







SVM 支持向量机
写在前面的话: 本文都属于个人在学习过程中的笔记以及加上自己理解,如果有不正确的地方欢迎指出批评。
一. 基本概念
1. 什么是SVM
支持向量机(Support Vector Machine, SVM)是一类二元分类的线性分类器,用于监督学习。
2. 为什么引入SVM
首先说到分类则有 线性可分 与 线性不可分 两种基本的分类方式,线性可分则相对容易,但是线性不可分应该怎么做?那么就引入了SVM,将原始数据 映射 到新的空间,使其在新的空间内线性可分,再投影回到原来的空间,即可得到其边界。
3. SVM分类
- 硬间隔支持向量机
- 软间隔支持向量机
- 非线性支持向量机
二. 深入理解
1. Hard Margin SVM
SVM的基本原理就是通过建立一个超平面 (Hyperplane) 寻找最大边际超平面 (MMH)。
首先建立超平面
w
T
x
+
b
=
0
w^Tx + b =0
wTx+b=0
我们可以将数据集分为两类,用
y
y
y 表示类别,则有 -1,1 两种情况,可以写出决策方程(
Ф
(
x
)
Ф(x)
Ф(x)是某个确定空间转换函数,作用是将
x
x
x映射到更高维度)
y
(
x
)
=
w
T
Ф
(
x
)
+
b
y(x) = w^TФ(x) + b
y(x)=wTФ(x)+b
可以看下图,两条虚线为支持向量(决策边界),b为间隔
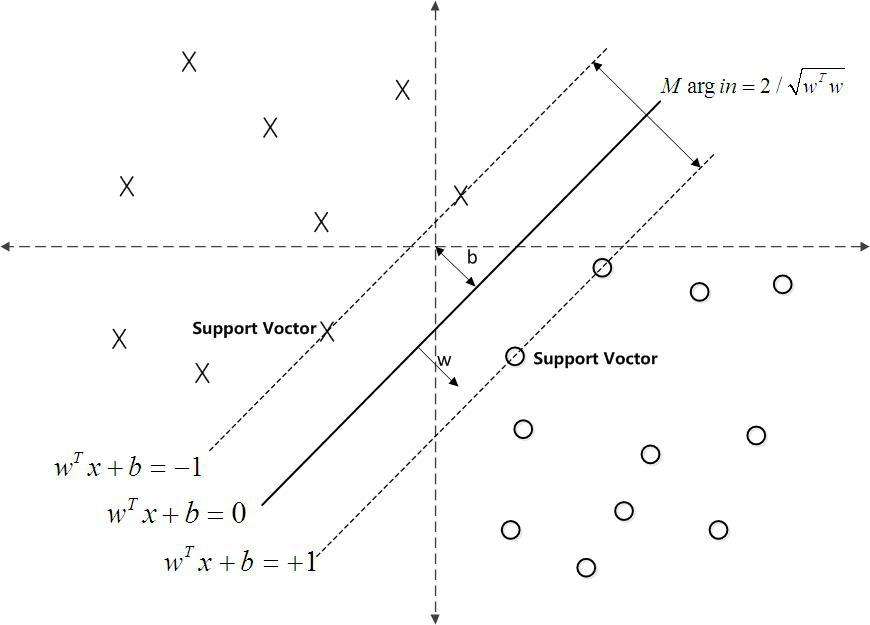
如果
y
(
x
i
)
>
0
则
y
i
=
+
1
y({x_i}) > 0 \quad则\quad y_i = +1
y(xi)>0则yi=+1
y
(
x
i
)
<
0
则
y
i
=
−
1
y({x_i}) < 0 \quad则\quad y_i = -1
y(xi)<0则yi=−1
可以得出
y
i
⋅
y
(
x
i
)
>
0
y_i \cdot y(x_i)>0
yi⋅y(xi)>0
我们的优化目标就是找到一条线(
w
w
w 和
b
b
b),使得离该线最近的点能够最远。将点到直线的距离化简得
y
i
⋅
(
w
T
⋅
Ф
(
x
i
)
+
b
)
∣
∣
w
∣
∣
\frac{y_i \cdot (w^T \cdot Ф(x_i) + b)}{||w||}
∣∣w∣∣yi⋅(wT⋅Ф(xi)+b)
则我们的优化目标,即 Loss function:
a
r
g
m
a
x
w
,
b
{
1
∣
∣
w
∣
∣
m
i
n
i
[
y
i
⋅
(
w
T
⋅
Ф
(
x
i
)
+
b
)
]
}
arg \ max_{w,b} \ \{\frac{1}{||w||}min_i[y_i \cdot (w^T \cdot Ф(x_i) + b)]\}
