










写在前面的话
GAN是新发展起来而且发展迅速的领域,由于我也是初步调研,因此结合《生成对抗网络入门指南》这本书以及一些该领域发展历程具有重要意义的一些论文进行介绍,尽可能对GAN有一个初步的了解。主要包括:GAN,一些数学基本概念,cGAN,DCGAN,InfoGAN,Improved Techniques for Training GANs,Pix2Pix,WGAN,Progressively Growing of GANS,StackGAN,CycleGAN,SAGAN,最后再总结。目前很多GAN的相关最新具有开创性的论文还没有细看,所以肯定有许多不足,如有错误还请指出,不胜感激。
如果说选两篇必须看的话我认为就是cycleGAN和pix2pix了。最近尝试用GAN做一些东西,但是就是不收敛,内心有些小崩溃(︶^︶)
1. GAN
GAN(Generative Adversarial Networks),生成对抗网络,基本原理来自于博弈学范畴的纳什平衡原理,即任何一方无法通过自身的行为而增加自己的收益。
- G是一个生成图像的网络,它接收一个随机的噪声
z,通过这个噪声生成图像,记做G(z)。 - D是一个判别网络,判别一张图像是不是“真实的”。它的输入可以是一张图像,输出
D(x)代表x为真实图像的概率。
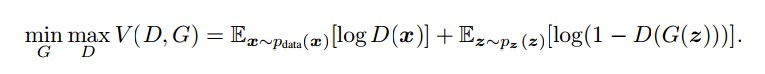
该损失函数如何理解?
首先明确,最原始的GAN论文由Good Fellow提出,该想法主要是解决无监督学习问题。该损失函数分为两部分,D损失与G损失。式子中包含D的部分就是D损失,包含G的就是G损失。 x ∼ p d a t a ( x ) x{\sim}p_{data(x)} x∼pdata(x) 表示输入属于真实的数据, x ∼ p z ( z ) x{\sim}p_{z(z)} x∼pz(z) 表示输入属于噪声。要使得判别器D尽可能输出结果较大(对应前面的 m a x max max),使得生成器G其输出结果较小(对应前面的 m i n min min),G生成的数据输入到判别器D后要尽可能使其变大,即欺骗过判别器(对应 ( 1 − D ( G ( z ) ) ) (1-D(G(z))) (1−D(G(z)))),可见要满足 m a x D max D maxD ,但又要同时降低G的loss,这样就形成了博弈。
为什么GAN需要两个网络,G和D的作用分别是什么?
G和D缺一不可,G的作用是模拟真实的数据分布,基于极大似然原理求得最终结果,但是这时候却没有一个评判的标准,那么就需要D网络来输出G的输出与真实分布的差异(可以通过推导得出最终的JS散度,详细不再描述),G和D不断训练博弈才能达到最终的平衡。
在原始代码中,G和D均由几层感知机构成。
2. Basic conception
-
生成模型,生成模型是指在给定某些隐含参数的条件下,随机生成观测数据的模型,给观测值和标注数据序列指定一个联合概率分布。可以用来直接对数据建模。
- 表示出数据的确切分布
- 只能做到新数据的生成(GAN的用途)
-
自动编码器,自动编码器有数据压缩的功能,但较多应用于实现生成模型的功能,可以单独使用解码器作为生成模型,在编码层输入任意数据,解码器都可以生成对应的生成数据
-
最大似然估计,这是GAN基于的数学模型,最大对数似然估计
-
散度,主要用来GAN收敛性能的一些推导中会使用到
- KL散度,KL散度,是一种量化两种概率分布P和Q之间差异的方式,又叫相对熵
K L ( P ∣ ∣ Q ) = E x ∼ P l o g P Q = ∫ x P ( x ) l o g ( P ( x ) Q ( x ) ) d x KL(P||Q) = E_{x\sim P}log\frac{P}{Q} = \int_{x}{P(x)log(\frac{P(x)}{Q(x)})}dx KL(P∣∣Q)=Ex∼PlogQP=∫xP(x)log(Q(x)P(x))dx - JS散度,由于KL散度不具有对称性,所以进行了变换,提出了JS散度
