






大语言模型也只是将用户提供的大规模数据集训练而来,也并非万能的什么都知道,特别是一些小众知识、内部数据或私密的个人数据等,此时ChatGLM3肯定会胡乱回答就是ChatGPT4也不一定能给出满意回答;不少公司、个人都有自己的知识库或日志等此时如有可将这些数据以某种方式挂在大模型上此时在知识库存在的知识可从中作答,不属于知识库中的内容还是按照大模型原来方式生成,精准度会高不少;知识库的内容包括文本、PDF、图片、视频、网页等等;
基于LLM的本地私有化知识库实现主要分为两种:
1、模型训练微调: 将知识库的内容整理成训练数据集,拿这些整理好的数据集来训练该模型,最终让模型“学会”该知识库的内容,至于效果如何很大程度取决于该数据集的质量和训练的调参,这种方式较复杂、门槛高;
2、外挂知识库: 在向模型提问时提供一些知识库中的内容让它在其中找到正确的答案,外挂的形式门槛相对低一点大部分的工作主要是文档的处理:加载、切分、向量化、持久化、相识度对比等以及Prompt编写,本文所使用的方式也是此种;
文档处理
这里只涉及到文本的处理,比较好的做法是从知识库中挑选出问题以及相关的内容,这样准确的相对比较高,本文只是简单粗暴的把所有数据都丢给它让它去学习处理;
知识库预处理相关概念
加载文件: 加载知识库中的文本
文本分割(TextSplitter): 按一定规则将文本分割,具体参数有:separator:分隔符、chunk_size: 文本块长度、chunk_overlap: 文本块之间重叠的长度、length_function:计算长度的方法;文本块长度选择可能会对文本分割效果右较大的影响;
文本向量化: 将文本转换为向量,文本向量化后用于后续存储、计算相识度、检索相关文本等;
文本内嵌(Embedding): 将离散的符号或对象表示为连续的向量空间中的点;文本嵌入可用于以下功能:搜索、聚类、推荐、异常检测、多样本测量、分类;此处主要是用于查询的嵌入向量(问题向量化后)与每个文档的嵌入向量之间的余弦相似度,并返回得分最高的文档。Embedding开源模型模型有:Text2vec、Ernie-3.0、M3E等
持久化: 将向量化的数值存储到向量数据库方便后续直接使用,向量数据库有Chroma、Qdrant等;
代码实现
下面通过使用LangChain与ChatGLM实现本地知识库外挂,主要分为如下几步:启动ChatGLM ApiServer服务、加载文档与文本分割、文本向量化与文本内嵌、通过LangChain将LLM与向量库Retriever(检索器)关联、绑定gradio;
由于网络原因在此过程中会下载nltk_data数据集 与Embedding模型 ,自动下载可能不会成功,可手动下载放到相关目录即可;
导入模块
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.chroma import Chroma
from langchain.embeddings.huggingface import HuggingFaceBgeEmbeddings
import os
from langchain.chains import RetrievalQA
from langchain.llms.chatglm import ChatGLM
from langchain.prompts import PromptTemplate
embedding_model_dict={
'ernie-tiny':"nghuyong/ernie-3.0-nano-zh",
'ernie-base':"nghuyong/ernie-3.0-base-zh",
'text2vec':"GanymedeNil/text2vec-large-chinese",
'text2vec2':"ver/sbert-base-chinese-nil",
'text2vec3':"shibing624/text2vec-base-chinese",
}
安装依赖
pip install unstructured
pip install sentence_transformers
pip install chromadb
pip install gradio
加载文档与文本分割: 通过LangChain目录加载器加载指定目录中的所有文档,使用字符文本分割器对所有文档进行分割,文本块大小为265、块重叠长度为0;其他分割器还有:MarkdownHeaderTextSplitter、HTMLHeaderTextSplitter、RecursiveCharacterTextSplitter等;
def load_documents(dir="books"):
loader = DirectoryLoader(dir)
documents= loader.load()
text_spliter = CharacterTextSplitter(chunk_size=265,chunk_overlap=0)
split_docs = text_spliter.split_documents(documents)
return split_docs
文本向量化与文本内嵌: 将文档存储向量库Chroma,并指定文档的Embedding模型;
def store_chroma(docs,embeddings,dir="VectorStore"):
