






论文地址:https://arxiv.org/pdf/2101.11782.pdf
代码地址:https://github.com/txdet/FCOSPss
摘要
我们展示了一个简单的NMS-free、端到端目标检测框架,该网络是对one-stage目标检测器(如FCOS检测模型[24])的最小修改。与原来的one-stage目标检测器相比,我们达到了同等甚至更高的检测精度。它以几乎相同的推断速度执行检测,同时更简单,因为现在在推断期间消除了后处理NMS(非最大抑制)。如果网络只能为图像中的每个GT对象实例识别一个正样本,那么就没有必要使用NMS。这是通过附加一个紧凑的PSS头为每个实例来自动选择单个阳性样本(见图1)。由于学习目标涉及到一对多和一对一的标签分配,一些训练实例的标签存在冲突,使学习具有挑战性。我们证明,通过使用stop-gradient操作,我们可以成功地解决这一问题,并训练检测器。
在COCO数据集上,我们的简单设计获得了比带有NMS后处理的FCOS基线检测器和最近的端到端无NMS检测器更优越的性能。我们广泛的消融研究证明了设计选择的合理性。

1.介绍
目标检测是计算机视觉的一项基本任务,近年来利用深度学习技术取得了显著进展。它的目的是预测图像中的一组边界框及其对应的类别。现代的物体检测方法分为两大类:Faster R-CNN[19]为代表的two-stage检测器,以及YOLO[18]、SSD[15]、RetinaNet[13]等one-stage检测器。近年来,单级探测器因其简单、高性能而越来越受到人们的青睐。由于FCOS[24]和FoveaBox[10]等无锚检测器的引入,社区倾向于认识到锚可能不是目标检测不可或缺的设计选择,因此只有nms是整个管道中唯一的启发式后处理。
在文献中,NMS操作几乎总是在主流的目标检测器中使用。在训练过程中,一个ground-truth对象总是有多个阳性正样本,因此使用NMS进行检测的必要性。例如,在[10,24]中,在一个对象的中心区域内,CNN feature map上的所有位置都被赋予正标签。因此,多个网络输出对应于一个目标对象。结果是,对于推理,需要一种机制(即NMS)来在所有正样本框中选择最佳正样本。
最近,一些方法[1,34]将检测制定为集到集的预测问题,并利用匈牙利匹配算法来解决为每个ground-truth box寻找一个阳性样本的问题。在匈牙利匹配算法中,模型自适应地选择损失最小的网络输出作为目标的正样本,其他样本被认为是负样本。这样,NMS就可以被移除,检测器也可以端到端训练。Wang等人[26]设计了一种不使用transformer的全卷积网络(FCN),实现了端到端无nms的目标检测。我们在这里的工作遵循这一思路,设计了更简单的FCN检测器,具有更强的检测精度。
具体地说,我们想设计一个简单的、高性能的、完全卷积的目标检测网络,它不需要nms,而且端到端的可训练。我们在FCOS检测器[24]上实例化这样的设计,对网络本身进行最小的修改,如图1所示。实际上,对FCOS唯一的修改是:
- 引入了一个紧凑的正样本选择器(PSS)头,为每个对象实例选择最优正样本;
- 重新设计学习目标,成功训练检测器。
为了训练网络,我们保留了原来FCOS的分类损失,这是很重要的,因为它提供了丰富的监督,编码了理想的不变性编码。正如3.4中所讨论的,单对多和一对一标签分配之间的标签差异导致网络训练具有挑战性。在这里,我们提出了一种简单的非对称优化方案:我们引入stop-grad操作(见图1)来阻止附加PSS头相关的梯度传递到原始FCOS网络参数。
我们从经验上展示了停止-渐进操作的有效性(图3)。这种停止-渐进操作在以下情况下特别有用。网络包含两个子网A和子网B。B的优化依赖于A的收敛,而A的优化对B依赖不大,因此不对称。
我们的方法不依赖注意力机制,如transformer,或跨层特征聚合,如3D max filtering[26]。我们提出的检测器,称为FCOSPSS,有以下优点:
- 通过消除NMS,检测变得更加简单。由于继承自FCOS的简单性,FCOSPSS完全兼容其他fcn可解决的任务
- 我们表明,通过引入一个紧凑的PSS头,NMS可以被消除,与普通FCOS相比,其计算开销可以忽略不计。
