






巴黎奥运会乒乓球团体赛如火如荼,谷歌机器人申请出战——
首个达到人类竞技水平的机器人Agent发布!
你看一个没留神,就赢了专业教练一个球!

正反手快速转换,连续进攻也是不在话下~

面对一些突发战术,比如长球高球擦网球,也能沉稳应对。

实际测试中,机器人实时适应不同选手风格,最终赢下了与初学者的所有比赛,同中级玩家对打也有55%的胜率。
小小乒乓球,拿下!
与它对阵的美国乒乓球明星Barney J. Reed给予了高度评价:超出预期,这个机器人已经达到中级水平。
看完它的表现,网友们纷纷表示:可以买吗?想要。


遭遇战也能从容应对
乒乓球是一项对体力和战略、技巧等各方面综合要求很高的运动,人类也往往要经过多年训练才能掌握。
因此,不同于像象棋、围棋这种纯战略游戏,对于机器人而言,乒乓球成为考验其综合能力的重要基准,比如高速运动、实时的精准控制、战略决策、系统设计等等。
举个例子,面对球的不同落点,机器人需要快速移动位置;面对明显的出界球,机器人应该选择不接。

团队找到了29个不同技能水平的乒乓球运动员进行了比赛,包括初学者、中级、高级和高级以上。
人类与机器人进行了3场比赛,比赛遵循标准乒乓球规则。(不过由于机器人无法发球,整场由人类来发球)
在此之前,其实也有相应的乒乓球机器人研究,此次谷歌机器人的特别之处在于,它能够同从未见过的人类进行全面的竞技对决。

人类的各种打球风格,它都能快速适应。
比如看这位选手,比赛刚开局机器人明显还在适应过程中,人类以9比2的大比分击败机器人。

但就在下一局之后,机器人明显熟悉了对手风格,始终在紧紧追着比分。双方打得也是有来有往。

最终在所有对手中,机器人赢得了所有初学者比赛,在与中级选手的比赛中胜率为55%。
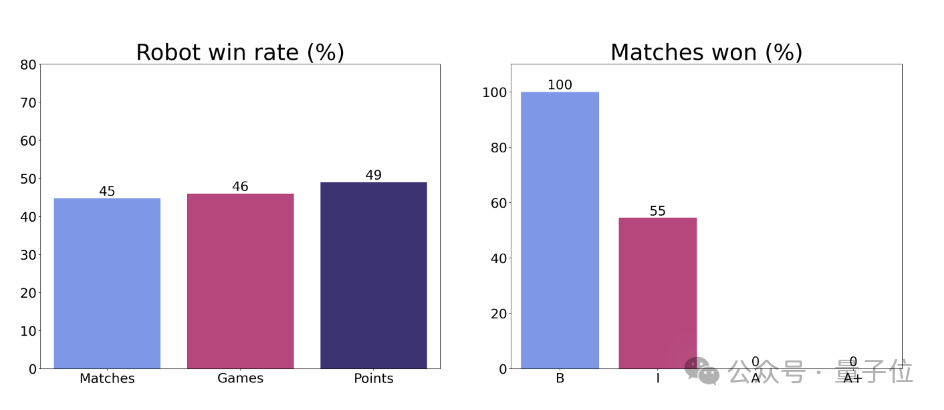
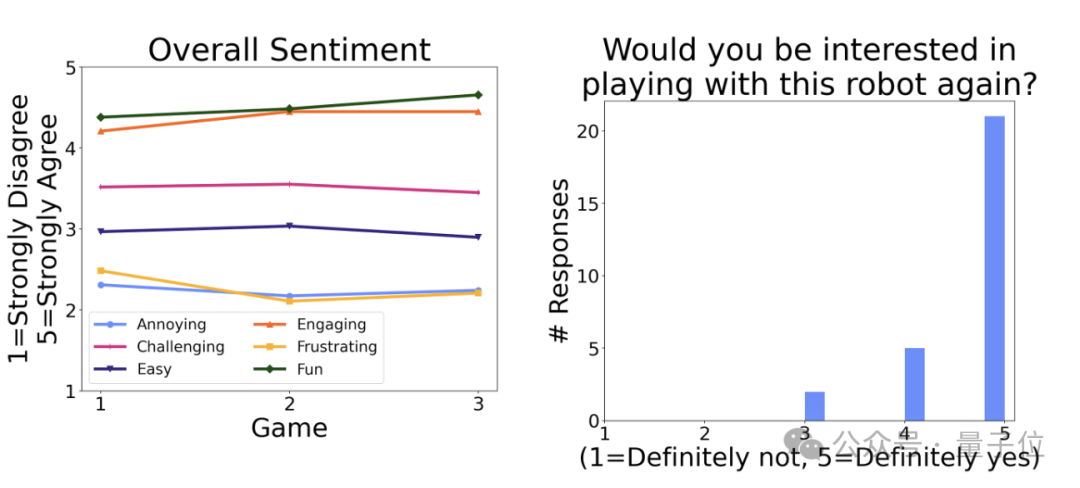
虽然目前机器人还没有办法战胜高级选手,但在人类的各种反馈中,可以看到,大家都很乐意同这个机器人玩耍。
小小乒乓球,如何拿下?
在介绍方法前,先来看一眼乒乓球机器人的硬件配置。
主体采用的是6自由度的瑞士公司ABB 1100机械臂,装置在两个Festo直线导轨上,使其能够在平面内移动。横向移动导轨长4米,纵向移动导轨长2米。
机械臂上装配了一个3D打印的球拍手柄和一个覆盖短颗粒胶皮的球拍。

