%% 数据集降维提取 相关性较高的特征值。
% 加载数据
clear
clc
load('D1.mat');
life = (314:-1:0)';
life1 = (314:-1:0)';
life = [life;life1];
life = [life;life1];
life = [life;life1];
life = [life;life1];
for f= 1:size(C1,2)
Ti(:,f) = normalize(C1(:,f));
d(1,f) = corr(life,Ti(:,f),'type','Spearman');
end
% 相关性系数
d = abs(d); % 将相关系数绝对值
[j main_feature] = find(d>=0.8);
% % ±0.80-±1.00 高度相关
M = length(main_feature);
for k = 1:M
p = main_feature(1,k);
c1(:,k) = C1(:,p); % 提取降维特征
c2(:,k) = C2(:,p);
c3(:,k) = C3(:,p);
c4(:,k) = C4(:,p);
c5(:,k) = C5(:,p);
c6(:,k) = C6(:,p);
L1(:,k) = l1(:,p);
L2(:,k) = l2(:,p);
L3(:,k) = l3(:,p);
L4(:,k) = l4(:,p);
L5(:,k) = l5(:,p);
L6(:,k) = l6(:,p);
end
clearvars -except c1 L1 life1 life
%%
% 训练集及测试集的划分
% 输入量与输出量定义
% %设置训练集及测试集
Data = [c1;L1];
T =[life;life1];
input.data =Data';
output.data =[life;life1]';
[output.data ,ps]= mapminmax(output.data,0,1);
%序列的前 80% 用于训练,后 20% 用于测试
% 划分数据集的数目
n = 1575; %训练集,测试集样本数目划分
% 输入量训练集与测试集划分
for j=1:size(input.data,1)
input.XTrain(j,:) =input.data(j,1:n);
input.XTest(j,:) =input.data(j,n+1:end);
end
% 输入量数据结构转化(胞元结构)
input.XTrain ={input.XTrain};
input.XTest = {input.XTest};
% 输出量训练集与测试集划分,并数据结构转化
output.YTrain(1,:) = {output.data(1,1:n)};
output.YTest(1,:) = {output.data(1,n+1:end)};
% 标准化
%数据预处理,将训练数据标准化为具有零均值和单位方差。
mu = mean([input.XTrain{:}],2);
sig = std([input.XTrain{:}],0,2);
for i = 1:numel(input.XTrain)
input.XTrain{i} = (input.XTrain{i} - mu) ./ sig;
end
%%
% q =rng;
% rng(q)
w =1;
s =1;
% % % % % % 设定随机种子数
rng('default')
rng(0);
inputSize = size(input.XTrain{1,1},1); %数据输入x的特征维度
outputSize = size(output.YTrain{1,1},1); %数据输出y的特征维度
% for w =1:50
% for s =10:40 % 创建LSTM神经网络%
%创建LSTM回归网络,指定LSTM层的隐含单元个数
%序列预测,因此,输入原始数据特征值,输出为服役寿命的一维特征值。
% LSTM 层设置,参数设置
numhidden_units1=50;
numhidden_units2=29;
numhidden_units3=4;
numhidden_units4=2;
% lstm
layers = [ ...
sequenceInputLayer(inputSize) %输入层设置
% gruLayer(numhidden_units1,'Outputmode','sequence')
% dropoutLayer(0.5,'name','dropout_1')
% gruLayer(numhidden_units2,'Outputmode','sequence')
% dropoutLayer(0.5,'name','dropout_2')
lstmLayer(numhidden_units3,'Outputmode','sequence')
dropoutLayer(0.5,'name','dropout_3')
lstmLayer(numhidden_units4,'Outputmode','sequence')
dropoutLayer(0.5,'name','dropout_4')
fullyConnectedLayer(4) %全连接层设置(outputsize:预测值的特征维度)
fullyConnectedLayer(outputSize) %全连接层设置(outputsize:预测值的特征维度)
% tanhLayer('name','softmax')
regressionLayer]; %回归层(因为负荷预测值为连续值,所以为回归层)
maxepochs=500;
% 指定训练选项。
options = trainingOptions('adam', ... %优化算法
'MaxEpochs',maxepochs, ... %遍历样本最大循环数
'GradientThreshold',1,... %梯度阈值
'InitialLearnRate',0.0005, ... %初始学习率
'LearnRateSchedule','piecewise', ... % 学习率计划
'LearnRateDropPeriod',maxepochs/2, ... %250个epoch后学习率更新
'LearnRateDropFactor',0.5, ... %学习率衰减速度
'SequenceLength',n,... %LSTM时间步长
'MiniBatchSize',4,... % 批处理样本大小
'Shuffle','never',...