- 所提出的PSS是灵活的,在本质上PSS的头部是可学习的NMS。因为通过设计,我们保持了普通的FCOS头和原始检测器一样工作,所以FCOSPSS提供了使用NMS的灵活性。例如,一旦训练,可以选择丢弃PSS头,使用FCOSPSS作为标准的FCOS。
- 我们报告了与标准的FCOS[24]和ATSS[32]检测器相比,在COCO数据集上有相当的甚至提升的检测结果,以及最近的NMSfree检测方法。
- 所提出的PSS头也适用于其他基于锚盒的探测器,如RetinaNet。通过将PSS附加到改进的RetinaNet检测器上,我们获得了有希望的结果,该检测器在每个位置使用一个正方形锚盒,并采用ATSS自适应训练样本选择,以提高[32]2中的检测精度。
- 同样的想法也适用于其他一些实例识别任务。例如,我们可以从实例分割框架中删除NMS,例如[27,28]。我们希望本文的工作能够对基于FCOS检测器的实例分割[2,23,29,31]、关键点检测[22]、文本点检测[16]和跟踪[6]等工作有所帮助。
2.相关工作
由于目标检测具有广泛的下游应用,因此在计算机视觉中得到了广泛的研究。传统的方法使用手工制作的特征(如HoG、SIFT)来解决在一组候选边界框上作为分类的检测问题。随着深度神经网络的发展,现代目标检测方法可分为two-stage检测器、one-stage检测器和最新的end-to-end检测器三类。
Two-stage Object Detector :其中一条研究线集中在two-stage检测器上,如Faster R-CNN [19],首先生成区域建议,然后细化对每个建议的检测。Mask R-CNN[7]在Faster R-CNN的基础上增加了一个Mask预测分支,可以用来解决一些实例级的识别任务,包括实例分割和姿态估计。
虽然two-stage检测器仍有很多应用,但由于one-stage更简单、更简洁的设计和强大的性能,社区已经将研究重点转移到one-stage检测器。
One-stage Object Detector:第二种是开发高效的One-stage目标检测器[10,15,18,24],基于提取的特征图和密集锚点直接进行密集预测。它们基本上是基于滑动窗口。基于锚定的检测器,例如YOLO[18]和SSD[15],使用一组预定义的锚定盒来预测对象类别和锚定盒框偏移量。请注意,锚点最初是在Faster R-CNN的RPN模块中提出的,用于生成建议框。
在One-stage目标检测中,负样本必然比正样本多,导致训练数据不平衡。因此,提出了难例子挖掘和 focal loss函数[13]等技术来缓解不平衡训练问题。
近年来,人们致力于设计anchor-free检测器[10,24]。FCOS[24]和Foveabox[10]以靶标中心区域为阳性样本。此外,FCOS引入了所谓的中心度评分,使NMS更准确。[32]的作者提出了一种自适应训练样本选择(ATSS)方案来自动定义正的和负的训练样本,尽管仍然使用启发式设计的规则。PAA[9]设计了一种概率锚点分配策略,与那些启发式的IoU硬标签分配策略相比,训练更容易。除了改进FCOS的分配策略[9,32]外,为了进一步提高无锚检测器的性能,还对检测特征[17]、损失函数[11]进行了研究。
然而,one-stage和two-stage目标检测器都需要一个后处理过程,即非最大抑制(NMS),以合并重复检测。也就是说,大多数最先进的检测器都不是端到端可训练的。
End-to-end Object Detector :最近,一些工作提出了端到端对象检测框架,将NMS从管道中移除。其中一部开拓性作品可以归功于[20]。该方法将目标检测定义为序列对序列学习任务,并使用LSTM-RNN实现该思想。DETR[1]在目标检测中引入了基于变压器的注意机制。基本上,[20]中的序列对序列学习任务现在是通过基于自我注意的transformer来并行解决的,而不是RNN。Deformable DETR[34]通过提出只关注一小部分关键采样点来加速DETR的训练收敛。
最近,DeFCN[26]采用一对一匹配策略,基于全卷积网络实现端到端目标检测,具有竞争性能。值得注意的是,DeFCN[26]可能是第一次证明,无需依赖于LSTM-RNN或自我注意机制的序列对序列(或设置对设置)学习,就可以从检测器中删除NMS。[21]的工作与DeFCN[26]在一对一标签分配和使用辅助头来帮助训练方面有相似之处。[21]报告的性能不如DeFCN[26]。
