






阿里巴巴近期发布了其开源的混合推理大语言模型 (LLM) 通义千问 Qwen3,此次 Qwen3 开源模型系列包含两款混合专家模型 (MoE),235B-A22B(总参数 2,350 亿,激活参数 220 亿)和 30B-A3B,以及六款稠密 (Dense) 模型 0.6B、1.7B、4B、8B、14B、32B。
现在,开发者能够基于 NVIDIA GPU,使用 NVIDIA TensorRT-LLM、Ollama、SGLang、vLLM 等推理框架高效集成和部署 Qwen3 模型,从而实现极快的词元 (token) 生成,以及生产级别的应用研发。
本文提供使用 Qwen3 系列模型的最佳实践,我们会展示如何使用上述框架来部署模型实现高效推理。开发者可以根据他们的应用场景需求来选择合适的框架,例如高吞吐量、低延迟、或是 GPU 内存占用 (GPU footprint)。
Qwen3 模型
Qwen3 是中国首个混合推理模型,在 AIME、LiveCodeBench、ArenaHard、BFCL 等权威评测集上均获得出色的表现(信息来源于阿里巴巴官方微信公众号)。Qwen3 提供的系列开源稠密和 MoE 模型在推理、指令遵循、Agent 能力、多语言支持等方面均大幅增强,是全球领先的开源模型。
大语言模型的推理性能对于
实时、经济高效的生产级部署至关重要
LLM 生态系统快速演进,新模型和新技术不断更新迭代,需要一种高性能且灵活的解决方案来优化模型。
推理系统设计颇具挑战,要求也不断提升,这些挑战包括 LLM 推理计算预填充 (prefill) 和解码 (decode) 两个阶段对于计算能力和显存大小 / 带宽的需求差异,超大尺寸模型并行分布式推理,海量并发请求,输入输出长度高度动态请求等。
目前在推理引擎上有许多优化技术可用,包括高性能 kernel、低精度量化、Batch 调度、采样优化、KV 缓存 (KV cache) 优化等等,选择最适合自己应用场景的技术组合需要耗费开发者大量精力。
NVIDIA TensorRT-LLM 提供了最新的极致优化的计算 kernel、高性能 Attention 实现、多机多卡通信分布式支持、丰富的并行和量化策略等,从而在 NVIDIA GPU 上实现高效的 LLM 推理。此外,TensorRT-LLM 采用 PyTorch 的新架构还提供了直观、简洁且高效的模型推理配置 LLM API,从而能够兼顾极佳性能和灵活友好的工作流。
通过使用 TensorRT-LLM,开发者可以迅速上手先进的优化技术,其中包括定制的 Attention kernel、连续批处理 (in-flight batching)、分页 KV 缓存 (Paged KV cache)、量化 (FP8、FP4、INT4 AWQ、INT8 SmoothQuant)、投机采样等诸多技术。
使用 TensorRT-LLM
运行 Qwen3 的推理部署优化
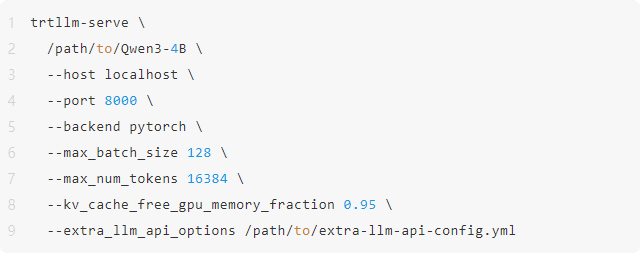
下面以使用 Qwen3-4B 模型配置 PyTorch backend 为例,描述如何快捷进行基准测试以及服务化的工作。采用类似的步骤,也可以实现 Qwen3 其他 Dense 和 MoE 模型的推理部署优化。
\1. 首先准备 benchmark 测试数据集合和 extra-llm-api-config.yml
配置文件:

\2. 通过 trtllm-bench 运行 benchmark 指令:

