







DCGAN和CGAN的解读和学习
1.DCGAN
网络结构
DCGAN其主要贡献在于把原始GAN中的全连接层替换为了卷积层。具体如下:
- 首先是全卷积网络,这使用了跨步卷积代替了确定性的空间池化功能(例如最大池化等操作),从而能让网络能够学习自身的空间下采样。
- 其次是再卷积层特征上消除全连接层的趋势,全局池化就是一个最好的例子。
- 第三是采用了BatchNormalization,这个通过将输入归一化从而稳定了训练的过程,并有助于在梯度在更深的模型中进行流动,BN并不用于生成器输出层和鉴别器输入层。
- 使用了ReLU激活函数,并发现使用LeaklyReLU函数可以让正常工作,特别是对于更高分辨率的建模。
DCGAN的生成器结构可以用如下的图来表示:
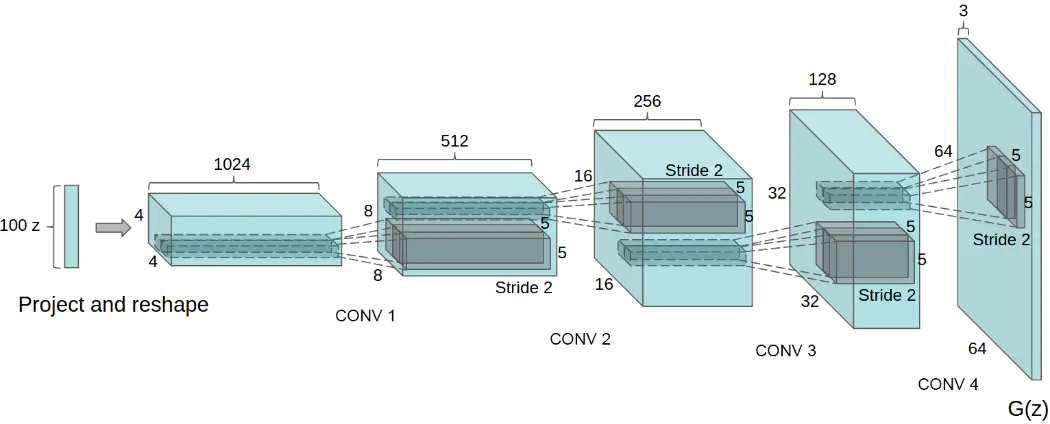
DCGAN的判别器和生成器的结构基本相反,其主要是通过进行卷积降维从而把输入的图像生成为一个标量,从而使用Sigmoid激活层确认其概率。
一些的DCGAN结构指南
- 用跨步卷积(针对鉴别器)和分数跨步卷积(针对生成器)替换掉所有的池化层。
- 在生成器和鉴别器中都使用BN,并且需要注意的是不对生成器的最后一层和鉴别器的输入层使用BN。
- 删除掉全连接的隐藏层从而实现更深层次的体系结构。
- 在生成器中全都使用ReLU激活函数,并在最后一层使用Tanh激活函数
- 在鉴别其中,对所有层使用LeakyReLU激活函数。
训练的一些细节:
- 使用了batch_size=128
- 所有权重都服从0中心方差为0.02的正态分布。
- 在LeakyReLU的泄露斜率值都为0.2
- 使用Adam的优化器,lr=0.0002, β 1 = 0.5 \beta 1=0.5 β1=0.5(作者发现0.9会有不稳定的情况发生)
代码实现:
# 使用pytorch在ununtu20上使用的代码
# gpu:Nvidia RTX2070s 8g显存
import os,math,torch,torchvision
import numpy as np
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
import torch.nn as nn
import random
from torch.utils.data import Dataset
random.seed(666)
torch.manual_seed(666)
from torch.autograd import Variable
import torch.nn.functional as F
os.makedirs('myImages', exist_ok=True)
#下面是一些初始化数据的定义
n_epochs=2
batch_size=512
lr=0.0002
b1=0.5
b2=0.999
n_cpu=8
latent_dim=100
img_size=64
channels=3
sample_interval=400
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# dataset = torchvision.datasets.MNIST(root='../../data/mnist',download=True,
# transform=transforms.Compose([transforms.Resize(size=img_size),
# transforms.ToTensor(),
# transforms.Normalize([0.5]*3,[0.5]*3)]
# )
# )
# dataloader = DataLoader(dataset=dataset,batch_size=batch_size,shuffle=False,num_workers=n_cpu)
import PIL.Image as Image
class CeleBaDataset(torch.utils.data.Dataset):
def __init__(self,img_root:str,transform=None):
super(CeleBaDataset,self).__init__()
temp_list=list()
for s in os.listdir(path=img_root):
if s.find('.png'):
temp_list.append(os.path.join(img_root,s))
self.datalist = temp_list
self.transform = transform
def __len__(self):
return len(self.datalist)
def __getitem__(self,idx):
image = Image.open(self.datalist[idx])
if self.transform:
image = self.transform(image)
return image