我们从[26]中获得了设计一对一标签分配策略的灵感,如Equ.(3)。显然,这种一对一的标签分配直接影响最终的无nms检测精度。其中一个主要区别是,我们使用一个简单的二元分类头来为每个实例选择一个正样本,而DeFCN为此设计了3D max滤波,它聚合了多尺度特征来抑制重复检测。第二,如前所述,我们的目标是尽量保持原有的FCOS探测器的完整。接下来,我们提出了FCOSPSS。
3.论文方法
FCOSPSS的整体网络结构非常简单,如图1所示。唯一的改动是PSS头多了两个卷积层,其他部分都和FCOS[24]一样。我们首先介绍整个训练目标。
3.1 整个训练目标
我们的整体训练目标可以制定如下:
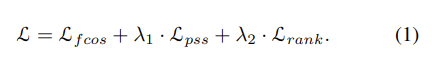
λ1, λ2是平衡系数。Lfcos包含与原始FCOS[24]中完全相同的损失项,即使用focal loss进行C-way分类(对于COCO数据集,C = 80),使用GIoU损失进行边界框回归,以及中心度损失。
我们在所有的实验中都将λ2设为0.25,因为rank损失不是必须的。如表9所示,排rank的损失使最终的检测精度略有提高(0.2 0.3点在map上)。我们在这里包括它,因为它不会引入太多的训练复杂性。
3.1.1 PSS Loss Lpss
Lpss是我们框架成功的关键,它是与正样本选择器(positive sample selector)相关的分类损失。回想一下,我们的目标是为图像中的每个实例选择一个且仅为一个正样本。这里新增加的PSS头有望达到这一目标。我们将一对一正标签分配的细节推迟到3.3,假设每个实例有一个最优的ground-truth正标签可用。如图1所示,PSS头的输出是RH×W×1的映射。让我们表示σ(pss)是这个映射的一个点。那么σ(pss)的学习目标是1,如果它对应于一个实例的正样本;否则负面标签。因此,最简单的方法是训练一个二分类器。这里,为了利用FCOS中的C-way分类器,我们再次将损失项表述为C-way分类。
具体来说,损失项计算的focal loss之间的乘以分数(我们已经包括中心度评分σ(ctr)在这里使它与原始的FCOS兼容。如FCOS[24]所示,中心度可能会略微改善结果):
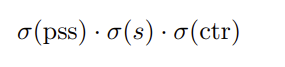
针对C类的ground-truth标签,σ(s)为FCOS分类器s输出的得分图。请注意,这个分类器和普通FCOS分类器之间的区别是,我们现在对图像中的每个对象实例只有一个正样本。在学习之后,理想情况下,σ(pss)能够激活一个并且只有一个对象实例的阳性样本。
3.1.2 Ranking Loss Lrank
我们的初步实验表明,在目标函数中加入一个rank损失项有助于改进我们 NMS-free检测器的性能。具体来说,对于每个训练图像,我们增加了eque(2)的rank损失:
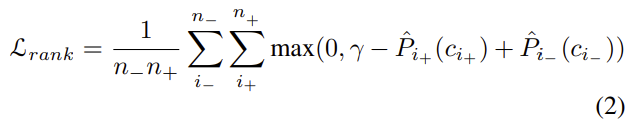
在这里,γ是代表正锚和负锚之间的界限的超参数。在我们的实验中,我们默认设置γ = 0.5。n-和n+分别表示负样本和正样本的数量。Pi+ (ci+)表示阳性样本i+属于类别ci+的分类得分,Pi-(ci_)表示阴性样本i_属于类别ci_的分类得分。在我们的实验中,我们从所有的负样本中选择得分为Pi_(ci_)的前n_名,我们为所有的实验设置n_ = 100。
3.2 One-to-many标签分配
一对多标签分配对训练图像中的每个对象实例分配多个gt边框是目前广泛采用的目标检测方法。这是最直观的表述,因为在为检测标记ground truth边框时自然存在模糊性:如果一个标记框移动几个像素,得到的框仍然代表相同的实例,因此也被视为正训练样本。这也是为什么使用一对一标签分配的原因,一个静态规则(与训练期间的预测质量无关的规则)不太可能产生满意的结果,因为很难找到定义良好的标签。
在一个实例中拥有多个框的好处是,这样一个丰富的表示可以提高对编码长宽比、平移等不变性的强分类器的学习。
