






 本文探讨了蛋白质设计领域的最新进展,特别是深度学习如何驱动蛋白质结构建模和功能设计的提升。AlphaFold等方法促进了从头开始设计蛋白质的能力,强调了从功能出发确定结构的重要性,并展示了如何通过数据驱动的方法优化序列以实现期望的功能和结构。
本文探讨了蛋白质设计领域的最新进展,特别是深度学习如何驱动蛋白质结构建模和功能设计的提升。AlphaFold等方法促进了从头开始设计蛋白质的能力,强调了从功能出发确定结构的重要性,并展示了如何通过数据驱动的方法优化序列以实现期望的功能和结构。
今天为大家介绍的是来自Po-Ssu Huang团队的一篇论文。
蛋白质中的信息流是从序列到结构再到功能,每一步都是由前一步驱动的。蛋白质设计的基础是反转这一过程:指定一个期望的功能,设计执行这个功能的结构,并找到一个能够折叠成这个结构的序列。
这个“中心法则”几乎是所有全新蛋白质设计工作的基础。我们完成这些任务的能力依赖于我们对蛋白质折叠和功能的理解,以及我们将这种理解捕捉到计算方法中的能力。
近年来,深度学习衍生的方法在高效和准确的结构建模和成功设计的丰富化方面使我们能够超越蛋白质结构的设计,向功能蛋白质的设计前进。

全新蛋白质设计源于一种将蛋白质折叠的复杂性简化为基本物理原理的愿望。
假设有了对控制蛋白质折叠规则的充分理解,就有可能从头开始创造新蛋白质。随着时间的推移,这一假设已被证实是真实的。
蛋白质设计的指导物理原则很简单,但应用这些原则的过程导致了极其多样化的结构结果,开启了功能性蛋白质设计的新时代。对于蛋白质设计中的许多问题,与计算上操纵或适应天然蛋白质结构以实现期望的功能相比,全新设计变得更为有效。
传统上,蛋白质结构及其与序列的相互作用在能量和生物物理学上是可以理解的:氨基酸残基之间进行的三维相互作用是什么?它们是如何稳定蛋白质链的特定构象或与配体或底物的相互作用的?
