改革许多行业和研究领域。例如,它们可用于创建更自然和吸引人的用户界面,开发新的教育工具,提高机器翻译的准确性。它们还可用于生成新的想法和见解,创造新的艺术和文学形式,这为语言和语言学领域开辟了新方向。
这些模型在基准测试上比以往任何时候都快地超越了人类水平:
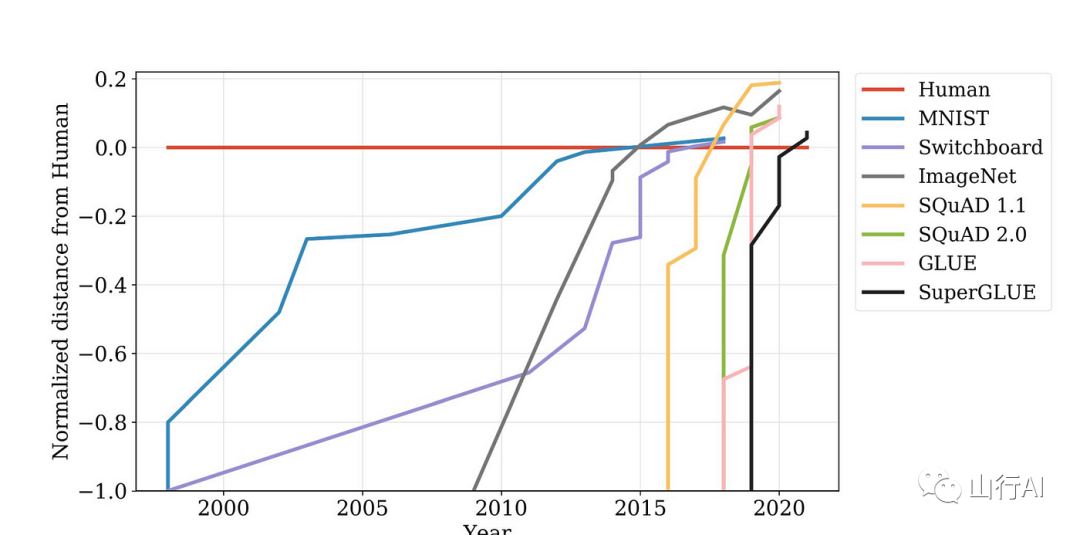
Kiela等。2021[1]
这些系统自信地说谎
尽管LLMs非常先进,在大多数情况下几乎不可能区分生成的文本和人类的回应,但这些系统遭受各种级别的幻觉。另一种说法是,这些系统自信地说谎,由于在生成方面的人类级熟练程度,这些谎言相当令人信服。
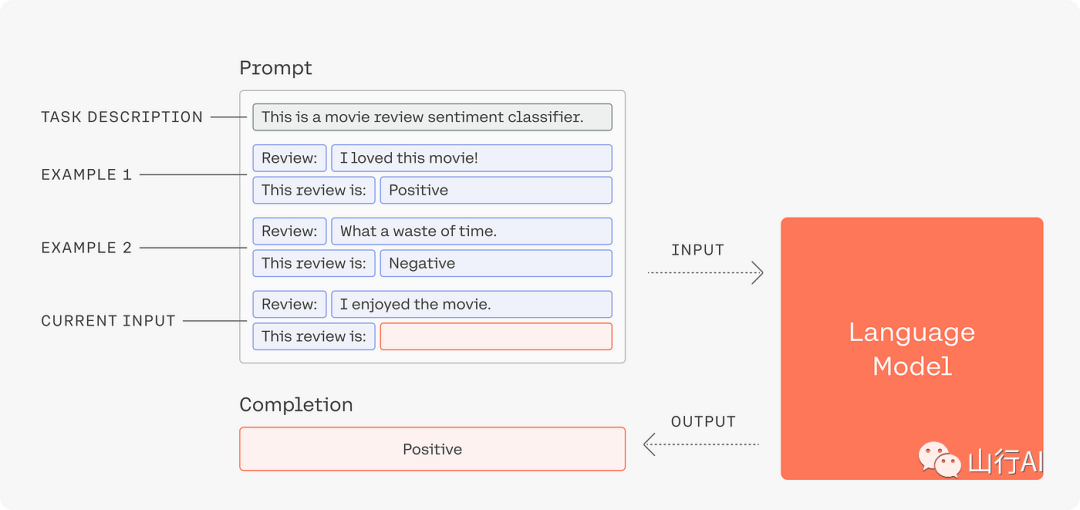
考虑与ChatGPT的这次互动

最初发表于 hackernews[2]
乍一看,这些结果似乎令人印象深刻,但一旦你关注链接,它们都指向404。这在各个层面上都是危险的:
•首先,因为这些链接看起来令人信服,有人可能会在不核查的情况下就将它们当做引用•最好的情况是你检查了第一个链接,并意识到它指向404,你会检查其他链接。•但最糟糕的情况是如果只有第一个链接真的存在,而你只检查了那个。这会让你相信所有链接都是有效的
这只是幻觉的一个例子,还有许多其他更微妙的例子,比如简单地编造事情。
最强大的LLMs依然是一个黑盒子
我个人不喜欢将“黑盒子”这个词用于所有深度学习,因为大多数模型都可以被轻易地解剖和修改。事实上,在大多数情况下,原始发布模型的修改版本更受欢迎且更有用。可解释性历来是个挑战,但这还不足以将这些模型称为黑盒子。但LLMs则不同。最强大的LLMs是闭源的,只能通过API请求访问。此外,由于培训成本高昂和专有数据集,没有足够的资源或工程专业知识来复制结果。这些确实符合黑盒子的定义。
最初发表在 cohere blog[3]
基于响应与基于表征的系统
在基于提示的方法中,你依赖LLMs直接从你(或你的用户)的查询中生成响应。使用LLMs生成响应非常强大,而且开始使用也很简单。但很快就会变得可怕,当你意识到你没有(也不能)控制这些系统的任何生命周期方面。结合上面讨论的客观真理,这很快就会成为一场灾难。