db = Chroma.from_documents(docs,embeddings,persist_directory=dir)
db.persist()
return db
载入embedding模型: 加载HuggingFaceBge托管的Embedding模型;
def load_embedding_mode(model_name='tiny'):
encode_kwargs = {'normalize_embeddings': False}
# model_kwargs = {'device':'cuda:0'}
return HuggingFaceBgeEmbeddings(
# model_name=embedding_model_dict[model_name],
model_name="./ernie-3.0-nano-zh",
encode_kwargs=encode_kwargs
)
加载向量库: 如本地存在持久化的向量库则加载否则加载文档并存储向量库;
def load_db():
embeddings = load_embedding_mode('ernie-tiny')
if not os.path.exists('VectorStore'):
documents = load_documents()
db = store_chroma(documents,embeddings)
else:
db = Chroma(persist_directory='VectorStore',embedding_function=embeddings)
return db
定义LLM关联检索问答链:定义ChatGLM模型调用客户端、获取向量库检索器retriever 、定义LangChain问答链RetrievalQA对象,链类型为:stuff、LLM模型为ChatGLM;
token: 最大8000
top_p: 影响文本多样性,越大多样性越强取值范围:[0,1.0]
chain_type_kwargs: 使用prompt可让QA给出格式化的答案,如典型prompt为:
"""已知信息:{context} 根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。问题是:{question}"""
chain_type: 参数包括如下几种:
stuff: 适用小文本,速度较快将所有相关文档块拼接起来给LLM,可能会超过上下文大小
map_reduce:LLM对每个相关文档块做一次总结,LLM把后总结汇总再做最终总结
refine:LLM对每一个文档块进行总结,后逐步汇总成一个总结
map_rerank: 对文档块总结进行打分,答案取选取分数高
PROMPT_TEMPLATE = """已知信息:{context}
根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。问题是:{question}
"""
PROMPT = PromptTemplate(
template=PROMPT_TEMPLATE, input_variables=["context", "question"]
)
def retrieverQa():
db=load_db()
retriever = db.as_retriever()
llm = ChatGLM(
endpoint_url="http://127.0.0.1:8000",
max_token=8000,
top_p=0.9)
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type='stuff',
retriever=retriever,
chain_type_kwargs={"prompt": PROMPT}
)
return qa
关联gradio: 将RetrievalQA对象与gradio关联,把页面输入的内容传入问答器;
def chatQA(quetion,history):
qa = retrieverQa()
resp = qa.run(quetion)
return resp
demo = gr.ChatInterface(chatQA)
demo.launch(inbrowser=True)
最终效果
通过问答对比可以看到外挂知识库后效果比较明显,并不会无中生有,根据知识库选取了相关内容总结回答;
未接入本地知识库时,ChatGLM3模型输出的内容:
南海农场位于中国海南省三亚市,是一个重要的热带农业基地。这里种植着各种热带作物,如水稻、蔬菜、水果等,满足三亚市及附近地区的居民和游客的需求。南海农场还具备较高的生态价值,为当地的生态环境保护和可持续发展做出了贡献。
使用了本地知识库后:
南海农场是一个位于海南的农场,主要经济作物包括荔枝、胡椒、橡胶、水稻等。茶叶和水果也是该农场的重要经济来源之一。农场设有中学、小学、医院和茶胶加工厂等设施。此外,农场还拥有自己的橡胶和水稻种植区,以及一个味精厂。农场共有7个作业区和62个生产队,并管辖黄竹镇8个村民委员会。
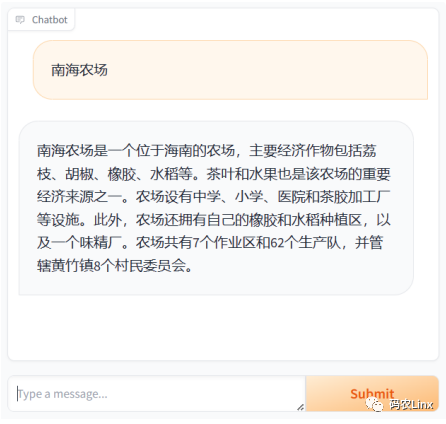
这仅仅是一个Demo外挂知识库的最终效果如何取决于:文本分割、Embedding模型、向量库、LLM模型、知识库的预处理、调参等等;
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