其结果是多个检测框围绕着一个单一的真实例。因此,为了清理此类检测器的原始输出,NMS变得不可或缺。尽管依赖于启发式NMS后处理,我们相信这种一对多标签分配有其至关重要的意义,因为:i)更丰富的训练数据有助于学习一些被证明是有益的有帮助的不变性;ii.)这也与目前几乎所有深度学习技术中数据增强的实际实践相一致。因此,我们认为保持与一对多标签分配相关的FCOS训练目标作为我们新检测器的重要组成部分是很重要的。
3.3 One-to-one 标签分配
在执行一对一标签分配时,我们需要为每个ground-truth实例j (cj和bj为ground-truth类别标签和边框坐标)选择最佳匹配的锚点i(这里锚表示一个锚盒或不同检测器中的锚点)。
正如[26]中指出的,最好的匹配应该包括分类匹配和位置匹配。即当前检测网络在训练过程中的分类质量和定位质量都应该对匹配分数Qi,j起作用。我们将分数定义为Equ(3):
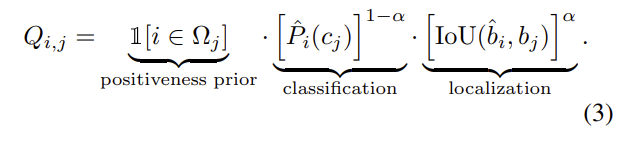
其中,
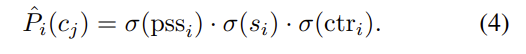
其中si和ctri表示锚点i的分类得分和中心度预测,pssi表示二分类掩模预测得分,是正样本选择器PSS的输出。Pi(cj)为属于类别cj的锚i的分类得分。注意,σ(·)[0,1]是将分数归一化为概率的sigmoid函数。在Equ(4),我们假设三个概率是独立的,使它们的乘积形成Pi (cj)。这可能并不严格。
Qi,j表示锚i与ground-truth实例j的匹配得分。cj为实例j的ground-truth类别标签,P i(cj)表示类别标签cj对应锚i的预测得分。bi为锚i预测框坐标;bj为ground-truth实例j的边框坐标,超参数α[0,1]用于调整分类与定位的比例。
给定一个ground-truth实例j,并不是所有的锚都适合赋值为正样本,特别是ground-truth实例j方框区域之外的锚。这里j表示实例j的候选正锚集合。FCOS[24]限制j仅包含bj中心区域的锚点,RetinaNet[13]限制bj与j锚点之间的IoU。j的设计最终会影响到模型的性能。例如,ATSS[32]和PAA[9]在不改变模型结构的情况下,通过改进j的设计,进一步提高了FCOS[24]模型的性能。
如等式Equ(3),在我们的例子中,j仅仅是原始检测器使用的正样本。例如,FCOSPSS使用实例j中心区域的锚点为j,与FCOS相同;而ATSSPSS的j在[32]中使用了ATSS采样策略。
最后,每个ground-truth实例j在图像分配给一个标签用匈牙利算法通过求解两偶图匹配[1、26],通过最大化∑jQi,j,通过为每个实例j寻找最优锚i。我们发现类似的性能如果使用简单 top-one选择替换匈牙利匹配。
3.4 两个分类损失的冲突
回顾一下总体目标Equ. (1),最小化两个相关的分类目标项。第一个是Lfcos中的普通FCOS分类(一对多)。假设一个特定的对象实例被分配了k个正样本(锚盒或点)。第二种分类是PSS部分Lpss。Lpss的主要职责是将一个且仅一个阳性样本(从k个阳性样本中)与其他样本区分开来。因此,在训练PSS分类器时,给Lfcos的k个正样本中的k-1个为负的ground-truth标签。这可能会增加拟合的难度,因为这两项的标签不一致。
换句话说,在训练模型时,将几个样本同时分配为正样本和负样本。这种冲突可能会对最终的模型性能产生不利影响。本文提出了一种简单有效的非对称优化方案。具体来说,我们停止与附加的PSS头部(图1中的虚线框)相关的梯度传递到原始的FCOS网络参数(不包括虚线框的网络)。这在图1中被标记为stop-grad。因此,新的PSS头将对原始FCOS检测器的训练产生最小的影响。
3.5 Stop Gradient
在数学上,停止梯度操作使网络的一部分在[4]训练过程中保持恒定。在我们的例子中,当SGD更新原FCOS参数时,PSS头被设置为常数,因此没有PSS的梯度向后到网络的其余部分。
设θ = {θfcos, θpss}为所有优化网络变量,分为两部分。从本质上讲,stop-gradient的作用类似于对这两组变量的交替优化,我们想要解:
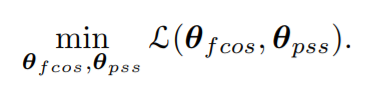
我们可以交替地解决两个子问题(t索引迭代):

