







1、过程推导 - 了解BP原理
求出隐藏层的输出h1,h2,预测值o1,o2,错误率error的公式,并根据这些公式推导权重的梯度公式以及根据梯度求得权重的公式来更新权重。


2、数值计算 - 手动计算,掌握细节
代入初始值,求得隐藏层的输出h1,h2,预测值o1,o2,错误率error,并根据这些值更新权重的梯度,再由学习率确定更新完的权重。


3、代码实现 - numpy手推 + pytorch自动
numpy手推:
import numpy as np
def logisic(z):
return 1.0/(1.0+np.exp(-z))
#前向
def forward_propagate(w1,w2,w3,w4,w5,w6,w7,w8,x1,x2,y1,y2):
inh1=w1*x1+w3*x2
h1=logisic(inh1)
inh2=w2*x1+w4*x2
h2=logisic(inh2)
ino1=w5*h1+w7*h2
o1=logisic(ino1)
ino2=w6*h1+w8*h2
o2=logisic(ino2)
error=((o1-y1)**2+(o2-y2)**2)/2
return h1,h2,o1,o2,error
#反向传播
def back_propagate(h1,h2,o1,o2):
l1=(o1-y1)*(o1*(1-o1))
l2 =(o2-y2)*(o2*(1-o2))
m1=h1*(1-h1)
m2=h2*(1-h2)
s1=m1*x1*(l1*w5+l2*w6)
s2 = m2 * x1 * (l1 * w7 + l2 * w8)
s3 = m1 * x2 * (l1 * w5 + l2 * w6)
s4 = m2 * x2 * (l1 * w7 + l2 * w8)
s5=l1*h1
s6=l2*h1
s7=l1*h2
s8=l2*h2
return s1,s2,s3,s4,s5,s6,s7,s8
#更新参数
def update_w(s1,s2,s3,s4,s5,s6,s7,s8,w1,w2,w3,w4,w5,w6,w7,w8):
eta=1#学习率
w1=w1-eta*s1
w2 = w2 - eta * s2
w3 = w3 - eta * s3
w4 = w4 - eta * s4
w5 = w5 - eta * s5
w6 = w6 - eta * s6
w7 = w7 - eta * s7
w8 = w8 - eta * s8
return w1,w2,w3,w4,w5,w6,w7,w8
#输入初始数据
w1=0.2
w2=-0.4
w3=0.5
w4=0.6
w5=0.1
w6=-0.5
w7=-0.3
w8=0.8
y1=0.23
y2=-0.07
x1=0.5
x2=0.3
for i in range(1000):
h1,h2,o1,o2,error=forward_propagate(w1, w2, w3, w4, w5, w6, w7, w8, x1, x2, y1, y2)
s1,s2,s3,s4,s5,s6,s7,s8=back_propagate(h1, h2, o1, o2)
w1,w2,w3,w4,w5,w6,w7,w8=update_w(s1, s2, s3, s4, s5, s6, s7, s8, w1, w2, w3, w4, w5, w6, w7, w8)
if i%100==0:
print('第',i,'轮')
print('隐藏层h1为:', round(h1,2), '隐藏层h2为:', round(h2,2), '输出层o1为:', round(o1,2), '输出层o2为:', round(o2,2))
print('错误率为:', round(error,5))
print('梯度为:',round(s1,2),round(s2,2),round(s3,2),round(s4,2),round(s5,2),round(s6,2),round(s7,2),round(s8,2))
print('更新完的参数为:',round(w1,2),round(w2,2),round(w3,2),round(w4,2),round(w5,2),round(w6,2),round(w7,2),round(w8,2), '\n')