dataloader = DataLoader(dataset=CeleBaDataset(img_root='/home/hx/Desktop/WorkDisk/DadaSets/CelebA/Img/img_align_celeba_png.7z/img_align_celeba_png/'
,transform=transforms.Compose([transforms.Resize(size=img_size),
transforms.Resize(64),
transforms.CenterCrop(64),
transforms.ToTensor(),
transforms.Normalize([0.5]*3,[0.5]*3),
])
),
batch_size=batch_size,
num_workers=n_cpu,
shuffle=False,
pin_memory=True)
#%%
def weight_init(modules:torch.nn.Module):
for m in modules.modules():
if isinstance(m,nn.ConvTranspose2d):
nn.init.normal_(m.weight.data,0,0.02)
elif isinstance(m,nn.BatchNorm2d):
nn.init.normal_(m.weight.data,0,0.02)
def weight_init_apply(m:object):
if m.__class__.__name__.find('Conv'):
nn.init.normal_(m.weight.data,0,0.02)
elif m.__class__.__name__.find('BatchNorm'):
nn.init.normal_(m.weight.data,0,0.02)
class Generator(nn.Module):
def __init__(self):
super(Generator,self).__init__()
in_channels=[latent_dim,512,256,128,64]
out_channels=[512,256,128,64,3]
paddings=[0,1,1,1,1]
strides=[1,2,2,2,2]
layers=[]
for i in range(5):
layers.append(nn.BatchNorm2d(num_features=in_channels[i]))
layers.append(nn.ConvTranspose2d(in_channels=in_channels[i],
out_channels=out_channels[i],
kernel_size=4,
stride=strides[i],
padding=paddings[i]))
if i != 4:
layers.append(nn.LeakyReLU(negative_slope=0.2,inplace=True))
else:
layers.append(nn.Tanh())
self.G=nn.Sequential(*layers)
def forward(self,x):
return self.G(x)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator,self).__init__()
layers=[]
def block(in_channels,out_channels,stride=2,padding=1,if_bn=True,if_relu=True):
if if_bn:
layers.append(nn.BatchNorm2d(in_channels))
layers.append(nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=4,stride=stride,padding=padding))
if if_relu:
layers.append(nn.LeakyReLU(negative_slope=0.2,inplace=True))
else:
layers.append(nn.Sigmoid())
block(3,64,stride=2,padding=1,if_bn=False) # 此时64*32*32
block(64,128,2,1) # 此时128*16*16
block(128,256,2,1) # 此时256*8*8
block(256,512,2,1) # 此时512*4*4
block(512,1,1,0,if_relu=False) # 此时1*1*1
self.D=nn.Sequential(*layers)
def forward(self,x):
return self.D(x)
#%%
generator = Generator()
weight_init(generator)
discriminator=Discriminator()
weight_init(discriminator)
loss_fn = torch.nn.BCELoss()
generator.to(device)
discriminator.to(device)