使用LLMs进行表征
如果我们不是端到端使用LLMs,而是仅仅使用它来表征我们的知识库怎么样?显而易见的方法是使用这些强大的模型来嵌入我们的数据库。你可以拥有一个捕获语义含义的非结构化数据的数值表示。
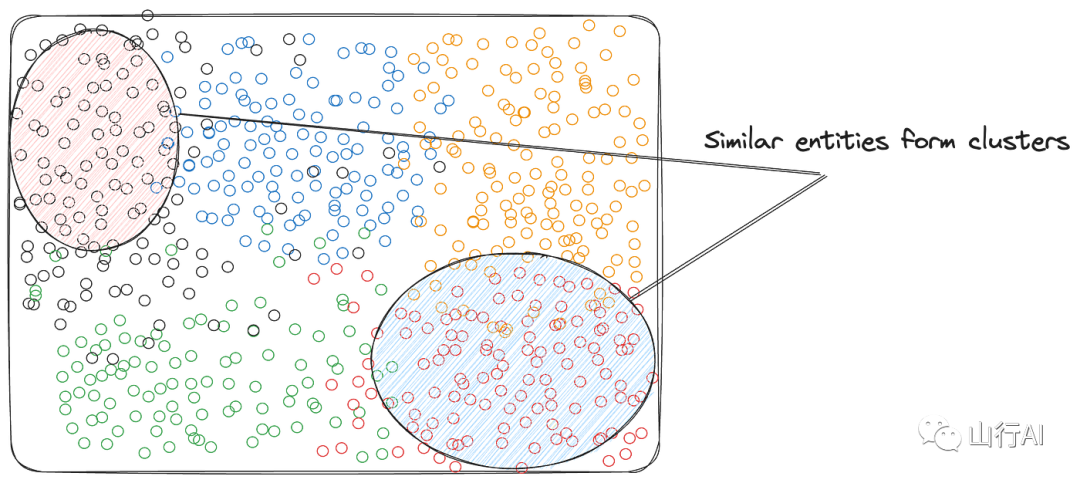
这些向量捕捉高维空间中实体之间的关系。例如,这里是一个词嵌入的例子,其中意义相近的词在空间中彼此靠近。
检索增强生成(RAG)
我们已经有了构建RAG系统所需的所有部件。在RAG设置中,我们不是使用LLMs从提示中生成响应,而是使用检索器检索相关表征,并通过提示LLM拼接它们以形成响应。
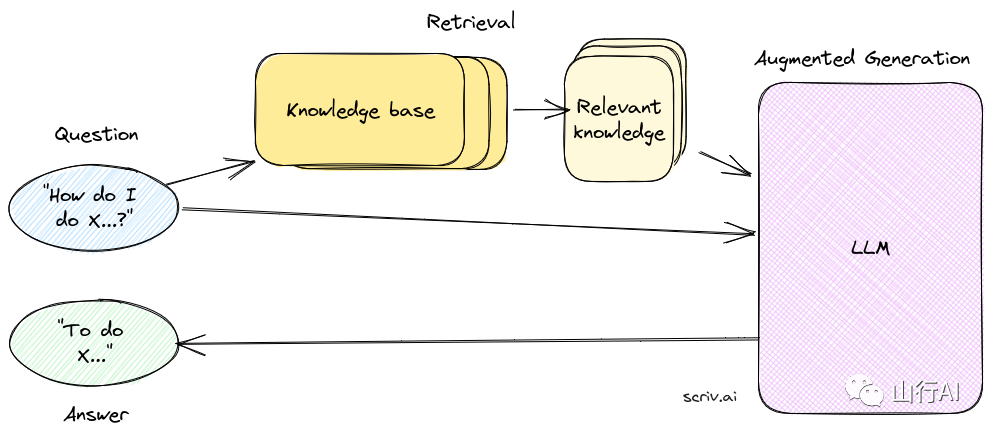
现在,你可以提供确切的引用,来自于用于生成响应的知识库文档。这使得可能追溯响应到其源头。
领域变化
我们到目前为止通过RAG实现的成就是我们减少了依赖LLM代表我们回答问题。相反,我们现在有了一个模块化的系统,它有不同的部分,每个部分独立运作:
•知识库•嵌入模型•检索器•响应生成器(LLM)
这导致领域的变化,我们从依赖黑箱AI转向由数十年研究支持的模块化组件
“只要它还不太行,那就是人工智能,一旦它开始运作,那就是计算机科学。”
自从我将近十年前听到这句话以来,它就一直萦绕在我心头。我认为这是埃里克·施密特说的,但我没能找到那确切的演讲。
总的想法是,现在我们已经以这样的方式改变了问题的领域:检索器成为系统的核心部件,我们现在可以利用计算机科学子领域的研究工作,如信息检索、排名等。
听起来我需要花费$$$?
成本取决于很多因素。现在让我们将注意力转移到部署的ML系统面临的共同问题,以及这种生成AI方法旨在解决它们的方式。
