







步骤 6:前馈网络、层归一化和加法归一化
6.1 前馈网络
前馈网络利用深度神经网络结构,通过两层线性变换(第一层含 d_model 节点,第二层含 d_ff 节点,节点数根据论文设定)来捕捉嵌入向量的特征。
在第一层之后,引入 ReLU 激活函数赋予模型非线性特性,并通过 dropout 技术减少过拟合的风险。
6.2 层归一化
通过层归一化处理,可以确保网络中嵌入向量的值分布均衡,从而促进模型的稳定学习。此外,引入 gamma 和 beta 两个可学习的参数,以便对嵌入值进行动态的缩放和平移调整。
6.3 加法归一化
此模块结合了跳跃连接和层归一化技术。在模型的前向传播中,跳跃连接帮助保留早期层学到的特征,使这些特征能在网络的深层中发挥作用。
在反向传播过程中,跳跃连接减少了梯度消失的问题,因为它允许梯度在反向传递时跳过某些层。
无论是编码器中的两次应用,还是解码器中的三次应用,加法归一化都先对输入进行归一化处理,再将其与前一层的输出相加,以此来丰富模型的表达能力。


步骤 7:编码器块和编码器
7.1 编码器块
编码器的核心是两个主要组件:多头注意力机制和前馈网络。
除此之外,每个编码器块还包含两个加法归一化单元,负责调整和规范化信息流。我们依照注意力机制论文中的指导,将这些组件整合到 EncoderBlock 类中,并重复此结构6次以深化学习效果。
7.2 编码器
在编码器块的基础上,进一步创建 Encoder 类,接收一系列编码器块并有序堆叠起来。这一整合过程不仅增强了信息的流通性,还确保了网络能够输出高质量的编码结果,为后续的解码过程打下坚实基础。

步骤 8:解码器块、解码器和投影层
8.1 解码器块
解码器块由三大核心组件构成:掩码多头注意力、标准多头注意力以及前馈网络。
每个解码器块还包含三个加法归一化单元,用以优化信息处理流程。根据论文,将这些组件精心组合在 DecoderBlock 类中,并重复此结构6次,以丰富模型的解码能力。
8.2 解码器
在解码器块的基础上,构建 Decoder 类,接收一系列解码器块并进行有效堆叠,以实现连续的信息处理和特征提取,最终生成解码器的输出。
8.3 投影层
解码器的最终输出将进入投影层进行进一步处理。在这一层,输出首先通过一个线性层进行变换,以适应模型的输出需求。紧接着,应用 softmax 函数将输出转化为词汇表上的概率分布,从而选出概率最高的标记作为模型的预测结果。


步骤 9:构建 Transformer 模型
至此,已经完成了 Transformer 架构中的所有组件块的构建工作。剩余的任务是将它们全部组装起来。
首先,创建一个 Transformer 类,以初始化所有组件类的实例。在 Transformer 类中,先定义一个编码函数,该函数执行 Transformer 编码部分的所有任务,并生成编码器输出。
其次,定义一个解码函数,该函数执行 Transformer 解码部分的所有任务,并生成解码器输出。
第三,定义一个投影函数,接收解码器输出,并将输出映射到词汇表以进行预测。
现在,Transformer 架构准备就绪,可以通过定义函数来构建翻译语言模型(LLM),该函数接收如下代码中给出的所有必要参数。


步骤 10:训练与验证 LLM 模型
我们已经抵达了模型训练的关键阶段。这一过程其实颇为直接明了,使用之前在第三步中构建的训练 DataLoader 来执行训练任务。
鉴于训练数据集规模达到了百万,推荐在 GPU 上进行模型训练以提升效率。依据经验,完成 20 个 epoch 的训练大约耗时 5 小时。为了便于训练过程中的断点续传,我们在每个 epoch 结束时都会保存模型的权重和优化器的状态。
训练之后,紧接着的是验证环节。将动用规模为 2000 的验证 DataLoader 来执行这一任务,这一数据量设置是合理的。
在验证过程中,只在最初计算一次编码器的输出,随后便等待解码器输出句子结束的标记 [SEP]。这样的设计是因为在解码器接收到 [SEP] 标记之前,重复发送相同的编码器输出是无益的。
至于解码器的输入,则从句子的起始标记 [CLS] 开始。在每次预测之后,解码器的输入会追加上新生成的标记,直至遇到句子结束的 [SEP] 标记。最终,由投影层将这些输出映射转换为相应的文本表示,完成整个翻译过程。



步骤 11:构建并测试新翻译任务的模型
为这个翻译功能命名为 “malaygpt”,专门用来处理英文到马来文的翻译任务。这个函数设计得非常直观:用户只需输入英文文本,它便能智能地输出相应的马来文翻译。接下来,启动这个函数,亲自体验翻译效果。


进行一些翻译测试:
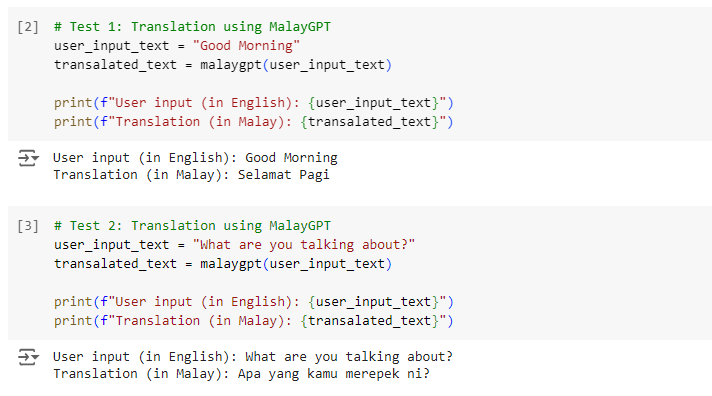
翻译得似乎还不错。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