用一组原子级物理方程捕获蛋白质的多样行为是有吸引力的,提供了对维持结构的力量的可解释视图。实际上,最早的蛋白质设计方法成功地使用了这种方法来定义新蛋白质的结构,并为新序列重新采样侧链。
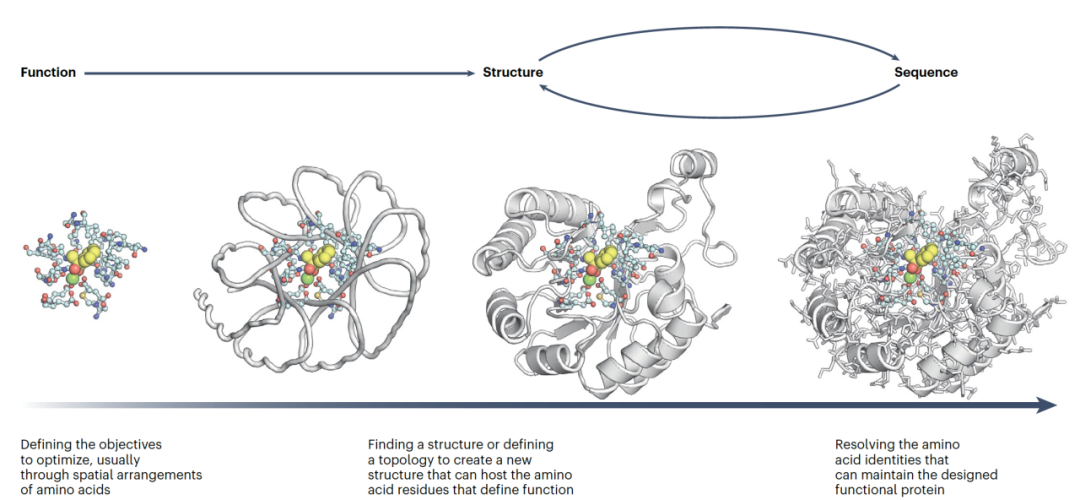
图 1
然而,所有可能的蛋白质构象和序列的空间远大于我们能够在蛋白质折叠或进化的时间尺度上,或任何计算或实验采样方案中彻底探索的范围。然而,通过数十亿年的进化,自然界设法产生了一小部分蛋白质。对于希望在更短的时间尺度上解决问题的科学家来说,利用自然界“答案库”中的数据一直是一个非常有效的策略。
自从通过组装天然蛋白质的片段首次设计出新的蛋白质折叠以来,蛋白质数据库(PDB)中可用的蛋白质数据迅速增长。这使得通过工具(如结构片段库、回归到数据的评分函数、序列和旋转异构体统计)在蛋白质设计中融入数据的作用日益增加,最终导致了具有原子精度的蛋白质结构设计。
随着全新设计方法的成熟,蛋白质的功能也变得重要。蛋白质结构和序列不仅可以从头开始设计,还能完成期望的功能吗?近年来,我们设计功能蛋白质的能力发生了质的变化,因为快速、高性能的结构设计模型结合了对设计序列的AlphaFold精确验证,导致了一个新的功能设计时代,其中蛋白质是从头开始设计以适应功能基序,而不是从现有蛋白质(无论是全新还是天然)改变以支持这些基序。这开启了多个应用,包括超分子组装、跨膜孔和蛋白质、配体和金属结合剂。
从功能推导结构
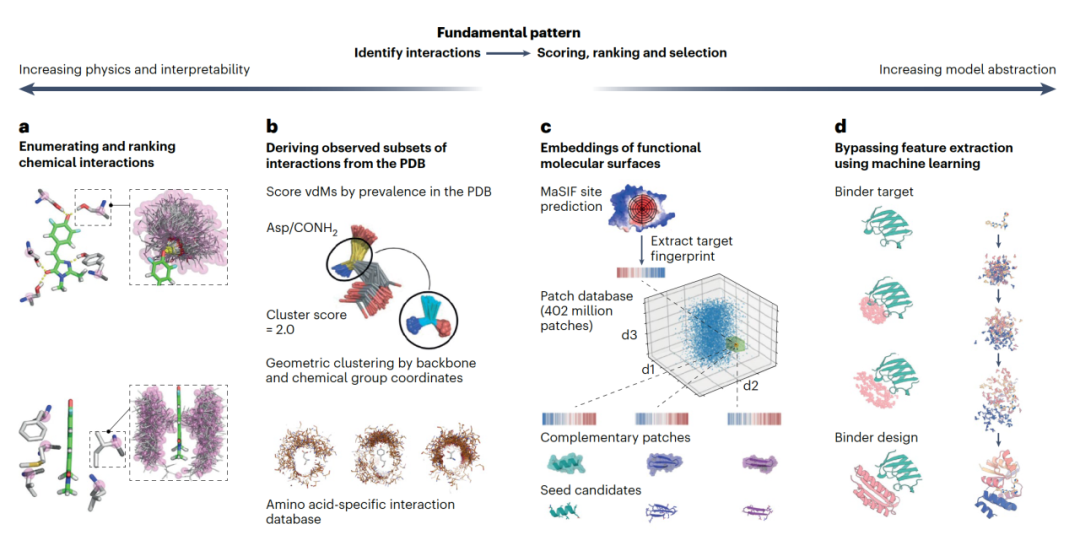
图 2
从头设计功能性蛋白质开始于识别完成预期功能所需的特征。常见目标的例子包括设计与免疫细胞互动的蛋白质,创建药物、核酸或其他蛋白质的结合剂,稳定新酶反应的过渡状态以及开发特异性跨膜通道。无论应用是什么,这些方法都建立在能量稳定和形状互补的原则上。
