






前言
2023年9月,Microsoft Azure AI 在官方博客上发布了一篇题为《Azure 认知搜索:通过混合检索和排序能力超越向量搜索》的文章。
该文对在 RAG 架构的生成式 AI 应用中引入混合检索和重排序技术进行了全面的实验数据评估,量化了该技术组合对改善文档召回率和准确性方面的显著效果。
一张图表快速回顾关键字检索和向量检索的特点

从我们汇总的信息可以比较直观的看出,我们本文要专题分享混合检索的原因了。
什么是混合检索?
接下来我们就先来了解下到底什么是混合检索,可能从我们以上综合提到了两个检索方式,也已经能推断出来了。
没错,在RAG系统中,混合搜索最常见指向量检索和关键词检索的组合。在不同场景中,实际应用会有不同方式,从概念上讲:混合检索是结合了两种或者多种搜索算法提高搜索结果相关性的搜索技术。
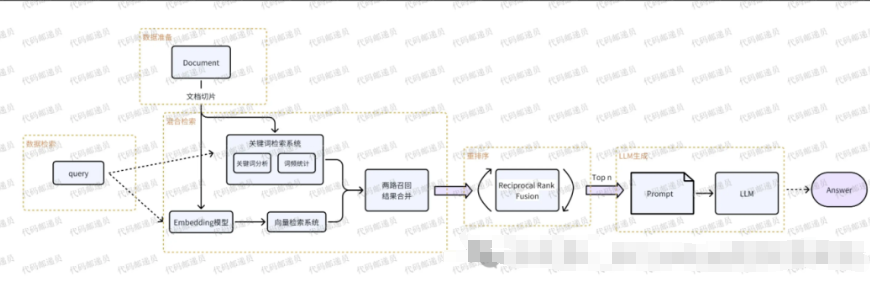
混合检索的原理
关于关键字检索和向量检索,还有另外一种表述:
关键字检索(稀疏表示)、向量检索(稠密表示)。
基于关键字的搜索和向量搜索都返回一组单独的结果,通常是按计算的相关性排序的搜索结果列表。必须将这些单独的搜索结果集组合在一起。
有许多不同的策略可以将两个列表的排名结果合并为一个单一的排名,一般来说,搜索结果通常是首先评分的。这些分数可以根据指定的指标(例如余弦距离)计算,也可以仅根据搜索结果列表中的排名进行计算。
然后,计算出的分数用一个参数进行加权,该参数决定了每个算法的权重并影响结果的重新排名。

