







Dynamic Head :Unifying Object Detection Heads with Attentions

作者针对目标检测中通过backbone提取特征金字塔后的输出后,会形成最基本的这种情况
R
L
×
H
×
W
×
C
\R^{L\times H\times W\times C}
RL×H×W×C,其中L代表金字塔输有多少层特征图,H和W代表特征图的高和宽,C代表特征图的通道.本文提出的就是分别在每一个维度上都分别应用注意力,然后进行嵌套堆砌,用公式表示为如下
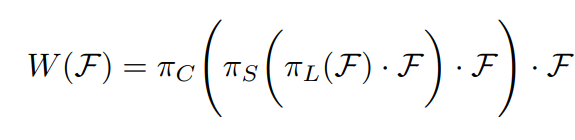
Scale-aware Attention
基于语义的重要程度动态的融合不同尺度的特征
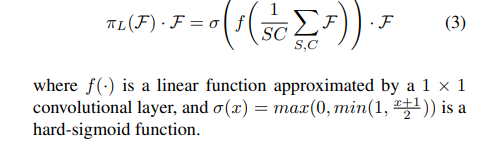
即在一层上进行空间和通道上面的全部求和,然后进行(1*1)卷积(相当于一个线性函数),最后进行 σ \sigma σ函数操作(相当于一个hard-sigmoid 函数).
Spatial-aware Attention 这部分作者说的很不详细,需要看一下代码.
在尺度注意的基础上,通过使用可变形卷积对位置的重要性进行学习

其中 K 是 稀 疏 采 样 点 的 数 量 , Δ p k 是 学 习 到 到 偏 移 位 置 , Δ m k 是 自 学 习 到 的 在 p k 的 重 要 性 标 量 K是稀疏采样点的数量,\Delta p_k是学习到到偏移位置,\Delta m_k是自学习到的在p_k的重要性标量 K是稀疏采样点的数量,Δpk是学习到到偏移位置,Δmk是自学习到的在pk的重要性标量
Task-aware Attention
动态的开关特征通道来有利于不同的任务的学习.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Grtg1nXp-1625114601787)(/home/brother/.config/Typora/typora-user-images/image-20210701123239176.png)]](https://img-blog.csdnimg.cn/20210701124451824.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3ExNTQwMTA4ODU3,size_16,color_FFFFFF,t_70)
θ 函 数 首 先 通 过 池 化 变 成 C ∗ 1 的 向 量 , 然 后 进 行 两 层 f c 中 间 加 一 个 激 活 函 数 后 变 成 四 个 , 这 四 个 值 通 过 偏 移 s i g m o i d 归 一 化 后 变 成 ( − 1 , 1 ) 的 范 围 , 再 和 ( 1 , 0 , 0 , 0 ) 想 加 后 得 到 最 终 的 α 1 α 2 β 1 β 2 再 通 过 上 面 的 m a x 函 数 来 控 制 每 一 个 通 道 的 输 出 \theta 函数首先通过池化变成C*1的向量,然后进行两层fc中间加一个激活函数后变成四个,\\ 这四个值通过偏移sigmoid归一化后变成(-1,1)的范围,\\再和(1,0,0,0)想加后得到最终的\alpha_1\alpha_2\beta_1\beta_2再通过上面的max函数来控制每一个通道的输出 θ函数首先通过池化变成C∗1的向量,然后进行两层fc中间加一个激活函数后变成四个,这四个值通过偏移sigmoid归一化后变成(−1,1)的范围,再和(1,0,0,0)想加后得到最终的α1α2β1β2再通过上面的max函数来控制每一个通道的输出
下面是整体的应用
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YQy3kMmd-1625114601788)(/home/brother/.config/Typora/typora-user-images/image-20210701124257331.png)]](https://img-blog.csdnimg.cn/20210701124649644.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3ExNTQwMTA4ODU3,size_16,color_FFFFFF,t_70)















 2233
2233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