J S ( P ∣ Q ) = 1 2 K L ( P ∣ ∣ P + Q 2 ) + 1 2 K L ( Q ∣ ∣ P + Q 2 ) JS(P|Q) = \frac{1}{2}KL(P||\frac{P+Q}{2}) + \frac{1}{2}KL(Q||\frac{P+Q}{2}) JS(P∣Q)=21KL(P∣∣2P+Q)+21KL(Q∣∣2P+Q)
- KL散度,KL散度,是一种量化两种概率分布P和Q之间差异的方式,又叫相对熵
由第一点中可以知道,GAN有个很明确的缺点,生成器生成的数据没有明确的表示,D、G网络必须很好的同步,来避免 Helvetica scenario 的情况出现,即G将太多的z值压缩为相同的x,失去了生成多样性样本的能力。
为什么在神经网络中使用交叉熵损失函数,而不是KL散度?这是因为KL散度=交叉熵-熵,在对极大似然估计求解的时候添加了常数项。这里不做详细公式推导。
3. cGAN
cGAN是在GAN基础上做的一种改进,通过给原始GAN的生成器和判别器添加额外的条件信息,实现条件生成模型。这是一个有监督学习,可以通过损失函数看出添加了标签条件,即通过 P ( x ∣ y ) P(x|y) P(x∣y) 与 P ( z ∣ y ) P(z|y) P(z∣y) 反求 P ( y ∣ x ) P(y|x) P(y∣x) 与 P ( z ∣ x ) P(z|x) P(z∣x)
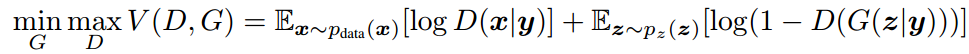
在 pytorch 中实现方式是在G、D网络的输入添加一个 embedding 的变量,该变量与原输入 concat 后作为新的输入。函数采用 nn.embedding 。含义是给定一个编号,嵌入层就能返回这个编号对应的嵌入向量,嵌入向量反映了各个编号代表的符号之间的语义关系。
4. DCGAN
之前有提到,之前的GAN中G和D网络均由几层感知机构成。DCGAN(Deep Convolutional GAN),判别器和生成器都使用了卷积神经网络(CNN)来替代GAN 中的多层感知机,同时为了使整个网络可微,去掉了CNN 中的池化层,另外将全连接层以全局池化层替代以减轻计算量。
DCGAN 相比于GAN的改进包含以下几个方面:
- 在生成器和判别器中都添加了批归一化
- 去掉了全连接层,使用池化层替代
- 生成器的输出层使用Tanh激活函数,其他层使用ReLU或LeakyReLU
其实就是把感知机换成卷积,增加全局性以及一定程度上减小参数量。但是目前有一点没有理解,DCGAN的源码G网络初始是一个线性层,后面接的卷积层以及上采样,还没有理解为什么第一层是线性层?
5. InfoGAN
InfoGAN,是一种无监督学习网络,可适用于各类复杂的数据集。该网络输入分成两部分,c和z。c可以理解为可解释的隐变量(隐藏编码),z是随机噪声。希望通过约束c与生成器输出的关系,使得c的维度对应生成器输出的语义特征
互信息公式:
I
(
X
;
Y
)
=
H
(
X
)
−
H
(
X
∣
Y
)
=
H
(
Y
)
−
H
(
Y
∣
X
)
I(X;Y) = H(X) - H(X|Y) = H(Y) - H(Y|X)
I(X;Y)=H(X)−H(X∣Y)=H(Y)−H(Y∣X)
由互信息公式可知,当X与Y互相独立的时候, I = 0 I = 0 I=0。如果X与Y相关程度很高的话,互信息会非常大。也就是说给定任意输入 x ∼ P G ( x ) x{\sim}P_G(x) x∼PG(x),希望生成器的 P G ( c ∣ x ) P_G(c|x) PG(c∣x) 有一个相对较小的熵,即希望隐藏编码c的信息在生成过程中不会流失,因此得到如下损失