loss_fn.to(device)
opm_G = torch.optim.Adam(generator.parameters(),lr=lr,betas=(b1,b2))
opm_D = torch.optim.Adam(discriminator.parameters(),lr=lr,betas=(b1,b2))
#%%
data = CeleBaDataset(img_root='/home/hx/Desktop/WorkDisk/DadaSets/CelebA/Img/img_align_celeba_png.7z/img_align_celeba_png/')
data.__getitem__(10000)
#%%
for epoch in range(20):
for i,img in enumerate(dataloader):
img = img.to(device)
real = torch.ones((img.shape[0],1),device=device)
fake = torch.zeros((img.shape[0],1),device=device)
z = torch.randn(size=(img.shape[0],latent_dim,1,1),device=device)
opm_D.zero_grad()
real_loss = loss_fn(discriminator(img).view(img.shape[0],-1),real)
fake_loss = loss_fn(discriminator(generator(z).detach())view(img.shape[0],-1),fake)
d_loss = (real_loss+fake_loss)/2
d_loss.backward()
opm_D.step()
print('Dloss:',d_loss)
opm_G.zero_grad()
z = torch.randn(size=(img.shape[0],latent_dim,1,1),device=device)
g_loss = loss_fn(discriminator(generator(z)).view(img.shape[0],-1),fake)
g_loss.backward()
opm_G.step()
print('Gloss:',g_loss)
print('epoch:{}Dloss:{}Gloss:{}',epoch,d_loss,g_loss)
最后的图像生成效果 待跑完。。。
2.CGAN
有时候简单的想法却有着一些很有用的效果,比方说就是CGAN,其思想很简单的来说就是,在原本的 n o i s e noise noise输入中增加一些维度(一般来说这个维度都是使用了one-hot向量来表示,比方说MINIST有10个不同的向量,那么这个需要增加的维度就是10个维度,其中使用one-hot表达,即:每一个维度对应一个变量,如果一个为1那么其他就为0),这个维度用来表示你想要输出的属性,并在最后的损失函数中增加关于生成的是否按照要求生成的一个损失,这就是CGAN的基本原理。
关于损失函数,原始GAN的损失函数可以用如下的公式进行表示:
E
x
∼
P
r
e
a
l
(
x
)
l
o
g
(
D
(
x
)
)
+
E
z
∼
P
z
(
z
)
l
o
g
(
1
−
D
(
G
(
z
)
)
)
E_{x\sim P_{real}(x)}log(D(x))+E_{z\sim P_{z(z)}}log(1-D(G(z)))\\
Ex∼Preal(x)log(D(x))+Ez∼Pz(z)log(1−D(G(z)))
CGAN的损失函数被修改了为如下:
E
x
∼
P
r
e
a
l
(
x
)
l
o
g
(
D
(
x
∣
y
)
)
+
E
z
∼
P
z
(
z
)
l
o
g
(
1
−
D
(
G
(
z
∣
y
)
)
)
E_{x\sim P_{real}(x)}log(D(x|y))+E_{z\sim P_{z(z)}}log(1-D(G(z|y)))\\
Ex∼Preal(x)log(D(x∣y))+Ez∼Pz(z)log(1−D(G(z∣y)))
其基本思路为:我是一个带标签的东西,生成器带着这个标签生成了数据,并且判别器也带着这个标签来判别数据,并且这个数据的标签就是dataloader中取出来的标签,如果生成的照片和这个照片的风格不一致,那么判别器就可以顺着这个标签带来的梯度就会比较大,那么这个判别器就能够很轻易的判断这个图片是一张假的图片,那么就会导致生成器的误差,其梯度也会顺着这个方向来进行判断,那样的话生成器就可以通过调整这个误差来更好的生成图片,为什么用one-hot来判断的方式是因为每一个种类有着自己单独的一个维度,这样的话梯度可以更好的顺利沿着过来,从而能够更方便的找到这个维度的梯度方向而不用拟合一个一个变量带着好几个含义的输入(这样的拟合对于神经网络的层数有着更好的要求),one-hot向量的优势就是在一起。`















 547
547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