当求方程Equ. (5)时,梯度w.r.t, θpss为零。
注意,我们在这里所做的带有stop gradient的SGD只是近似于上面的交替优化,因为我们并没有解决每一个收敛的子问题。
我们可以用一个变换来解决这两个子问题。即初始化θpss = 0,求解Equ. (5)收敛后,再求解Equ. (6)直到收敛。这相当于训练原FCOS直到收敛和冻结FCOS,然后只训练PSS头部直到收敛。我们的实验表明,这导致检测性能稍差,但训练计算时间明显更长。详见§4.2.2。
我们的经验表明,使用stop gradient的结果一致地提高了模型的精度,参见
图3所示。

4.实验
在本节中,我们将在大规模数据集COCO[14]上测试我们提出的方法。
4.1. 实验细节
我们使用MMDetection工具箱[3]来实现所有的模型。为了公平比较,我们使用基于NMS的检测方法[24,32]作为基线检测器,并将我们的正样本选择器(PSS)附加到消除后处理NMS的工作中。所有的消融比较都是基于带有FPN的ResNet50[8]骨干网络,由预训练的ImageNet模型初始化。除非另有说明,我们以“3×”训练时间表训练所有模型(36epochs)。具体来说,我们在8个tesla拉- v100 gpu使用SGD来训练模型,初始学习速率为0.01,动量为0.9,权重衰减为10−4,每批16个。学习速率衰减了10倍分别是在第24和33 epoch。
4.2 消融研究
4.2.1 Stop Gradient的效果
在本节中,我们分析了非对称优化方案的效果,即停止附加PSS头相关的梯度传递到原始FCOS网络参数。如图1所示,我们使用回归分支的特征来训练PSS头部。最基本的解决方案是不进行停止操作,并像往常一样更新所有的网络参数。
具体来说,我们的不带stop-gradient的ATSSPSS方法达到了41.6% mAP (w/o NMS),仅比DeFCN高出0.1点,与ATSS基线(42.8%)相比仍有1.2点的性能差距。通过应用stop-gradient操作,ATSSPSS实现了42.6%,几乎与基线的42.8%的map相同。我们对FCOSPSS方法也做了类似的观察,值得注意的是端到端预测结果(w/o使用stop-gradient的NMS)的性能达到了42.3%,比基于NMS的性能提高了0.3%。
进一步验证stop-gradient是否能更好的训练我们的端到端探测器,我们在coco val验证集展示了使用 stop-gradient操作的没有使用 stop-gradient操作训练FCOSPSS和ATSSPSS模型的收敛曲线。如图3所示,我们可以观察到stop-gradient的确帮助训练一个更好的模型,可以在训练过程中不断提高性能。
我们在图2展示了FCOS基线和FCOSPSS预测分类得分的可视化结果。第2 -4组为FCOS基线的分类评分热图,第5 -7组为FCOSPSS的评分热图。三个得分图对应不同的FPN水平(P5, P6, P7)。很明显,与FCOS基线相比,我们用stop-gradient训练的FCOSPSS能够显著抑制重复预测。