引入两种信息
- 辅助信息,以手写数字为例,比如笔画粗细,倾斜度等。
- 隐藏信息
6. Improved Techniques for Training GANs
提出几种提升GAN稳定性的方法。(这一部分没有看源码,因此理解可能不是很准确)
- 特征匹配(feature matching),为G指定新的目标,不直接最大化D的输出,而是要求G生成与统计信息相匹配的数据。个人理解,就是尽可能相似。
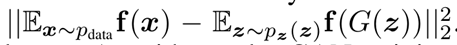
- 小批量的训练判别器(minibatch discrimination),使用了minibatch的方法,G的输出可能指向许多相似点的相似方向,但D的梯度无法分辨,不能收敛到正确分布。因此将其分成很多patch。

- 历史平均(Historical averaging),公式中 θ [ i ] {\theta}[i] θ[i] 表示在 i i i 时刻的参数。这个项在网络训练过程中也会更新。加入这个项后,梯度就不容易进入稳定的轨道,能够继续向均衡点更新。

- 类别标签平滑(One-side label smoothing),判别器的目标函数中正负样本的系数不再是0-1,而是α和β。

- 虚拟批归一化(Virtual Batch Normalization),BN层有个缺点是会使生成的一个batch中,每张图像之间存在关联,为解决这个问题,训练开始前选择一个固定的reference batch,每次算出这个特定的batch的均值和方差,再对它们对训练中的batch进行Norm,缺点是进行了两次前向传播,增加了计算成本,因此只在G中使用。
7. Pix2Pix
cGAN学习的是条件生成模型,适合于图像到图像的转换任务,以输入图像为条件并生成相应的输出图像。该论文就是基于cGAN。在cGAN的损失加上L1损失,G网络采用Unet,D网络采用PatchGAN。
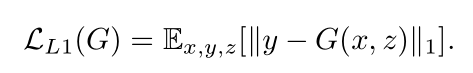

L1 Loss用于生成图像的大致结构、轮廓等,也可以说是图像的低频部分,而cGAN主要用于生成细节,是图像的高频部分。L1限制了D网络仅对高频结构进行建模,只需要关注局部图像块中的结构,PatchGAN可以使得训练过程变得更加高效,同时也可以针对更大的而图像数据集进行训练。
PatchGAN的思想是,既然GAN只用于构建高频信息,那么就不需要将整张图片输入到判别器中,让判别器对图像的每个大小为N x N的patch做真假判别就可以了。因为不同的patch之间可以认为是相互独立的。pix2pix对一张图片切割成不同的N x N大小的patch,判别器对每一个patch做真假判别,将一张图片所有patch的结果取平均作为最终的判别器输出。该操作常用于图像修复和风格迁移中。
-
优点:pix2pix巧妙的利用了GAN的框架来为“Image-to-Image translation”的一类问题提供了通用框架。利用U-Net提升细节,并且利用 PatchGAN 来处理图像的高频部分。
-
缺点:训练需要大量的成对图片,比如白天转黑夜,则需要大量的同一个地方的白天和黑夜的图像。
8. WGAN
引入 Wasserstein距离, 也称 EM距离,就是把生成数据分布到真实数据分布的最小成本。当两个分布越接近的时候,由KL以及JS散度可以求得为常数,这样会导致无法产生有用的梯度从而优化整个网络,而EM距离具备一个连续可用的梯度。
W
(
P
0
,
P
θ
)
=
∣
θ
∣
W(P_0, P_{\theta}) = |\theta|
W(P0,Pθ)=∣θ∣
- 去掉对数,直接求距离,也就是去掉了D最后的激活层
- 更新D的参数并进行裁剪,保证权值严格限制在一定范围内,使其满足
1-Lipschitz条件,从而使得网络保持正常的梯度优化(关于W距离的求解,必须使其满足该条件,关于W距离详细推导我也没看懂) - 采用不同的优化器(
RMSProp或SGD)
之后还有 WGAN-GP, WGAN-DIV,GP是指加上了惩罚项,用来约束D,DIV的源码还没细看。
WGAN里面的细节很多,G和D都是多层感知机构成,但是效果确实不错,我理解的还不足够,还需要多加理解。
9. Progressively Growing of GANS
该论文也是提出一些训练的技巧,目的是提升GAN网络的质量和稳定性。(这一部分也没有看源码)
- 多尺度架构(MultiScale Archetecture),真实图像被下采样到分辨率为4*4,8*8等,最高为1024*1024, G首先生成4*4的图像,直到达到收敛, 然后不断增大分辨率,该策略极大的稳定了训练。

- Fading in New Layers,该结构类似与resnet,比如看G部分,将新的32*32输出层添加到网络后,将使用简单的最近邻插值将 16*16 层的输出投影到 32*32 尺寸中,投影的图层 *(1-a),并与*a的新输出图层相连,形成新的32*32。A由0到1线性缩放,当a到1时,从16*16 开始的最近邻插值将为0,这种平滑过渡的方式稳定了训练。

