






概述
微调 LLM 是一个能高效改善模型性能的方法,通过微调能使模型多一些人们期望的行为,少一些不期望的行为。然而微调 LLM 是非常昂贵的,例如微调一个常规 16-bit 65B 的LLaMA需要至少 780GB 的 GPU 显存。
QLoRA 是一个有效的对已量化 4-bit 模型进行微调而模型性能不降低的方法,例如通过 QLoRA 可以在一个 48GB 的 GPU 上对参数量为 65B 的 4-bit 量化模型进行微调,微调后模型的性能不比用16-bit进行微调的性能差。
QLoRA 引入了 3 个新颖的设计,能够在不牺牲性能的前提下降低内存。
- 4-bit NormalFloat: 对正态分布的数据来说,是信息理论上最优的量化数据类型,优于 4-bit 整型和 4-bit 浮点型
- Double Quantization:不仅量化权重,还是量化了量化常数,每个参数大概能节省平均 0.37bits
- Paged Optimizers:使用 NVIDIA 统一内存(unified memory)技术去避免处理长序列小批量数据时,梯度检查点的内存尖峰
下图对比了不同微调技术和各自内存的使用情况。QLoRA 对 LoRA 的改进在于 Transformer 类模型采用了 4-bit 精度加载,使用了 paged optimizer 去处理内存尖峰。
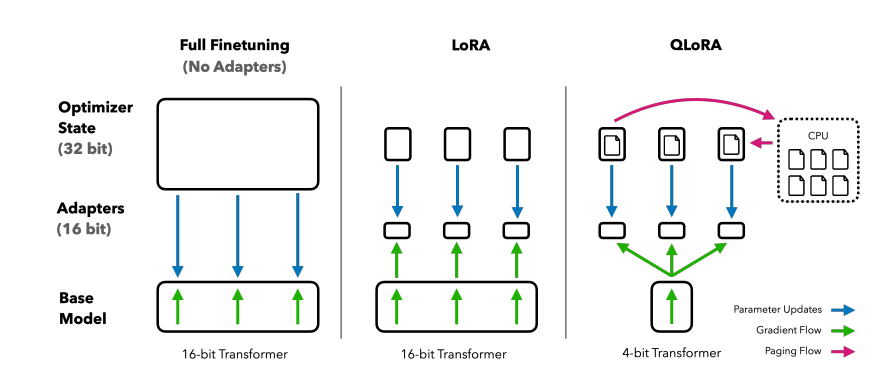
QLoRA基础知识
先介绍几个基础技术,他们是 QLoRA 构建的基石。
Block-wise k-bit 量化

Low-rank Adapters(LoRA)

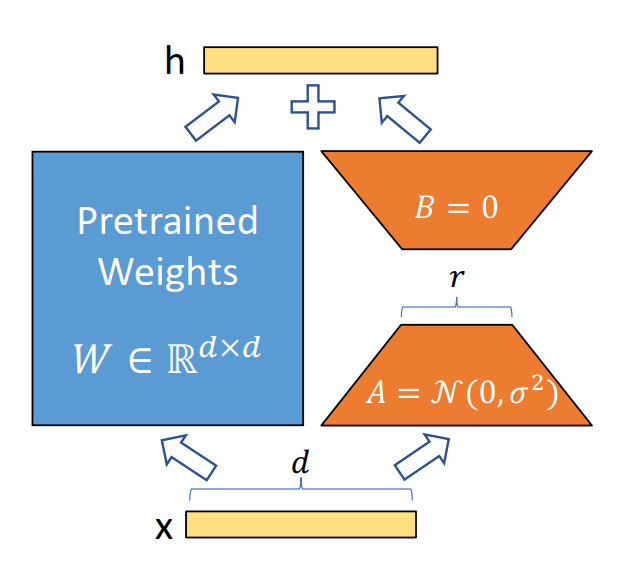
QLoRA微调
QLoRA 能进行高保真的 4-bit 微调,得益于 2 个技术:4-bit NormalFloat(NF4)量化和 Double Quantization。此外,通过 Paged Optimizers,可以防止梯度检查点带来内存尖峰(memory spikes)从而导致 out-of-memory 错误,这种错误常常在大模型单节点微调时出现。
QLoRA 微调时,用到 2 种数据类型:一种是存储数据类型,即 4-bit 已压缩权重;一种是计算数据类型,通常是 BFloat16。这意味着在进行 QLoRA 时,模型权重是 4-bit 存储,并且是冻结的,不进行权重更新,推理时需要把模型权重反量化为 BFloat16,然后进行 16-bit 矩阵乘法计算。adapter 中的权重是真正需要微调的权重,本来就是 16-bit 表示。
4-bit NormalFloat Quantization


NF量化在实现的时候,结合公式(1)进行 block-wise 量化,需要使用到 lookup table,硬件效率比较低,是一种非均匀量化。
Double Quantization