arg maxw,b {∣∣w∣∣1mini[yi⋅(wT⋅Ф(xi)+b)]}
对于决策方程 (
w
w
w 和
b
b
b) 可以通过方所使得其结果值
∣
Y
∣
≥
1
|Y| ≥1
∣Y∣≥1
⇒
\Rightarrow
⇒
y
i
⋅
(
w
T
⋅
Ф
(
x
i
)
+
b
y_i \cdot (w^T \cdot Ф(x_i) + b
yi⋅(wT⋅Ф(xi)+b ,则只用考虑
a
r
g
m
a
x
w
,
b
1
∣
∣
w
∣
∣
arg \ max_{w,b} \ \frac{1}{||w||}
arg maxw,b ∣∣w∣∣1
求其极大值,用的方法为 拉格朗日乘子法(简而言之,引入λ构造新函数对每一项求偏导均为0),我么引入
a
a
a 得到
L
(
w
,
b
,
a
)
=
1
2
∣
∣
w
∣
∣
2
−
∑
i
=
1
n
a
i
(
y
i
(
w
T
⋅
Ф
(
x
i
)
+
b
)
)
L(w,b,a) = \frac{1}{2}||w||^2 - \sum^{n}_{i=1}a_i(y_i(w^T \cdot Ф(x_i) + b))
L(w,b,a)=21∣∣w∣∣2−i=1∑nai(yi(wT⋅Ф(xi)+b))
对
w
w
w求偏导得到
w
=
∑
i
=
1
n
a
i
y
i
Ф
(
x
n
)
w = \sum^{n}_{i=1}a_iy_iФ(x_n)
w=∑i=1naiyiФ(xn),对
b
b
b求偏导得到
0
=
∑
i
=
1
n
a
i
y
i
0 = \sum^{n}_{i=1}a_iy_i
0=∑i=1naiyi,将其带入原函数得
m
a
x
a
∑
i
=
1
n
a
i
−
1
2
∑
i
=
1
n
∑
j
=
1
n
a
i
a
j
y
i
y
j
(
Ф
(
x
i
)
Ф
(
x
j
)
)
s
.
t
.
{
1
2
∑
i
=
1
n
a
i
y
i
=
0
a
i
≥
0
max_a \sum^{n}_{i=1}a_i - \frac{1}{2} \sum^{n}_{i=1} \sum^{n}_{j=1}a_ia_jy_iy_j(Ф(x_i)Ф(x_j)) \qquad s.t. \{\begin{array}{cc} \frac{1}{2} \sum^{n}_{i=1} a_iy_i = 0\\ a_i ≥ 0 \end{array}
maxai=1∑nai−21i=1∑nj=1∑naiajyiyj(Ф(xi)Ф(xj))s.t.{21∑i=1naiyi=0ai≥0
求其对偶函数得 目标函数,即
m
i
n
a
1
2
∑
i
=
1
n
∑
j
=
1
n
a
i
a
j
y
i
y
j
(
Ф
(
x
i
)
Ф
(
x
j
)
)
−
∑
i
=
1
n
a
i
s
.
t
.