4.2.2 Stop Gradient vs. Two-step Training
与网络的其他部分相比,Stop-gradient允许PSS模块被非对称优化;并且可以受益于原始FCOS/ATSS模型的特征表示学习。如果我们分两步进行训练,即先训练FCOS/ATSS模型收敛,然后通过冻结FCOS/ATSS模型单独训练PSS模块,这种两步策略是否有效? 在§3.5讨论了,这两步优化对应于(5)和(6)子问题的优化,使其只收敛于一次交替。
我们在第一步训练一个基线模型36个epoch,然后在第二步训练PSS头部12个epoch。如表3所示,ATSSPSS模型的两步训练达到42.3%的mAP
(端到端训练的为42.6%)。

4.2.3 将PSS与回归vs分类相结合分支
在本节中,我们分析将PSS头部附加到分类分支或回归分支的效果。如表4所示,与附加回归分支相比,将PSS头移动到分类分支会导致端到端预测的性能下降,而一对多预测的性能保持不变。我们因此得出结论,具有回归分支特征的PSS头部更适合于优化。除非另有说明,我们附上在所有其他实验中PSS头到回归分支。回想一下,在最初的FCOS中,我们也观察到,将中心性头部与回归联系起来比将分类分支联系起来效果更好。

4.2.4 PSS Head多层卷积层
因为我们期望学习一个二元分类器进行一对一的预测,头部的容量可能扮演重要角色。我们使用标准的卷积层来帮助学习二进制掩码。为了验证有多少层可以正常工作,基于FCOSPSS和ATSSPSS,我们对层数进行了消融研究。如表5所示,带有两个conv. layers的PSS头获得了满意的精度。有趣的是,将PSS头增加到三个conv.层会略微降低检测性能,这可能是由于过拟合。我们绘制图4中的收敛曲线,表明在开始时,三层PSS得到的mAP效果较好,但之后的mAP效果略差于两层PSS。尽管仔细地调优超参数可能会导致稍微不同的结果,但我们可以在这里得出两个卷积层对于PSS头已经有效。


4.2.5 center-ness分支的效果
为了评估center-ness分支的作用,我们分别在训练的端到端检测器FCOSPSS和ATSSPSS上进行有无center-ness分支消融研究。
与远离实例中心的正样本相比,靠近实例中心的正样本有较大的损失权值。
因此,虽然我们去掉了center-ness分支,但我们仍然保留center-ness作为GIoU loss在训练过程中的loss weight。结果报告在表6中。对于FCOSPSS,center-ness将地map提高0.6个点。这与FCOS基线的观察结果一致(见[25]§3.1.3)。

对于ATSSPSS,center-ness可以提高0.5分。这被认为是一个更好的正例抽样策略,稍微降低了centerness的有效性。
4.2.6 Lpss的损失权重
在这一节中,我们分析了Equ. (1)中PSS损失Lpss的损失权重λ1的敏感性,具体来说,我们用λ1∈不同的值来计算我们的FCOSPSS方法{0.5, 1.0, 2.0}并在表7中报告结果。看来λ1 = 1已经很有效了。

4.2.7 匹配得分函数
为了探索我们FCOSPSS模型中匹配得分函数的最佳公式,我们借用[26]的‘Add’函数形式,由(1−α)·Pˆi(cj) + α·IoU(ˆbi, bj)替换Equ.3中的匹配得分函数。如表8所示,与’ Add ‘相比,’ Mul’函数效果稍好,α = 0.8时,42.3% mAP的检测性能最好。因此,我们使用Mul的函数α = 0.8。

4.2.8 Ranking Loss的效果
为了验证Ranking Loss的有效性,我们分别在经过Ranking Loss训练的FCOSPSS和ATSSPSS检测器上进行了实验。结果见表9,在没有引入较多训练复杂度的情况下,Ranking Loss可以进一步提高最终的检测性能,大概0.2到0.3的map。

4.3. 与SOTA的比较
我们在COCO基准上将FCOSPSS/ATSSPSS与其他最先进的目标检测器进行比较。在这些实验中,我们使用了多尺度训练。特别是,在训练过程中,从[480,800]中采样输入图像较短的一边,步长为32个像素。

根据表1,我们得出以下结论:
- 与标准基线FCOS相比,本文提出的FCOSPSS检测精度略高,计算开销可以忽略不计。
检测map之间的基线差异ATSS和提议的ATSSPSS都小于0.2分。 - 我们的方法优于最近的端到端NMSfree检测器DeFCN。
- 我们的方法显示了大容量骨干网络的性能改进。特别是,我们用可变形的卷积来训练ResNeXt-32×4d-101模型,用可变形的卷积来训练Res2Net-101模型。我们的模型分别达到47.5%和48.5%的mAP,属于最先进的。
我们在图5中显示了一些定性结果。

