### 使用LSTM和Transformer进行强度预测的Python实现
#### 1. 导入必要的库
为了构建LSTM和Transformer模型,需要导入一些常用的深度学习库。这包括`tensorflow`及其子模块`keras`,以及数据处理工具如`numpy`和`pandas`。
```python
import numpy as np
import pandas as pd
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import LSTM, Dense, Input, TimeDistributed, MultiHeadAttention, LayerNormalization, Dropout
```
#### 2. 数据准备与预处理
在开始建模之前,必须准备好训练集并对其进行适当转换以便输入到神经网络中。对于时间序列问题来说,通常会涉及到滑动窗口方法来创建样本对[(X_t), (y_{t+1})]。
```python
def create_dataset(dataset, look_back=1):
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i:(i+look_back)]
dataX.append(a)
dataY.append(dataset[i + look_back])
return np.array(dataX), np.array(dataY)
# 加载数据...
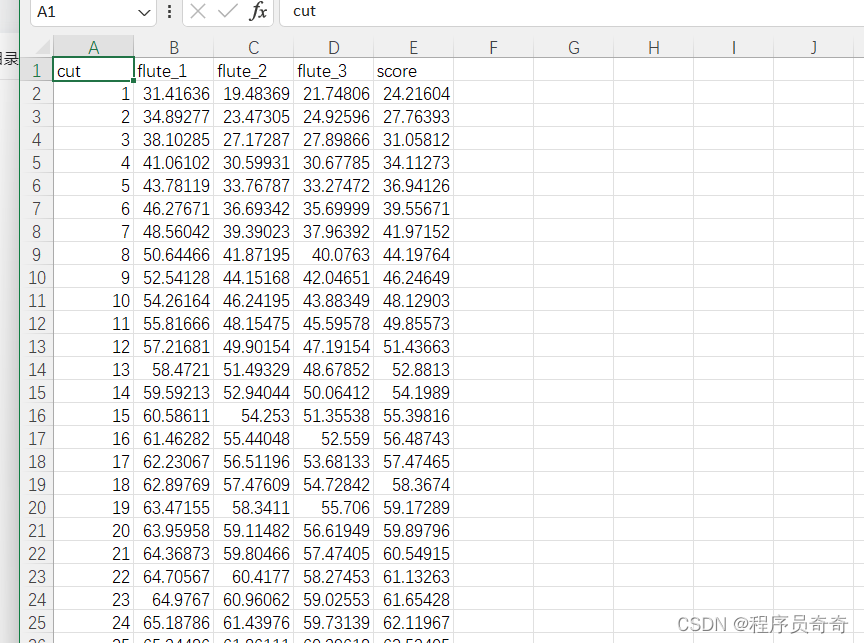
dataframe = pd.read_csv('intensity_data.csv', usecols=[1], engine='python')
dataset = dataframe.values.astype('float32')
train_size = int(len(dataset) * 0.8)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:]
look_back = 10
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
```
#### 3. 构建LSTM模型
定义一个简单的LSTM架构来进行强度预测。这里采用了一个具有单层LSTM单元的顺序模型结构,并设置了合理的超参数以适应具体应用场景的需求[^1]。
```python
lstm_model = Sequential()
lstm_model.add(LSTM(50, input_shape=(look_back, 1)))
lstm_model.add(Dense(1))
lstm_model.compile(loss='mean_squared_error', optimizer='adam')
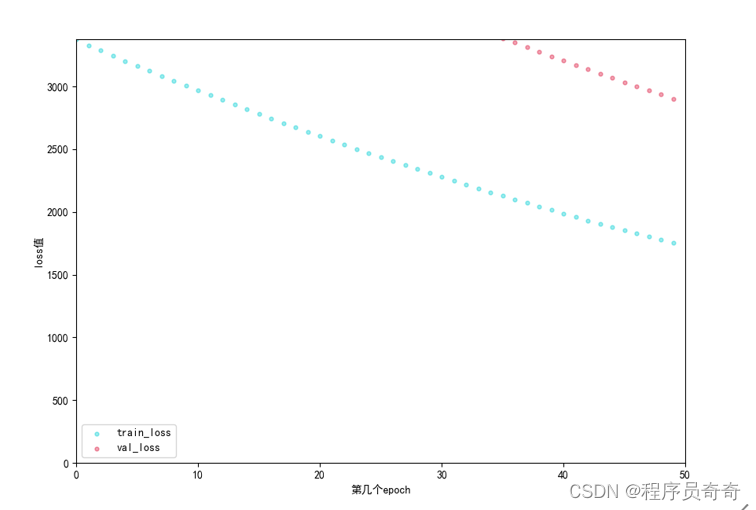
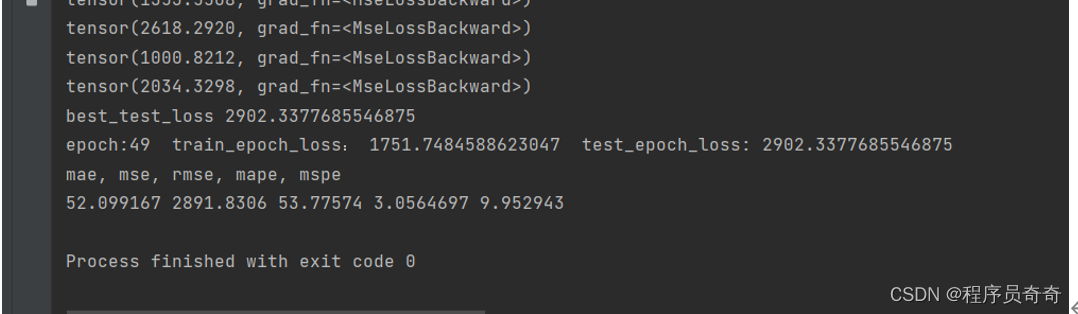
history_lstm = lstm_model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
```
#### 4. Transformer编码器部分的设计
不同于传统的RNN变体,Transformers依赖自注意力机制来自适应地捕捉不同位置间的关系。以下是简化版transformer encoder block 的实现方式:
```python
class TransformerBlock(Model):