{
∑
i
=
1
n
a
i
y
i
=
0
a
i
≥
0
min_a \ \frac{1}{2} \sum^{n}_{i=1} \sum^{n}_{j=1}a_ia_jy_iy_j(Ф(x_i)Ф(x_j)) - \sum^{n}_{i=1}a_i\qquad s.t. \{\begin{array}{cc} \sum^{n}_{i=1} a_iy_i = 0\\ a_i ≥ 0 \end{array}
mina 21i=1∑nj=1∑naiajyiyj(Ф(xi)Ф(xj))−i=1∑nais.t.{∑i=1naiyi=0ai≥0
2. Soft Margin SVM
任何数据都可以看做是有噪声存在的,即影响原数据的上下扰动。那么线性可分就显得并没有那么完美,用之前的方法一定会有误差,因此我们就要在最小误差的情况下进行分类,我们引入误差项。写出 Loss function: m a x w , b , ξ 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 n ξ i s . t . { y i ( w ⋅ x i + b ) ≥ 1 − ξ i ξ i ≥ 0 max_{w,b,ξ} \ \frac{1}{2}||w||^2 + C\sum^{n}_{i=1}ξ_i \qquad s.t. \{\begin{array}{cc} y_i(w \cdot x_i +b) ≥ 1 - ξ_i\\ ξ_i ≥ 0 \end{array} maxw,b,ξ 21∣∣w∣∣2+Ci=1∑nξis.t.{yi(w⋅xi+b)≥1−ξiξi≥0
- 正则化 :只考虑支持向量其实就是一种正则化的形式。它强迫模型在处理样本特征的时候变得更加简单。 C C C 是正则化系数。
求其对偶函数得 目标函数,即 m i n a 1 2 ∑ i = 1 n ∑ j = 1 n a i a j y i y j ( x i x j ) − ∑ i = 1 n a i s . t . { ∑ i = 1 n a i y i = 0 0 < a i ≤ C min_a \ \frac{1}{2} \sum^{n}_{i=1} \sum^{n}_{j=1}a_ia_jy_iy_j(x_ix_j) - \sum^{n}_{i=1}a_i\qquad s.t. \{\begin{array}{cc} \sum^{n}_{i=1} a_iy_i = 0\\ 0 < a_i ≤ C \end{array} mina 21i=1∑nj=1∑naiajyiyj(xixj)−i=1∑nais.t.{∑i=1naiyi=00<ai≤C
3. Kernel (+ soft) SVM
先放入一个视频链接SVM with polynomial kernel visualization(YouTube),如下图
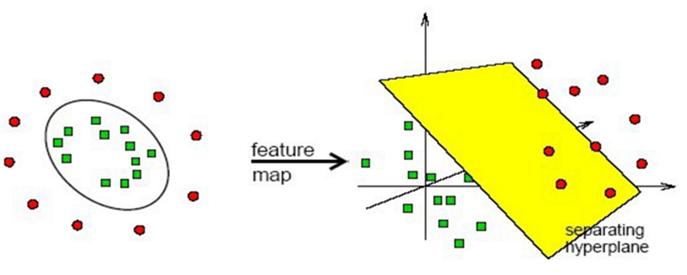
使用核函数解决线性不可分问题,在低维中计算,通过核函数映射到新的特征空间(高维),构造出 Hyperplane ,使得原本线性不可分的样本可能在核空间可分。
- 多项式核函数: K ( x 1 , x 2 ) = ( ∣ ∣ x 1 − x 2 ∣ ∣ a + r ) b a , b , r 为 常 数 \quad \quad K(x_1,x_2) = (||x_1 - x_2||^a + r)^b \quad a,b,r为常数 K(x1,x2)=(∣∣x1−x2∣∣a+r)ba,b,r为常数
- 高斯核函数RBF: K ( x 1 , x 2 ) = e x p ( − ∣ ∣ x 1 − x 2 ∣ ∣ 2 2 σ 2 ) \quad \quad K(x_1,x_2) = exp(- \frac{||x_1 - x_2||^2}{2σ^2}) K(x1,x2)=exp(−2σ2∣∣x1−x2∣∣2)
高斯核是无穷维的。
4. LR 与 SVM 的比较
- Loss 不同
- SVM 仅考虑支持向量,但有约束条件
- SVM不能给出概率结果
- 处理非线性问题用核函数更好
- LR 可解释性更强
三. python实现
支持向量机有两种:
- SVC,支持向量分类,用于分类问题;
- SVR,支持向量回归,用于回归问题。
1. 线性支持向量机(Linear SVMs)
import numpy as np
import pylab as pl
from sklearn import datasets, svm
svc = svm.SVC(kernel='linear')
iris = datasets.load_iris()