5. 结论
在这项工作中,我们提出了一个非常简单的修改原来的FCOS检测器(和他的提升版本ATSS)来消除NMS后处理。我们通过将一个紧凑的正样本选择器头附加到FCOS网络的边界框回归分支上来实现这一点,该网络仅由两个conv.层组成。因此,一旦训练,新的检测器可以很容易地部署,而不涉及任何启发式处理。所提出的检测器更简单,端到端的可训练。我们期望看到,在这项工作中提出的设计可能有利于其他实例级识别任务,而不仅仅是边界框对象检测。
参考文献
[1] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas
Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-toend object detection with transformers. In Proc. Eur. Conf.
Comp. Vis., 2020.
[2] Hao Chen, Kunyang Sun, Zhi Tian, Chunhua Shen, Yongming Huang, and Youliang Yan. Blendmask: Top-down
meets bottom-up for instance segmentation. In Proc. IEEE
Conf. Comp. Vis. Patt. Recogn., pages 8573–8581, 2020.
[3] Kai Chen, Jiaqi Wang, Jiangmiao Pang, Yuhang Cao, Yu
Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu,
Jiarui Xu, Zheng Zhang, Dazhi Cheng, Chenchen Zhu, Tianheng Cheng, Qijie Zhao, Buyu Li, Xin Lu, Rui Zhu, Yue Wu,
Jifeng Dai, Jingdong Wang, Jianping Shi, Wanli Ouyang,
Chen Change Loy, and Dahua Lin. MMDetection: Open
mmlab detection toolbox and benchmark. arXiv: Comp. Res.
Repository, 2019.
[4] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. arXiv: Comp. Res. Repository, 2020.
[5] Shang-Hua Gao, Ming-Ming Cheng, Kai Zhao, Xin-Yu
Zhang, Ming-Hsuan Yang, and Philip Torr. Res2Net: A
new multi-scale backbone architecture. IEEE Trans. Pattern
Anal. Mach. Intell., 43(2):652–662, 2021.
[6] Dongyan Guo, Jun Wang, Ying Cui, Zhenhua Wang, and
Shengyong Chen. SiamCAR: Siamese fully convolutional
classification and regression for visual tracking. In Proc.
IEEE Conf. Comp. Vis. Patt. Recogn., 2020.
[7] Kaiming He, Georgia Gkioxari, Piotr Dollar, and Ross Gir- ´
shick. Mask R-CNN. In Proc. IEEE Int. Conf. Comp. Vis.,
pages 2961–2969, 2017.
[8] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.
Deep residual learning for image recognition. In Proc. IEEE
Conf. Comp. Vis. Patt. Recogn., pages 770–778, 2016.
[9] Kang Kim and Hee Seok Lee. Probabilistic anchor assignment with iou prediction for object detection. In Proc. Eur.
Conf. Comp. Vis., 2020.
[10] Tao Kong, Fuchun Sun, Huaping Liu, Yuning Jiang, Lei Li,
and Jianbo Shi. FoveaBox: Beyond anchor-based object detector. IEEE Trans. Image Process., pages 7389–7398, 2020.
[11] Xiang Li, Wenhai Wang, Lijun Wu, Shuo Chen, Xiaolin Hu,
Jun Li, Jinhui Tang, and Jian Yang. Generalized focal loss:
Learning qualified and distributed bounding boxes for dense
object detection. In Proc. Advances in Neural Inf. Process.
Syst., 2020.
[12] Tsung-Yi Lin, Piotr Dollar, Ross Girshick, Kaiming He, ´
Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In Proc. IEEE Conf. Comp.
Vis. Patt. Recogn., pages 2117–2125, 2017.
[13] Tsung-Yi Lin, Priya Goyal, Ross B. Girshick, Kaiming He,
and Piotr Dollar. Focal loss for dense object detection. In ´
Proc. IEEE Int. Conf. Comp. Vis., 2017.
[14] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays,
Pietro Perona, Deva Ramanan, Piotr Dollar, and Lawrence ´
Zitnick. Microsoft COCO: Common objects in context. In
Proc. Eur. Conf. Comp. Vis., pages 740–755, 2014.
[15] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian
Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C.
Berg. SSD: Single shot multibox detector. In Proc. Eur.
Conf. Comp. Vis., 2016.
[16] Yuliang Liu, Hao Chen, Chunhua Shen, Tong He, Lianwen
Jin, and Liangwei Wang. ABCNet: Real-time scene text
spotting with adaptive Bezier-curve network. In Proc. IEEE