pytorch自动:
import torch
def logisic(z):
return 1.0/(1.0+torch.exp(-z))
#前向
def forward_propagate(x1,x2):
inh1=w1*x1+w3*x2
h1=logisic(inh1)
inh2=w2*x1+w4*x2
h2=logisic(inh2)
ino1=w5*h1+w7*h2
o1=logisic(ino1)
ino2=w6*h1+w8*h2
o2=logisic(ino2)
#error=((o1-y1)**2+(o2-y2)**2)/2
return o1,o2
#损失函数
def loss_function(x1,x2,y1,y2):
y1_prey,y2_prey=forward_propagate(x1,x2)
loss=((y1_prey-y1)**2+(y2_prey-y2)**2)/2
return loss
#反向传播--梯度能自动求
#更新参数
def update_w(w1,w2,w3,w4,w5,w6,w7,w8):
eta=1#学习率
w1.data=w1.data-eta*w1.grad.data
w2.data = w2.data - eta * w2.grad.data
w3.data = w3.data - eta *w3.grad.data
w4.data = w4.data - eta * w4.grad.data
w5.data = w5.data - eta * w5.grad.data
w6.data = w6.data- eta * w6.grad.data
w7.data = w7.data - eta *w7.grad.data
w8.data = w8.data- eta * w8.grad.data
return w1,w2,w3,w4,w5,w6,w7,w8
#输入初始数据
w1=torch.Tensor([0.2])
w1.requires_grad=True
w2=torch.Tensor([-0.4])
w2.requires_grad=True
w3=torch.Tensor([0.5])
w3.requires_grad=True
w4=torch.Tensor([0.6])
w4.requires_grad=True
w5=torch.Tensor([0.1])
w5.requires_grad=True
w6=torch.Tensor([-0.5])
w6.requires_grad=True
w7=torch.Tensor([-0.3])
w7.requires_grad=True
w8=torch.Tensor([0.8])
w8.requires_grad=True
y1=torch.Tensor([0.23])
y2=torch.Tensor([-0.07])
x1=torch.Tensor([0.5])
x2=torch.Tensor([0.3])
for i in range(1000):
o1,o2=forward_propagate( x1, x2)
L=loss_function(x1,x2,y1,y2)
L.backward()
#对于模型(函数)中的每一个可以求导的元素进行求导,L(模型,函数)对w(元素)求导,调用L.backward(),w.grad是L对w的导数。
if i%100==0:
print('第',i,'轮')
print( '输出层o1为:', o1.data, '输出层o2为:', o2.data)
print('错误率为:', round(L.item(),5))
print('梯度为:',w1.grad.data,2,w2.grad.data,w3.grad.data,w4.grad.data,w5.grad.data,w6.grad.data,w7.grad.data,w8.grad.data)
w1, w2, w3, w4, w5, w6, w7, w8 = update_w(w1, w2, w3, w4, w5, w6, w7, w8)
#因为梯度是累积的。如果不清零梯度,新的梯度会和之前的梯度相加
w1.grad.data.zero_()
w2.grad.data.zero_()
w3.grad.data.zero_()
w4.grad.data.zero_()
w5.grad.data.zero_()
w6.grad.data.zero_()
w7.grad.data.zero_()
w8.grad.data.zero_()
if i % 100 == 0:
print('更新完的参数为:',w1.data,w2.data,w3.data,w4.data,w5.data,w6.data,w7.data,w8.data, '\n')
#区分w1.data,w1,w1.item()
#w1.data:tensor([0.2084])
#w1:tensor([0.2084], requires_grad=True)
#w1.item(): 0.2084214836359024