•可解释性 — 没有一种方法可以自信地解释深度神经网络,但这是一个活跃的研究领域。解释LLMs更为困难。但在RAG设置中,你可以分阶段构建响应,从而洞察决策的原因。•模块化 — 与端到端API可访问模型相比,模块化系统有很多优势。在我们的案例中,我们对什么进入我们的知识库以及它是如何随时间更新的,我们的检索器和排名算法的配置,以及我们用这些信息生成最终响应的模型有细粒度的控制。•(重新)训练成本 — LLMs(包括本地模型)的最大问题是庞大的数据和基础设施需求。这使得它们几乎不可能在新数据进来时重新训练。
例如,让我们考虑一个最近发生的事件,即在培训结束后(或更具体地说是数据集创建日期截止后)发生的事件。这里有一些问题,涉及几天前到几个月前发生的事件,问给ChatGPT。

(缺少8月23日chandrayaan-3的软着陆)
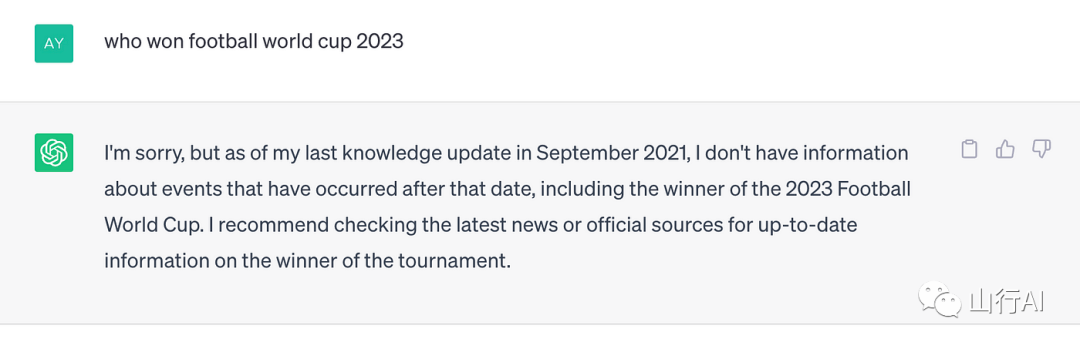
(缺少2022年世界杯结果)
信息在业务的一个子领域内的变化速率可能会更高,使得LLM很快就过时了。
如果同一个系统依赖于RAG系统,它只需要更新知识库,即通过嵌入模型运行新的事件/信息,其余部分将由检索器处理。另一方面,LLM将需要在直接响应式系统中对新数据进行再训练。
所以,这种方法不仅为您提供了更精细的控制和模块化,而且在新信息进来时更新也便宜得多。
微调Vs RAG
关于在特定领域数据上细调模型和使用RAG的通用模型哪个更好的辩论是没有意义的。当然,理想情况下,你想要两者兼得。在领域上细调的模型将提供更好的“通用”响应和上下文词汇。但你需要RAG模型来更好地控制和解释响应。
AI原生数据库的需求
此时很明显,需要一个维护良好的知识库。虽然有许多传统解决方案,我们需要重新思考AI解决方案。以下是主要要求:
•AI需要大量数据•模型正在变得多模态。数据需要跟上•扩展不应破坏银行。
多模态是下一个前沿,大多数LLM提供者要么计划支持多模态特性,要么他们已经在测试它们。
在考虑我们不需要在ML中发明又一个子领域的同时,利用现有工具和接口将是理想的选择。
LanceDB:AI原生、多模态、嵌入式向量数据库
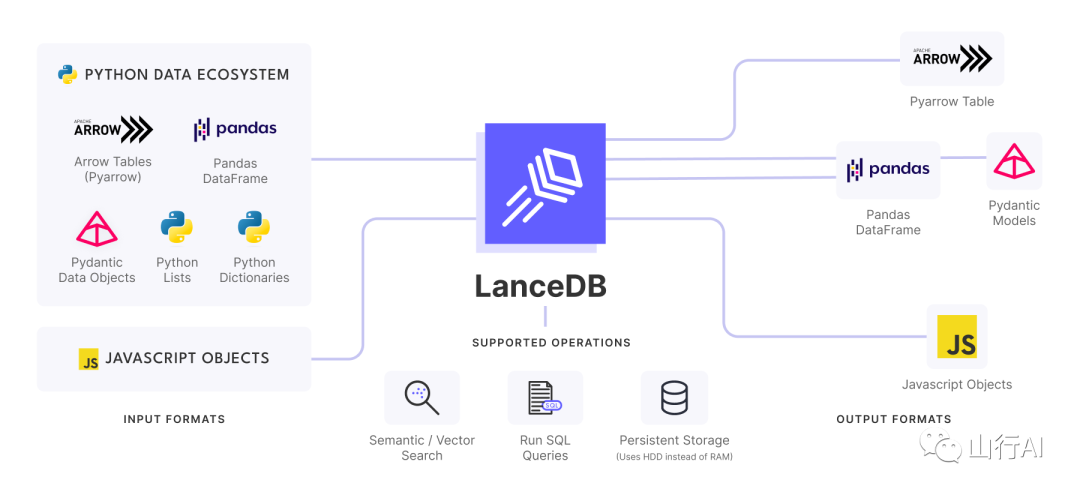
LanceDB是一个开源的向量搜索数据库,具有持久存储功能,极大地简化了嵌入的检索、过滤和管理。