X = iris.data[:, :2]
y = iris.target
svc.fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0, degree=3, gamma=0.0,
kernel=‘linear’, max_iter=-1, probability=False, random_state=None,
shrinking=True, tol=0.001, verbose=False)
- 线性支持向量分类器(LinearSVC):对于线性核函数
kernel="linear"给了我们线性的决策边界:两类之间的分离边界是直线。
2. 支持向量与正则化
X, y = X[np.in1d(y, [1, 2])], y[np.in1d(y, [1, 2])]
pl.scatter(svc.support_vectors_[:, 0], svc.support_vectors_[:, 1], s=80, facecolors='none', zorder=10)
- 支持向量:就是最靠近分离边界的样本点(可以看本文第一张图)。支持向量机的工作方式就是找到这些支持向量,它们被认为是在二分类问题中最具代表性的样本点。
- 支持向量的坐标可以通过方法
support_vectors_来找到
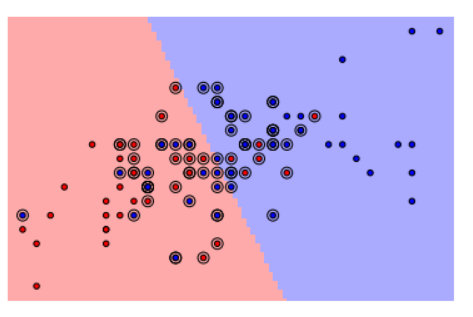
svc = svm.SVC(kernel='linear', C=1e3)
- 正则项可以通过调整系数
C
C
C 来决定 (默认为
C
=
1
C = 1
C=1):
- 小的C值:将会有很多支持向量。决策边界=类别A的平均值-类别B的平均值
- 大的C值:将会有较少的支持向量。决策边界是被大多数支持向量所决定。
3. 核函数
产生非线性分类边界
- linear,线性核,产生线性分类边界。计算效率最高,需要数据少
- poly ,多项式核,产生多项式分类边界
- rbf,径向基函数,即高斯核,是根据与每一个支持向量的距离来决定分类边界的。它的映射到无线维的。需大量数据
svc = svm.SVC(kernel='linear')
svc = svm.SVC(kernel='poly', degree=4)
svc = svm.SVC(kernel='rbf', gamma=1e2)
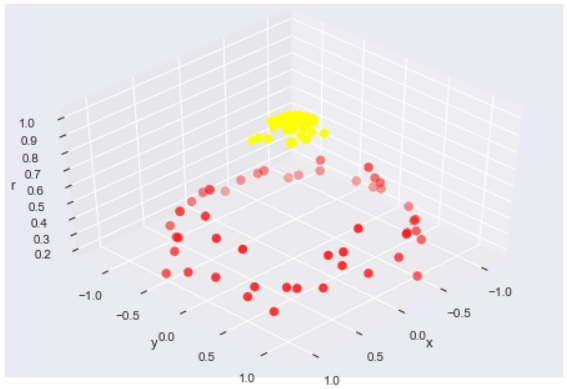
以二维点做个例子
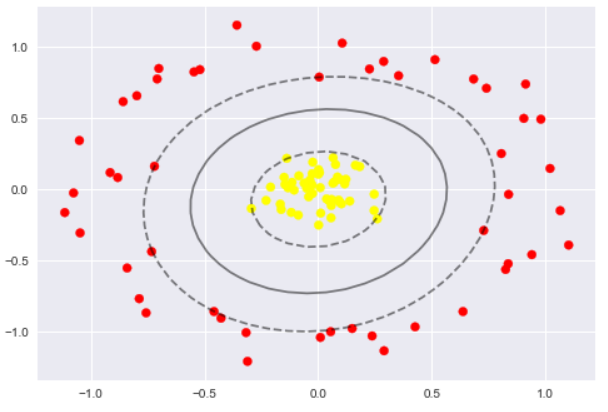
from sklearn.datasets.samples_generator import make_circles
X,y = make_circles(100, factor=.1, noise=.1)
clf = SVC(kernel='linear').fit(X, y)
plt.scatter(X[:,0], X[:,1], c=y, s=50, cmap='autumn')
from mpl_toolkits import mplot3d
r = np.exp(-(X**2).sum(1))
def plot_3D(elev=30, azim=30, X=X, y=y):
ax = plt.subplot(projection='3d')
ax.scatter3D(X[:,0], X[:,1], r, c=y, s=50, cmap='autumn')
ax.view_init(elev=elev, azim=azim)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('r')
plot_3D(elev=45, azim=45, X=X, y=y)
clf = SVC(kernel='rbf', C=1E6)
clf.fit(X,y)
plt.scatter(X[:,0], X[:,1], c=y, s=50, cmap='autumn')
plot_svc_decision_func(clf)
plt.scatter(clf.support_vectors_[:,0], clf.support_vectors_[:, 1],
s=300, lw=1, facecolors='none')
四. 参考资料
[1] 支持向量机通俗导论(理解SVM的三层境界)
[2] 机器学习 周志华
[3] 各种学习视频















 957
957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