1、对比【numpy】和【pytorch】程序,总结并陈述。
由上面的代码和结果可以看出,numpy和pytorch程序结果是是相同的,不同的是pytorch能够调用.backward()自动计算梯度,不用手动计算,只需要在权重那个张量上设置.requires_grad=True,并且每次更新完权重注意清零,因为梯度是累积的。如果不清零梯度,新的梯度会和之前的梯度相加。
对于模型(函数)中的每一个可以求导的元素进行求导,L(模型,函数)对w(元素)求导,调用L.backward(),w.grad是L对w的导数。
2、激活函数Sigmoid用PyTorch自带函数torch.sigmoid(),观察、总结并陈述。
def forward_propagate(x1,x2):
inh1=w1*x1+w3*x2
h1=torch.sigmoid(inh1)
inh2=w2*x1+w4*x2
h2=torch.sigmoid(inh2)
ino1=w5*h1+w7*h2
o1=torch.sigmoid(ino1)
ino2=w6*h1+w8*h2
o2=torch.sigmoid(ino2)
return o1,o2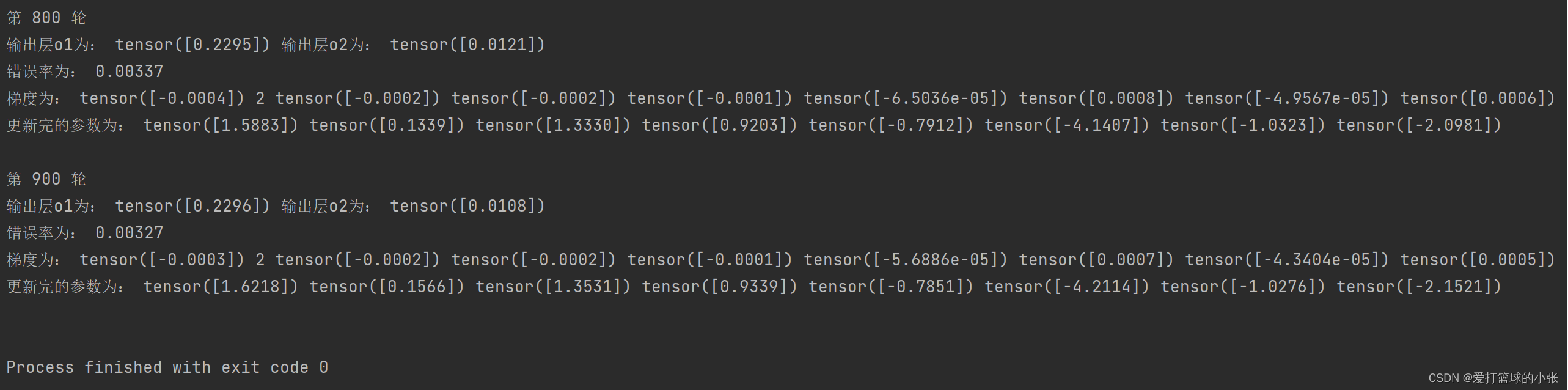
总结:对比结果,可以看到用PyTorch自带函数torch.sigmoid()与自己定义的激活函数效果相同
3、激活函数Sigmoid改变为Relu,观察、总结并陈述。
def forward_propagate(x1,x2):
inh1=w1*x1+w3*x2
h1=torch.nn.functional.relu(inh1)
inh2=w2*x1+w4*x2
h2=torch.nn.functional.relu(inh2)
ino1=w5*h1+w7*h2
o1=torch.nn.functional.relu(ino1)
ino2=w6*h1+w8*h2
o2=torch.nn.functional.relu(ino2)
return o1,o2
激活函数变了,相应的权重值也变了。
Sigmoid的优点:
sigmoid函数可以将实数映射到 [公式] 区间内。平滑、易于求导。对于模型分类效果不好的样本,采用sigmoid函数则会对模型进行较大程度的调整。这种模型调整策略是很棒的。
Relu的优点:
1.Relu计算量小,收敛速度更快一些;采用sigmoid等函数,算激活函数是(指数运算),计算量大;反向传播求误差梯度时,求导涉及除法,计算量相对大。
2.激活函数导数维持在1,可以有效缓解梯度消失和梯度爆炸问题;sigmoid函数很容易发生梯度消失,在只要输入的值不在(-5,5)之间,几乎就是梯度为0了
3.使用Relu会使部分神经元为0,这样就造成了网络的稀疏性,并且减少了参数之间的相互依赖关系,缓解了过拟合问题的发生。
4、损失函数MSE用PyTorch自带函数 t.nn.MSELoss()替代,观察、总结并陈述。
#损失函数
def loss_function(x1,x2,y1,y2):
y1_prey,y2_prey=forward_propagate(x1,x2)
#张量合并torch.stack(),合并完仍为张量,元素值是对应元素合并起来
y=torch.stack([y1,y2])
yprey= torch.stack([y1_prey,y2_prey])
#默认用于计算两个输入对应元素差值平方和的均值
l=torch.nn.MSELoss()
loss=l(y,yprey)
return loss
总结:效果与自定义损失函数效果大致相同。
5、损失函数MSE改变为交叉熵,观察、总结并陈述。
#损失函数
def loss_function(x1,x2,y1,y2):
y1_prey,y2_prey=forward_propagate(x1,x2)
#张量合并torch.stack(),合并完仍为张量,元素值是对应元素合并起来
y=torch.stack([y1,y2],dim=1)#dim=1,使之由一维的堆叠成2维的,不说的话,维数仍为1维
yprey= torch.stack([y1_prey,y2_prey],dim=1)
#yprey应该是2维的,预测标签 yprey 是一个二维张量,形状为 (N, C),其中 N 是样本数量,C 是类别数。每个样本对应一个长度为 C 的概率向量,表示该样本属于每个类别的概率。
# 真实标签 y 被弄成2维的张量,主要是为了与预测张量 yprey 的形状匹配。
l=torch.nn.CrossEntropyLoss()
loss=l(yprey,y)
return loss
总结:当学习率为1时,损失变成了很大的负数,减小一下学习率,能有效缓解,和之前的效果相比,使用交叉熵损失的损失更大一些。
6、改变步长,训练次数,观察、总结并陈述。
步长=1:

步长=0.1:

步长=3:

步长设为90,特意让他崩:

总结:步长为1或3时收敛速度较快,步长为0.1时稍慢。
训练5轮:

训练15轮:

训练50轮:

总结,随着训练轮数的提升,损失不断减少,但提升到一定程度时,效果就变化不大了
7、权值w1-w8初始值换为随机数,对比“指定权值”的结果,观察、总结并陈述。


总结:随机赋值收敛效果也可能很好,并且有可能比给定值收敛速度更快,效果更好。
8、权值w1-w8初始值换为0,观察、总结并陈述。
使用Relu激活函数时:

由前向传播的过程,以及Relu函数可以推得,相关参数均为0,参数不更新
Sigmoid函数:

收敛速度可能慢些,但最后能够达到很好的值。
9、全面总结反向传播原理和编码实现,认真写心得体会。

1、将公式手动推出来真的的很爽,先用numpy实现,之后用pytorch实现,pytorch中能够自动求梯度,方便了不少,但要注意.requires_grad=True。
2、让学习率变得很大很大,给他整崩了,也学到了学习率不能太大,太小也不好,收敛慢。
3、刚开始由于输出权重不一样检查了几遍,后来发现Sigmoid函数和Relu激活函数得到的最优权重值会是不同的。
4、pytorch里有很多自带的函数,比如激活函数和损失函数不需自己定义,很方便。但是也要注意该怎样使用。
5、关于权值初始化的话,还是不要初始化为0了,效果不好,随机数效果好些。
更正
在代码中误将损失说成了错误率,只有在分类中才有错误率。
说明
使用Sigmoid函数和Relu激活函数得到的最优权重值会是不同的。















 136
136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