Paged Optimizers
NVIDIA的统一内存(unified memory)特性能在 GPU 偶尔 out-of-memory 的时候避免错误的发生,在 CPU 和 GPU 之间自动进行数据的分页传送。这个技术工作起来像 CPU RAM 和硬盘之间进行的常规的内存分页。QLoRA 利用这个技术为优化器的状态分配分页内存,这样当 GPU在运行时 out-of-memory 时,会自动激发 CPU RAM, 当优化器的状态需要更新时,又会自动分页切回 GPU 内存。
QloRA

QLoRA 与标准微调对比
在所有的 transformer 层上使用 LoRA 技术对于 LoRA 微调的精度是否能和标准的 16-bit 微调的精度相匹配非常重要,具体见下图。
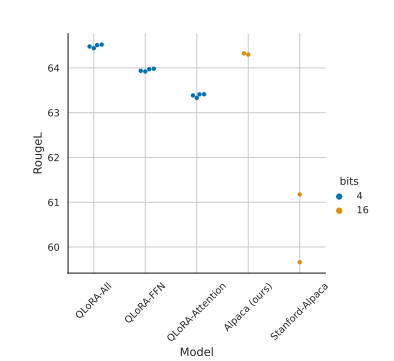
上图中是 LLaMA 7B 模型在 Alpaca 数据集上的测试结果。Stanford-Alpaca 采用 Stranford Alpaca 官方默认的 16-bit 标准微调参数,Alpaca(ours) 是作者对官方微调参数的改进,QLoRA-Attention 是只对 Attention 部分进行 QLoRA 微调,QLoRA-FFN 是只对 FFN 进行 QLoRA,QLoRA 是对所有的线性 transformer 块进行微调。从上图可见,对所有的线性 transformer 块进行微调, 对 LoRA 微调性能是否能匹配 16-bit 标准微调非常重要。在测试中,均使用了 16 个 LoRA adapter,这个超参也很重要。
下图表明, 4-bit NormalFloat 能比 4-bit Float 带来更好的精度。DQ 表示双重量化。
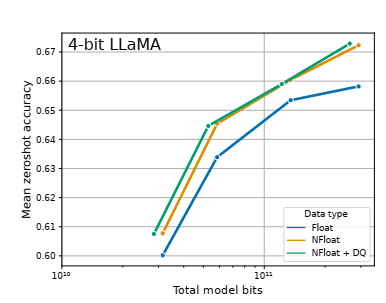
近期研究发现,4-bit 的量化推理是可能的,但是相比 16-bit,会有一定的性能降低,这主要是由于精度降低后,量化误差增大带来的。这样的精度损失可以由量化后对 adapter 的微调来弥补。见下表。表中对比了 RoBERTA 和 T5 模型在 GLUE 和 the Super-NaturalInstructions 数据集下,BF16 的标准微调、LoRA 微调和各种精度下的 QLoRA 微调。从表中可见, 各种精度下对 adapter 的微调,都能够复现标准微调下的精度。
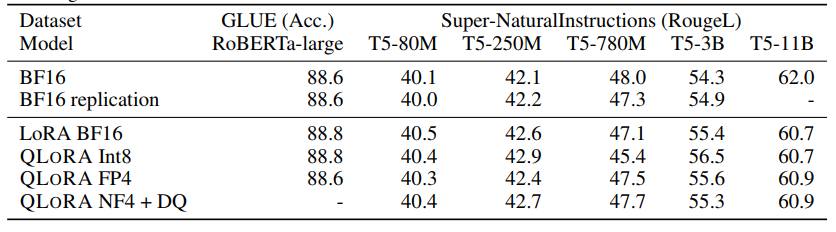
QLoRA 技术不仅适用于上图所示的 11B 规模的模型, 也能扩展到 7B - 65B的规模,见下表。下表使用了2种数据集, Alpaca 和 FLAN v2。精度是 5 次 平均的 MMLU 精度。由表可见 NF4 配合上双重量化(DQ)能够完全媲美 16-bit LoRA 的精度。同时 FP4 的 QLoRA 比 16-bit 的 LoRA 精度平均低 1 个 百分点,这说明了 (1)NF4 + DQ 的 QLoRA 能复制 16-bit 标准微调和 16-bit LoRA 微调的性能 (2)NF4的数据类型就量化精度而言是优于 FP4 的。

总结
QLoRA 是一种有效的微调方式,它主要由 3 种创新的技术组成。采用 QLoRA 能显著的减小微调时对内存的需求,使得一个 65B 参数量的模型能够在一个 48G 的单卡 GPU 上进行微调,同时提供和 16-bit 微调相当的模型性能。QLoRA 降低了微调时对资源的需求,使得对 LLM 的微调更加普遍通用和平民化。
参考资料 参考文献
[1]8-BIT OPTIMIZERS VIA BLOCK-WISE QUANTIZATION8-BIT OPTIMIZERS VIA BLOCK-WISE QUANTIZATION
[2]The case for 4-bit precision: k-bit inference scaling laws
[3]8-bit approximations for parallelism in deep learning
[4]Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 578
578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