相同 GPU 环境配置下,基于 ISL = 1K,OSL = 1K,相较 BF16 基准,Qwen3-4B 稠密模型使用 TensorRT-LLM 在 BF16 的推理吞吐(每秒生成的 token 数)加速比最高可达 16.04 倍。
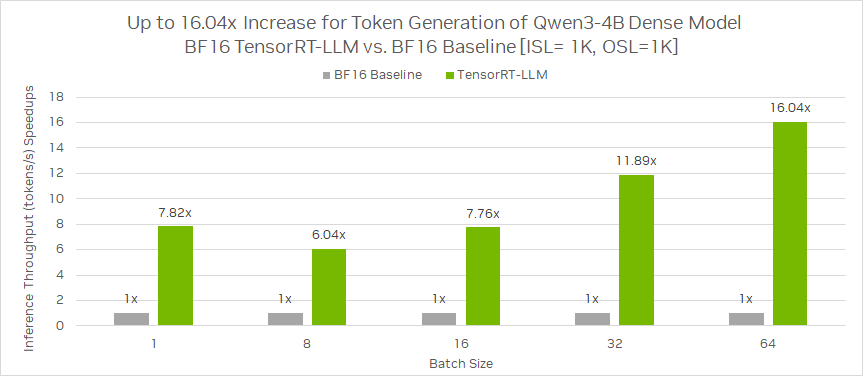
图 1:Qwen3-4B 稠密模型在 TensorRT-LLM BF16 与 BF16 基准的推理吞吐性能比较
该图片来源于 NVIDIA Blog: Integrate and Deploy Tongyi Qwen3 Models into Production Applications with NVIDIA,若您有任何疑问或需要使用该图片,请联系 NVIDIA
\3. 通过 trtllm-serve 运行 serve 指令:
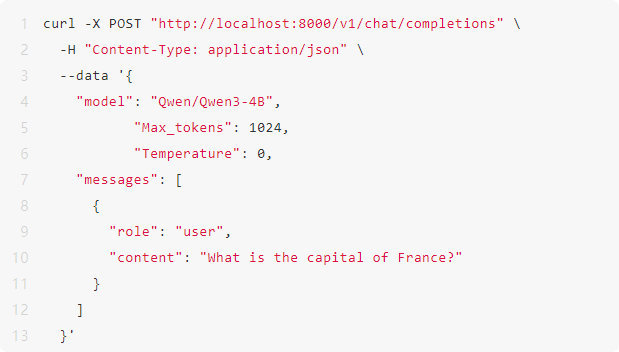
\4. 模型启动成功后,便可通过标准 OpenAI API 进行模型推理调用。
使用 Ollama,SGLang,
vLLM 框架运行 Qwen3-4B
除了 TensorRT-LLM,Qwen 模型也可以使用诸如 Ollama,SGLang,vLLM 等框架,通过简单几步部署到 NVIDIA GPU。Qwen3 提供了多种模型可以运行在终端和设备上,例如 NVIDIA Jeston 以及适用于 Windows 开发者的 NVIDIA RTX。
使用 Ollama 在本地运行 Qwen3-4B:
\1. 从以下网址下载和安装最新版本的 Ollama: ollama.com/download。
\2. 使用 ollama run 命令运行模型,此操作将加载并初始化模型用于后续与用户交互。
ollama run qwen3:4b
\3. 在用户提示词或系统消息中添加 /think(默认值)和 /no_think 可在模型的思考模式之间切换。运行 ollama run 命令后,可以直接在终端中使用以下的示例提示词,来测试思考模式:
"Write a python lambda function to add two numbers" - Thinking mode enabled
"Write a python lambda function to add two numbers /no_think" - Non-thinking mode
\4. 参考 ollama.com/library/qwen3 查看更多模型变量,这些变量基于 NVIDIA GPU 完成了优化。
使用 SGLang 运行 Qwen3-4B:
\1. 安装 SGLang 库
pip install "sglang[all]"
\2. 下载模型,在这个演示中,我们使用的是 Hugging Face 上的 huggingfaceCLI 命令提示符执行,请注意需要提供一个 API key 来下载模型。
huggingface-cli download --resume-download Qwen/Qwen3-4B --local-dir ./
\3. 加载和运行模型,请注意,根据不同的需求,可以传递额外的参数。更多详细信息可以参考相关文档。
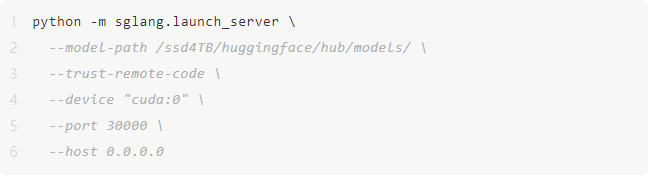
\4. 调用模型推理
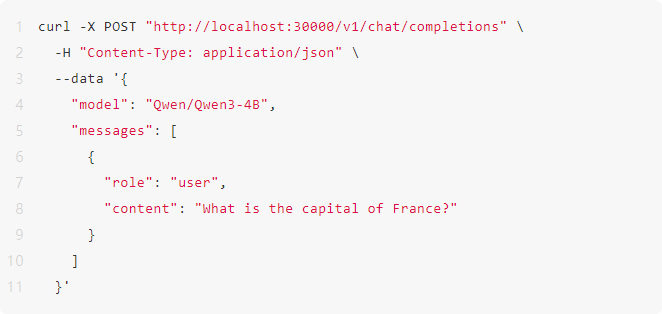
使用 vLLM 运行 Qwen3-4B:
\1. 安装 vLLM 库
pip install vllm
\2. 通过 vllm serve 加载和运行模型,请注意,根据不同的需求,可以传递额外的参数。更多详细信息可以参考相关文档。
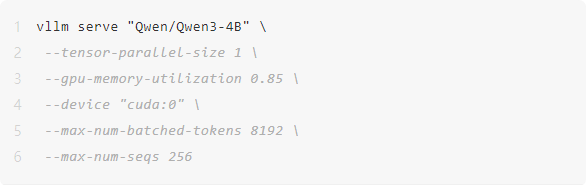
\3. 调用模型推理
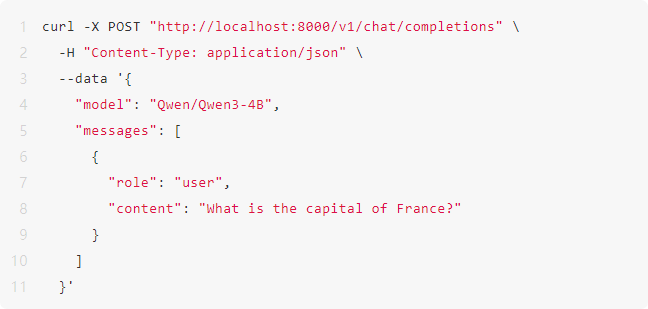
总结
仅通过几行代码,开发者即可通过包括 TensorRT-LLM 在内的流行推理框架来使用最新的 Qwen 系列模型。
此外,对模型推理和部署框架的技术选型需要考虑到诸多关键因素,尤其是在把 AI 模型部署到生产环境中时,对性能、资源和成本的平衡。
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 134
134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