-
小批量标准偏差(MiniBatch Standard Deviation),在D的末尾添加一个小批处理层,该层学习一个大张量,将输入激活投射到一个统计数据数组。在minibatch中为每个示例生成一组单独的统计信息,并将其连接到层的输出,以便鉴别器可以在内部使用这些统计信息。首先计算出小批中每个空间位置的每个特征的标准差。然后我们对所有特征和空间位置进行平均,得到一个值。复制值,并将其连接到所有空间位置和小批处理上,生成一个额外的(常量)特征映射。这一层可以插入到标识符的任何位置
-
均衡学习率,G和D的训练速度一般是不一致的,为保持一致性,调节超参数,对G和D使用不同的学习率。
10. StackGAN
提出了 Stacked Generative Adversarial Networks (StackGAN) 结构,用于根据文字描述,生成对应的 256 * 256 的真实图像(首次这么高的分辨率)。
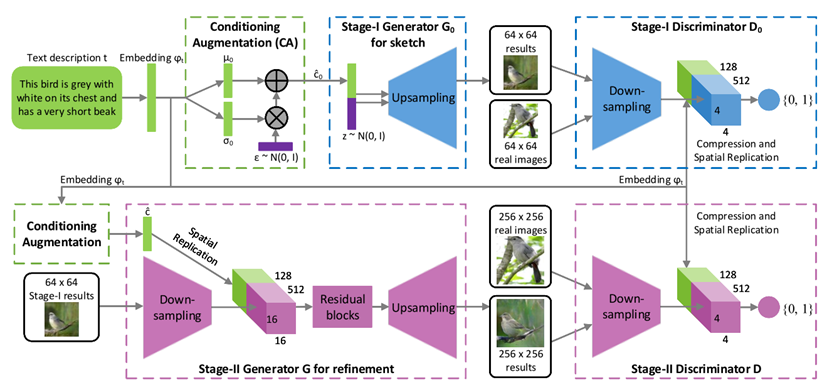
首先是 Stage-I,根据给定的文字描述,勾勒初始的形状和色彩,生成低分辨率的图像。Stage I 是一个标准的cGAN,输入是z和c。在之前提到了是使用embedding的方式将c嵌入到输入,但是embedding是一个高维的,text数量少,如果直接将embedding作为c,那么潜变量在潜空间就比较稀疏,为避免过拟合,G的loss里加入了对这个降维的正则化。
然后 Stage-II 根据 Stage-I 生成的低分辨率图像以及原始文字描述,生成具有更多细节的高分辨率图像。这个阶段可以重新捕获被 Stage-I 忽略的文字描述细节,修正 Stage-I 的的结果的缺陷,并添加改良的细节。
- 提出 Conditioning Augmentation 技术,源码中是写了一个类。
对于 text-to-image 生成任务,text-image 训练数据对(image + text)数量有限,这将导致文本条件多样性的稀疏性(sparsity in the text conditioning manifold),而这种稀疏性使得 GAN 很难训练。
11. CycleGAN
提出一种在缺少成对数据的情况下,学习从源数据域X到目标数据域Y的方法。目标是使用一个对抗损失函数,学习映射G:X → Y ,使得判别器难以区分图像 G(X)与图像Y。因为这样的映射受到巨大的限制,所以为映射G 添加了一个相反的映射F:Y → X,使他们成对,同时加入一个循环一致性损失函数 (cycle consistency loss),以确保 F(G(X)) ≈ X(反之亦然)。

不适合做有形变的Task,需要满足双射,即参与映射的两个集合,里面的元素必然是一一对应的。
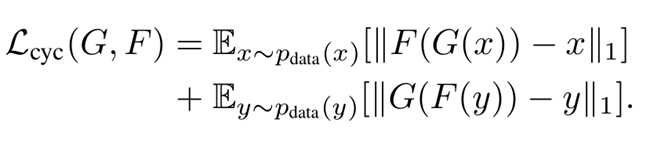
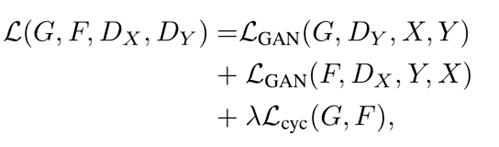
我觉得该论文最大的贡献就是提出循环一致性,确实可以增加稳定性,缺点就是训练会非常慢,毕竟四个网络。
12. SAGAN
在GAN网络中,SA——Self Attention,自注意力机制,而且引入谱归一化。原论文的核心思想就在下面了, β j , i \beta_{j,i} βj,i 表示合成第 j j j 个区域时模型对第 i i i 个区域的影响程度。整体的 o ⃗ \vec o o 是注意力层,角标代表区域。

看公式很枯燥,结合论文中的图应该可以理解,其实就是要学习三个参数, W f W_f Wf, W g W_g Wg, W v W_v Wv,均是由1*1的conv构成,这些变量的通道数有所变化,将其缩小为原通道数的 1 8 \frac{1}{8} 81,减小内存压力。最后得到输出 y i = γ o i + x i y_i = \gamma o_i + x_i yi=γoi+xi其中 γ \gamma γ 也是需要学习的,逐渐学会为非本地特征分配权重。