Conf. Comp. Vis. Patt. Recogn., 2020.
[17] Han Qiu, Yuchen Ma, Zeming Li, Songtao Liu, and Jian
Sun. Borderdet: Border feature for dense object detection.
In Proc. Eur. Conf. Comp. Vis., pages 549–564, 2020.
[18] Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali
Farhadi. You only look once: Unified, real-time object detection. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2016.
[19] Shaoqing Ren, Kaiming He, Ross B. Girshick, and Jian Sun.
Faster R-CNN: Towards real-time object detection with region proposal networks. In Proc. Advances in Neural Inf.
Process. Syst., 2015.
[20] Russell Stewart, Mykhaylo Andriluka, and Andrew Y. Ng.
End-to-end people detection in crowded scenes. In Proc.
IEEE Conf. Comp. Vis. Patt. Recogn., 2016.
[21] Peize Sun, Yi Jiang, Enze Xie, Zehuan Yuan, Changhu
Wang, and Ping Luo. OneNet: Towards end-to-end one-stage
object detection. arXiv: Comp. Res. Repository, 2020.
[22] Zhi Tian, Hao Chen, and Chunhua Shen. DirectPose: Direct
end-to-end multi-person pose estimation. arXiv: Comp. Res.
Repository, 2019.
[23] Zhi Tian, Chunhua Shen, and Hao Chen. Conditional convolutions for instance segmentation. In Proc. Eur. Conf. Comp.
Vis., 2020.
[24] Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. FCOS:
Fully convolutional one-stage object detection. In Proc.
IEEE Int. Conf. Comp. Vis., 2019.
[25] Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. Fcos: A
simple and strong anchor-free object detector. IEEE Trans.
Pattern Anal. Mach. Intell., 2021.
[26] Jianfeng Wang, Lin Song, Zeming Li, Hongbin Sun, Jian
Sun, and Nanning Zheng. End-to-end object detection with
fully convolutional network. arXiv: Comp. Res. Repository,
2020.
[27] Xinlong Wang, Tao Kong, Chunhua Shen, Yuning Jiang, and
Lei Li. SOLO: Segmenting objects by locations. In Proc.
Eur. Conf. Comp. Vis., 2020.
[28] Xinlong Wang, Rufeng Zhang, Tao Kong, Lei Li, and Chunhua Shen. SOLOv2: Dynamic and fast instance segmentation. In Proc. Advances in Neural Inf. Process. Syst., 2020.
[29] Enze Xie, Peize Sun, Xiaoge Song, Wenhai Wang, Xuebo
Liu, Ding Liang, Chunhua Shen, and Ping Luo. PolarMask:
Single shot instance segmentation with polar representation.
In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2020.
[30] Saining Xie, Ross B. Girshick, Piotr Dollar, Zhuowen Tu, ´
and Kaiming He. Aggregated residual transformations for
deep neural networks. In Proc. IEEE Conf. Comp. Vis. Patt.
Recogn., 2017.
[31] Rufeng Zhang, Zhi Tian, Chunhua Shen, Mingyu You, and
Youliang Yan. Mask encoding for single shot instance segmentation. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn.,
2020.
[32] Shifeng Zhang, Cheng Chi, Yongqiang Yao, Zhen Lei, and
Stan Z. Li. Bridging the gap between anchor-based and
anchor-free detection via adaptive training sample selection.
In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 9759–
9768, 2020.
[33] Xizhou Zhu, Han Hu, Stephen Lin, and Jifeng Dai. Deformable convnets v2: More deformable, better results. In
Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 9308–
9316, 2019.
[34] Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang,
and Jifeng Dai. Deformable DETR: Deformable transformers for end-to-end object detection. In Proc. Int. Conf. Learn.
Representations, 2020.















 312
312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