就是这么个小登西,是如何学会打乒乓球的?
总结来说,使用了结合强化学习和模仿学习的混合训练方法。
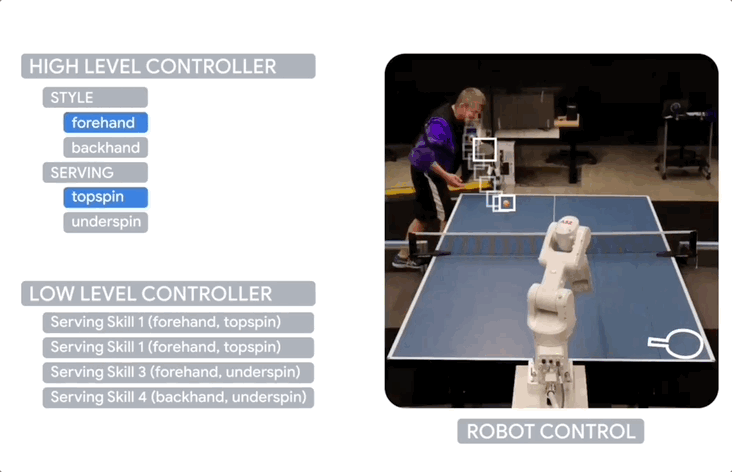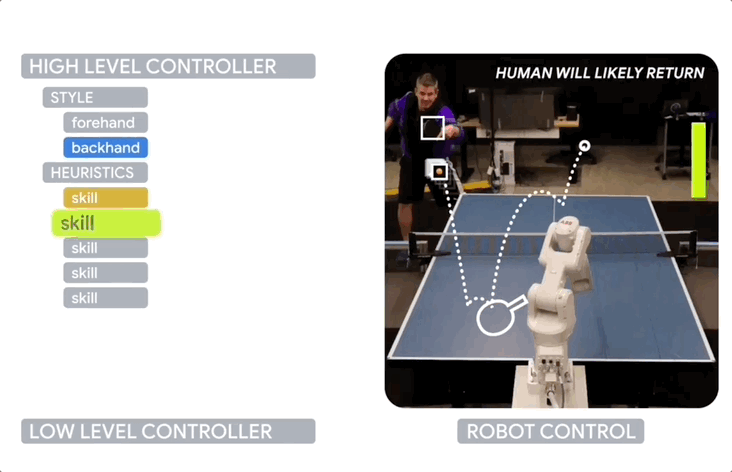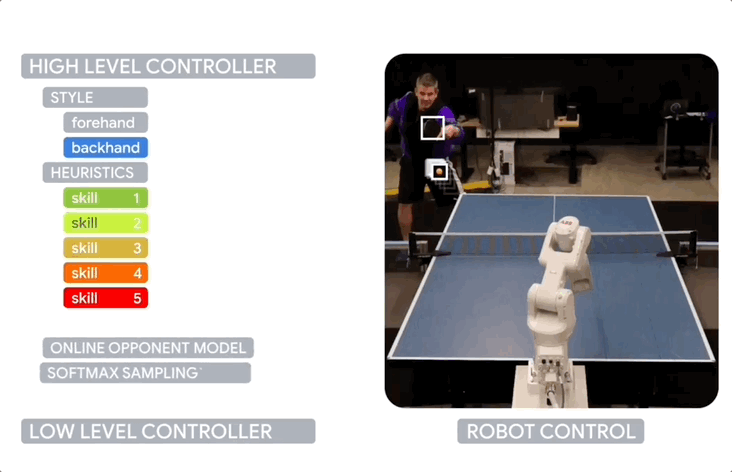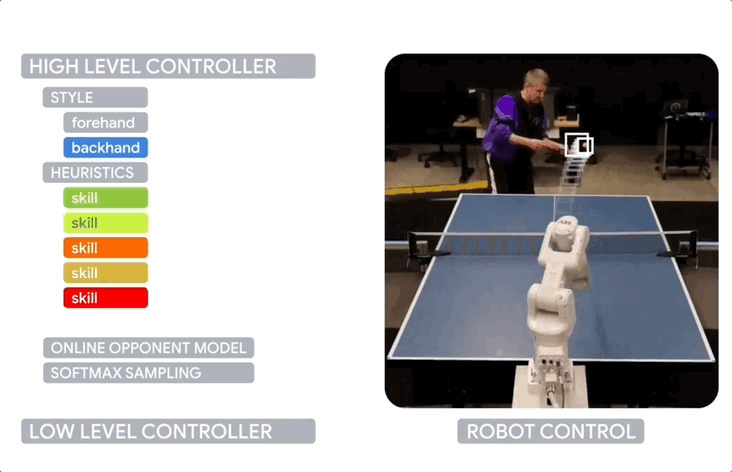
团队设计了分层和模块化的策略架构,Agent包括一个低级技能库(LLC)和一个高级控制器(HLC)。
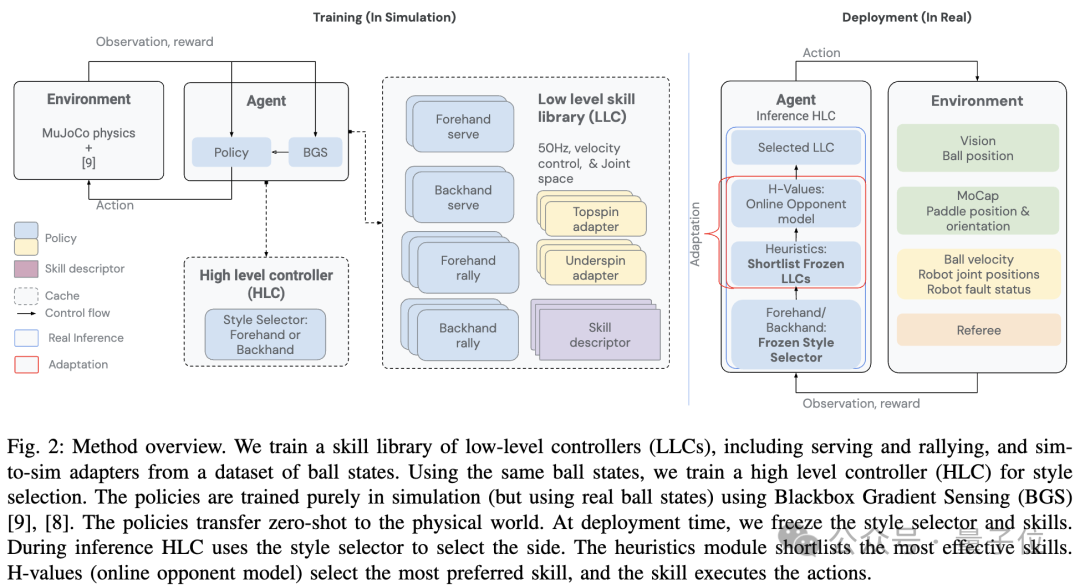
LLC是一组专门的策略,每个策略都经过训练来执行特定的乒乓球技能,如正手击球、反手击球、发球等。这些LLC使用CNN架构,通过仿真环境中的进化策略算法进行训练。
训练过程采用了从真实世界收集的球状态数据集,以确保模拟环境与真实环境的一致性。
而HLC负责在每次来球时选择最合适的LLC。
包含多个组件:风格策略,用于选择正手或反手;旋转分类器,用于识别来球的旋转类型;LLC技能描述符,描述每个LLC的能力;一组启发式策略,用于根据当前情况shortlist候选LLC。
HLC还使用在线学习的LLC偏好来适应对手的特点和弥补仿真到现实的差距。
具体来说,团队先是收集了少量人类比赛数据,设置初始化任务条件,然后用强化学习在模拟环境中训练一个Agent,再将策略零样本部署到真实世界中。
其中使用MuJoCo物理引擎精确模拟球和机器人动力学,包括空气阻力、Magnus效应等,还设计处理了上旋球“校正”,通过在仿真中切换不同的球拍参数来模拟真实世界中的上旋和下旋效果。
在Agent和人类不断对打的过程中,可以生成更多的训练任务条件,并重复训练-部署。
机器人技能逐渐提升,比赛也逐渐变得复杂,但仍基于现实世界的任务条件。机器人收集完数据,还能发现其能力的不足,随后通过在模拟环境中持续训练来弥补这些缺陷。
通过这种方法,机器人的技能可以在模拟与现实相结合的循环过程,自动迭代改进。