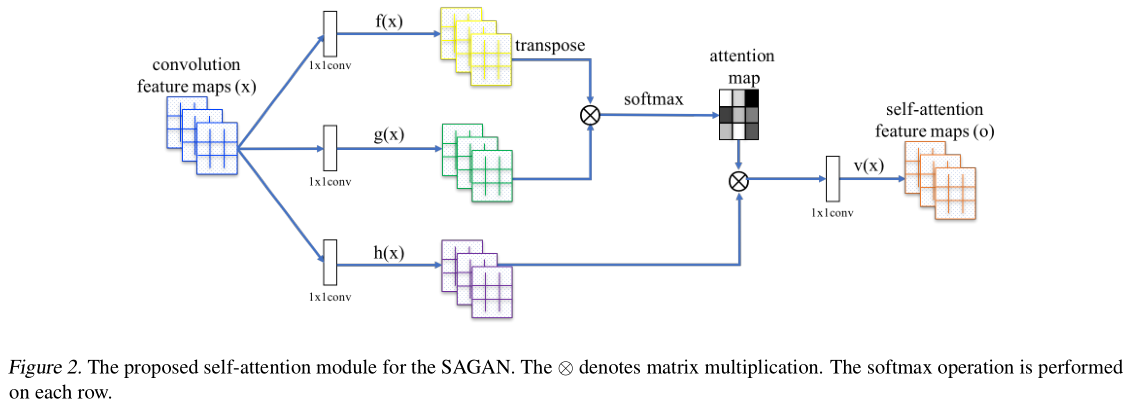
在SAGAN里用到了谱归一化约束,这里说一下我的理解。谱归一化约束就是通过约束每一层网络的权重矩阵的谱范数(谱范数就是对应矩阵A的最大奇异值),增强GAN在训练中的稳定性(要满足稳定性必须得满足Lipschitz条件)。将神经网络的每一层参数W作SVD分解,将其最大奇异值限定为1,这样参数就满足了 1-Lipschitz条件,每一次更新都除以W最大的奇异值,这样最大的拉伸系数不会超过1,这样才会满足 Lipschitz连续性 。
使用了谱归一化就不能使用BN或其他归一化,因为BN的除以方差或乘以缩放因子会明显破坏Lipschitz连续性。
关于为什么必须要使其满足Lipschitz连续性,是因为该理论的前提是采用WGAN的损失,只有当满足1阶Lipschitz条件,才能求得W距离,其损失计算就是求了个期望,所以晕晕(((φ(◎ロ◎;)φ)))
总结
总结的肯定不完善,甚至有可能会有错误,慢慢学习中,目前在阅读18年后的一些关于GAN的论文了,待回顾更新…

参考文献
[1] Goodfellow I J , Pouget-Abadie J , Mirza M , et al. Generative Adversarial Networks[J]. Advances in Neural Information Processing Systems, 2014, 3:2672-2680.
[2] Mirza M , Osindero S . Conditional Generative Adversarial Nets[J]. Computer Science, 2014:2672-2680.
[3] Radford A , Metz L , Chintala S . Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks[J]. Computer ence, 2015.
[4] Chen X , Duan Y , Houthooft R , et al. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets[C]// Neural Information Processing Systems (NIPS). 2016…
[5] Salimans, Tim et al. “Improved Techniques for Training GANs.” NIPS (2016) .
[6] Isola, Phillip et al. “Image-to-Image Translation with Conditional Adversarial Networks.” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017): 5967-5976…
[7] Karras, Tero et al. “Progressive Growing of GANs for Improved Quality, Stability, and Variation.” ArXiv abs/1710.10196 (2018): n. pag.
[8] Arjovsky, Martín et al. “Wasserstein GAN.” ArXiv abs/1701.07875 (2017): n. pag.
[9] Zhang, Han et al. “StackGAN: Text to Photo-Realistic Image Synthesis with Stacked Generative Adversarial Networks.” 2017 IEEE International Conference on Computer Vision (ICCV) (2017): 5908-5916.
[10] Zhu, Jun-Yan et al. “Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks.” 2017 IEEE International Conference on Computer Vision (ICCV) (2017): 2242-2251.
[11] Zhang, Han et al. “Self-Attention Generative Adversarial Networks.” ICML (2019).
[12] 《生成对抗网络入门指南》 史丹青编著
[13] 还有很多查的资料啦~尤其是公式推导
[14] PyTorch-GAN
后续工作
关于GAN方面的论文会一直阅读下去,尽可能的去记录下来一些具有领航意义的论文以及理解,要阅读的论文我也不会限制于我所研究的方向,希望能够通过GAN让我顺利毕业(~ ̄▽ ̄)~

















 4300
4300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