np.array — 原始的向量DB
关于是否需要向量DB以及np.array是否满足所有向量搜索操作的需求,目前有一个持续的辩论。
让我们看一个使用np.array存储向量和查找相似向量的例子

这对于快速原型开发很有用**但这如何扩展到数百万条目?数十亿条目呢?**在大规模时将所有嵌入加载到内存中是否高效?多模态数据又如何?
理想的AI原生向量数据库解决方案应该是容易设置的,并且应该与现有API集成以便快速原型制作,但应该能够在不需要额外改变的情况下扩展。
LanceDB就是以这种方式设计的。作为无服务器,它不需要设置 — 只需导入并开始使用。持久存储在HDD中,允许计算存储分离,这样你就可以在不加载整个数据集到内存的情况下运行操作。与Python和Javascript生态系统的原生集成,允许从同一个代码库扩展从原型到生产应用。
计算存储分离
计算存储分离是一种设计模式,它在系统中解耦了计算资源和存储资源。这意味着计算资源不位于与存储资源相同的物理硬件上。计算存储分离有几个好处,包括可扩展性、性能和成本效益。
LanceDB — 嵌入式向量DB
以下是如何将上述示例与LanceDB集成的方式

这就是你需要做的,为任何规模的向量嵌入工作流程增强动力。LanceDB建立在Lance文件格式之上,这是一种用Rust实现的现代列式数据格式,专为ML和LLMs设计。
我们创建了一些基准测试,提供了lance格式性能的近似度量 — 达到了使用Lance相比Parquet的最高2000倍性能提升[4]
Lance中随机访问的基准测试[5]
在即将发布的博客中,我们将讨论LanceDB的工作原理,更多关于lance文件格式、lanceDB和我们构建AI存储层的愿景的技术细节。
访问LanceDB[6]或vectordb-recipes[7],给我们一个🌟
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 1117
1117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