通常,alpha 取一个介于 0 和 1 之间的值,其中
alpha = 1:纯向量搜索
alpha = 0:纯关键字搜索
下面,您可以看到关键字和向量搜索之间融合的最小示例,其中包含基于排名和 .alpha = 0.5
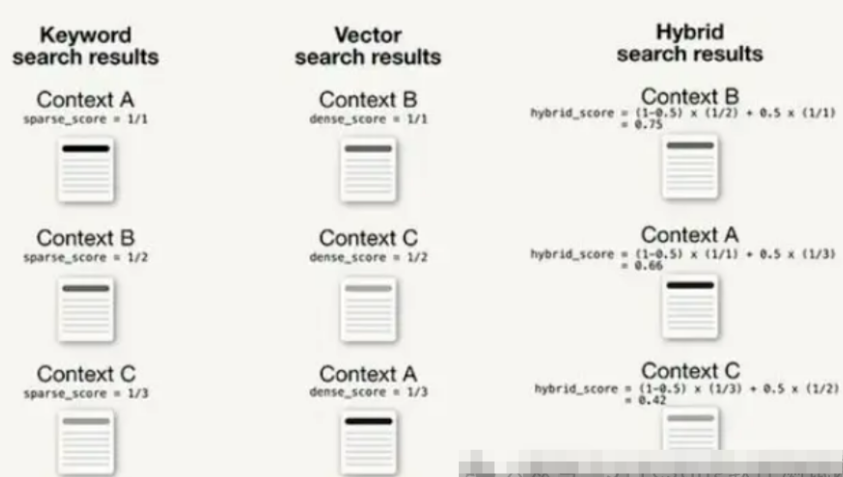
我们用一个小例子加深下体验
基于关键字检索的排序
import time
class MyEsConnector:
def __init__(self, es_client, index_name, keyword_fn):
self.es_client = es_client
self.index_name = index_name
self.keyword_fn = keyword_fn
def add_documents(self, documents):
'''文档灌库'''
if self.es_client.indices.exists(index=self.index_name):
self.es_client.indices.delete(index=self.index_name)
self.es_client.indices.create(index=self.index_name)
actions = [
{
"_index": self.index_name,
"_source": {
"keywords": self.keyword_fn(doc),
"text": doc,
"id": f"doc_{i}"
}
}
for i, doc in enumerate(documents)
]
helpers.bulk(self.es_client, actions)
time.sleep(1)
def search(self, query_string, top_n=3):
'''检索'''
search_query = {
"match": {
"keywords": self.keyword_fn(query_string)
}
}
res = self.es_client.search(
index=self.index_name, query=search_query, size=top_n)
return {
hit["_source"]["id"]: {
"text": hit["_source"]["text"],
"rank": i,
}
for i, hit in enumerate(res["hits"]["hits"])
}
from chinese_utils import to_keywords # 使用中文的关键字提取函数
# 引入配置文件
ELASTICSEARCH_BASE_URL = os.getenv('ELASTICSEARCH_BASE_URL')
ELASTICSEARCH_PASSWORD = os.getenv('ELASTICSEARCH_PASSWORD')
ELASTICSEARCH_NAME= os.getenv('ELASTICSEARCH_NAME')
es = Elasticsearch(
hosts=[ELASTICSEARCH_BASE_URL], # 服务地址与端口
http_auth=(ELASTICSEARCH_NAME, ELASTICSEARCH_PASSWORD), # 用户名,密码
)
# 创建 ES 连接器
es_connector = MyEsConnector(es, "demo_es_rrf", to_keywords)
# 文档灌库
es_connector.add_documents(documents)
# 关键字检索
keyword_search_results = es_connector.search(query, 3)
print(json.dumps(keyword_search_results, indent=4, ensure_ascii=False))
基于向量检索的排序
# 创建向量数据库连接器
vecdb_connector = MyVectorDBConnector("demo_vec_rrf", get_embeddings)
# 文档灌库
vecdb_connector.add_documents(documents)
# 向量检索
vector_search_results = {
"doc_"+str(documents.index(doc)): {
"text": doc,
"rank": i
}
for i, doc in enumerate(
vecdb_connector.search(query, 3)["documents"][0]
)
} # 把结果转成跟上面关键字检索结果一样的格式
print(json.dumps(vector_search_results, indent=4, ensure_ascii=False))
基于 RRF 的融合排序
def rrf(ranks, k=1):
ret = {}
# 遍历每次的排序结果
for rank in ranks:
# 遍历排序中每个元素
for id, val in rank.items():
if id not in ret:
ret[id] = {"score": 0, "text": val["text"]}
# 计算 RRF 得分
ret[id]["score"] += 1.0/(k+val["rank"])
# 按 RRF 得分排序,并返回
return dict(sorted(ret.items(), key=lambda item: item[1]["score"], reverse=True))
import json
# 融合两次检索的排序结果
reranked = rrf([keyword_search_results, vector_search_results])
print(json.dumps(reranked, indent=4, ensure_ascii=False))
我们看下各自的执行结果
# 背景说明:在医学中“小细胞肺癌”和“非小细胞肺癌”是两种不同的癌症
query = "非小细胞肺癌的患者"
documents = [
"玛丽患有肺癌,癌细胞已转移",
"刘某肺癌I期",
"张某经诊断为非小细胞肺癌III期",
"小细胞肺癌是肺癌的一种"
]
query_vec = get_embeddings([query])[0]
doc_vecs = get_embeddings(documents)
print("Cosine distance:")
for vec in doc_vecs:
print(cos_sim(query_vec, vec))
{
"doc_2": {
"text": "张某经诊断为非小细胞肺癌III期",
"rank": 0
},
"doc_0": {
"text": "玛丽患有肺癌,癌细胞已转移",
"rank": 1
},
"doc_3": {
"text": "小细胞肺癌是肺癌的一种",
"rank": 2
}
}
{
"doc_3": {
"text": "小细胞肺癌是肺癌的一种",
"rank": 0
},
"doc_2": {
"text": "张某经诊断为非小细胞肺癌III期",
"rank": 1
},
"doc_0": {
"text": "玛丽患有肺癌,癌细胞已转移",
"rank": 2
}
}
{
"doc_2": {
"score": 1.5,
"text": "张某经诊断为非小细胞肺癌III期"
},
"doc_3": {
"score": 1.3333333333333333,
"text": "小细胞肺癌是肺癌的一种"
},
"doc_0": {
"score": 0.8333333333333333,
"text": "玛丽患有肺癌,癌细胞已转移"
}
}
我们可以看到混合检索的效果是最好的。
混合检索 + 重排序
我们在上述的讲解过程中,提到了重排序,为什么会再引入重排序呢?
混合检索能够结合不同检索技术的优势,以获得更好的召回结果。然而,在不同检索模式下的查询结果需要进行合并和归一化(将数据转换为统一的标准范围或分布,以便更好地进行比较、分析和处理),然后再一并提供给大模型。在这个过程中,我们需要引入一个评分系统:重排序模型(Rerank Model)。
在大多数情况下,由于计算查询与数百万个文档之间的相关性得分将会非常低效,通常会在进行重排序之前进行一次前置检索。因此,重排序一般放在搜索流程的最后阶段,非常适合用于合并和排序来自不同检索系统的结果。
然而,重排序并不是只适用于不同检索系统的结果合并。即使在单一检索模式下,引入重排序步骤也能有效帮助改进文档的召回效果,例如在关键词检索之后加入语义重排序。
总结
**RAG部分,我们陆陆续续分享了好几篇文章,从了解RAG到RAG与Fine tune的对比,再到RAG的实操:**文档切片的方法、关键字检索、向量检索。
本文更是综合我们过往的知识,给大家分享了通过混合检索和排序能力超越向量搜索,让我们了解了为什么需要混合检索,为什么需要重排序,以及通过简单的例子也让大家体验了各自基本的效果。希望给大家接下来构建自己的RAG能够起到帮助的作用。
将混合检索与重排序技术应用于生产级RAG系统并不是一件简单的事情。它需要开发者克服数据处理的复杂性、模型训练的巨大挑战,以及算法优化的繁琐工作。在这一过程中,我们不仅要关注技术的实现,更要确保系统的稳定性和扩展性,以适应不断增加的用户需求和数据量。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