def __init__(self, embed_dim, num_heads, ff_dim, rate=0.1):
super().__init__()
self.att = MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
self.ffn = Sequential(
[Dense(ff_dim, activation="relu"), Dense(embed_dim), ]
)
self.layernorm1 = LayerNormalization(epsilon=1e-6)
self.layernorm2 = LayerNormalization(epsilon=1e-6)
self.dropout1 = Dropout(rate)
self.dropout2 = Dropout(rate)
def call(self, inputs, training=False):
attn_output = self.att(inputs, inputs)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(inputs + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
return self.layernorm2(out1 + ffn_output)
input_layer = Input(shape=(None,))
embedding_layer = Embedding(input_dim=vocab_size, output_dim=emb_dim)(input_layer)
pos_encoding = PositionalEncoding(max_len=max_length, d_model=emb_dim)(embedding_layer)
transformer_block = TransformerBlock(embed_dim=emb_dim, num_heads=n_head, ff_dim=ff_units)
output = transformer_block(pos_encoding)
model_transformer = Model(inputs=input_layer, outputs=output)
model_transformer.compile(optimizer='adam', loss='mse')
history_transfomer = model_transformer.fit(trainX, trainY, epochs=epochs, validation_split=val_split)
```
请注意,在实际应用中可能还需要调整更多细节配置项,比如正则化策略、优化算法的选择等;此外,上述代码片段仅展示了核心逻辑框架的一部分,完整的项目往往涉及更复杂的流程控制及性能调优工作[^2]。








 超级会员免费看
超级会员免费看
 本文通过视频教程,展示了如何利用Lstm和Transformer深度学习模型进行刀具磨损的预测实战。详细介绍了从数据展示到主要代码的实现过程,并提供了完整的代码数据下载链接。
本文通过视频教程,展示了如何利用Lstm和Transformer深度学习模型进行刀具磨损的预测实战。详细介绍了从数据展示到主要代码的实现过程,并提供了完整的代码数据下载链接。
 3003
3003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