此外,这个机器人还能追踪对手的行为和打法来适应不同的对手,比如对手倾向于将球打回桌子的哪一。
由此能够尝试不同的技巧,监控自己的成功率,并实时调整策略。

在和人类对打实验中,团队也发现这个机器人有个弱点:不擅长处理下旋球。
按照对球旋转的估计,绘制机器人的上台率图,结果当面对更多下旋球时,其上台率显著下降。
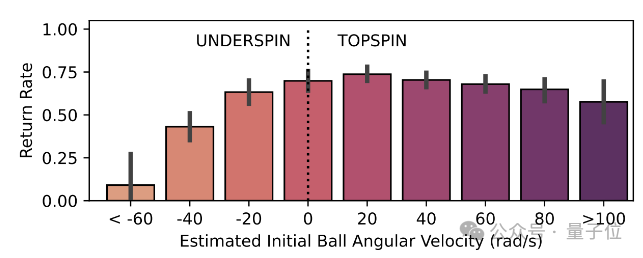
研究人员表示,机器人在处理弧线低且接近球桌的球时,为避免撞击到球桌,很难处理好,而且在实时确定球的旋转类型上也存在局限。
搞乒乓球机器人,谷歌不是第一次
研究机器人打乒乓球,谷歌很久前就开始了。团队相关研究还有一箩筐:

比如谷歌之前的i-Sim2Real研究中,训练的机器人与人类打球,最多可连续打340次不落地,相当于连续打了4分钟+。

其他团队也有过乒乓球机器人,比如这样婶儿的,还能发球:

以及像日本国家队和中国台湾的队伍,也都有拿机器人来陪练自家奥运选手。
那么有小伙伴就疑惑了,跟谷歌此次发布的机器人有什么区别?
有网友给出了解释:
谷歌这次是关于AI Agent,通过视频输入来工作,而非预编程算法。
所以,什么时候能看到跟咱们国家队对打?(Doge)
项目主页:
https://sites.google.com/view/competitive-robot-table-tennis/home?utm_source&utm_medium&utm_campaign&utm_content&pli=1
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 2609
2609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