'Verbose',0,...
'Plots','training-progress');
% 是否重排数据顺序,防止数据中因连续异常值而影响预测精度
%训练LSTM
net = trainNetwork(input.XTrain,output.YTrain,layers,options);
% 预测
% 使用与训练数据相同的参数来归一化测试预测变量。
for i = 1:numel(input.XTest)
input.XTest{i} = (input.XTest{i} - mu) ./ sig;
end
% 使用 predict 对测试数据进行预测。为防止函数向数据添加填充,请指定小批量大小为 1(预测步数)。
YPred(w,s) = predict(net,input.XTest,'MiniBatchSize',1); % 测试集
% 将预测集进行反归一化,以方便计算标准差
YPred1(w,s) = mapminmax('reverse',YPred(w,s) ,ps); % 测试集反归一化
output.YTest1(w,s) = mapminmax('reverse',output.YTest,ps); % 测试集真实值的反归一化
%计算均方根误差 (RMSE)。
rmse(w,s) = sqrt(mean((YPred1{w,s}-output.YTest1{w,s}).^2)); %测试集
mae1=mean(abs(YPred1{w,s}-output.YTest1{w,s}));
% end
% end
% %
% 将预测值与测试数据进行比较
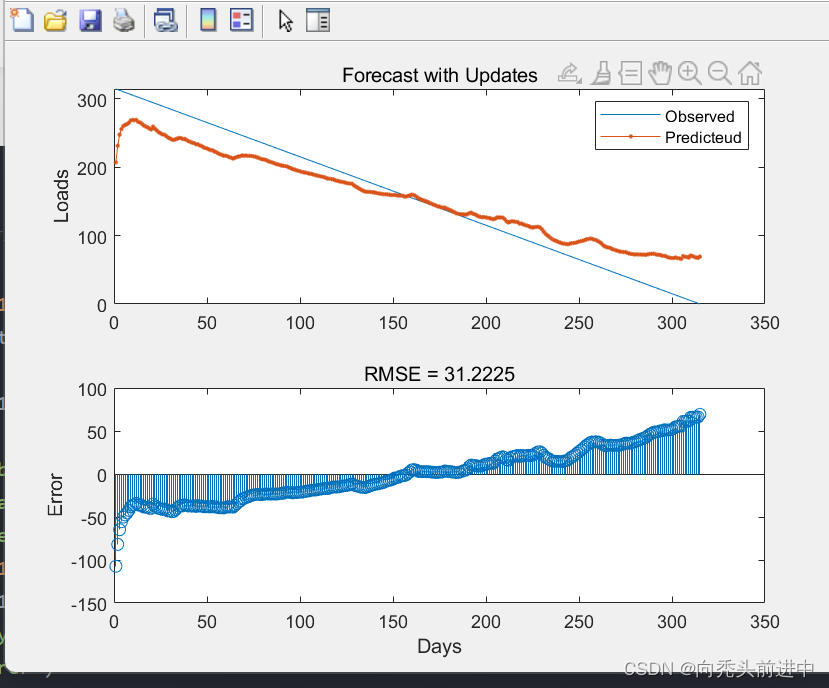
figure
subplot(2,1,1)
plot(output.YTest1{1,1})
hold on
plot(YPred1{1,1},'.-')
hold off
legend(["Observed" "Predicteud"]) % % 预测集数据对比
ylabel("Loads")
title("Forecast with Updates")
subplot(2,1,2)
stem(YPred1{1,1} - output.YTest1{1,1})
xlabel("Days")
ylabel("Error")
title("RMSE = " + rmse(1,1))
% %
% clearvars -except GRU2
2.预测结果(LSTM层数设置问题,不想调了)





















 1164
1164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