在早期的全新设计努力中,任何可折叠蛋白质的设计已被视为一项重大成就,而实现功能的努力集中在对这些支架引入变化以容纳功能基序(以最小的方式)。
随着日益强大的设计方法的兴起,首先指定功能基序,然后寻找与此基序一致的蛋白质支架已成为更常见的路径。
在许多情况下,相关的功能基序可以直接从天然蛋白质中提取,并作为全新蛋白质结构的一部分进行支架化。这种策略已被部署到在设计的免疫原表面支架化抗原表位。使用这种方法的其他成功样例包括支架化肽结合基序、金属结合位点和配体结合基序以完成相关的功能任务。
这些基序也可以从自然界中提取以支持设计的功能,例如在设计跨膜通道时,将带正电荷的残基放置在膜-溶剂界面附近。这种方法需要来自已经具有功能的蛋白质作为已知解决方案,以解决感兴趣的问题。
更一般性地设计尚未知功能基序的方法需要将相互作用分解为基本化学元素,并准确处理这些元素的可能组合和排列。一类方法通过考虑目标的化学属性并列举蛋白质可能用于与目标结合的相互作用来解决这个问题。它们也可以直接从PDB中提取,依赖于统计富集来捕捉最有效的相互作用,并可能平均掉更嘈杂的信息,如侧链的灵活性。
对于这些侧链为中心的方法,选择小的、细粒度的化学群体(如酰胺或羰基)增加了独特示例的数量并使其泛化到更复杂的基序。这种相互作用场方法可泛化到任意结合相互作用,并已成功应用于设计针对特异构象小分子配体的全新结合剂、小蛋白结合剂和超高亲和力的全新受体结合剂,单体结合剂到神经毒素和结合到核酸。
从头设计结构
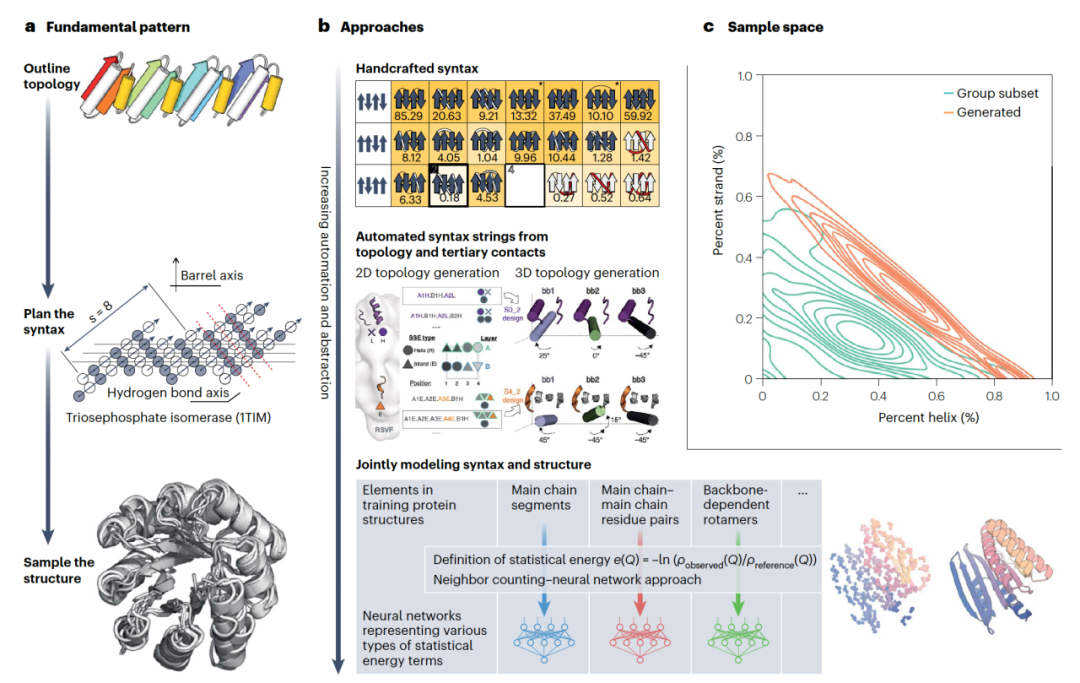
图 3
在定义了功能基序后,设计一个满足其约束的蛋白质结构是蛋白质设计中最具挑战性的方面之一。
传统的基于骨架的设计方法为设计蛋白质结构提供了建模蛋白质结构最可解释的方式。例如,结合关键结构洞察力的设计改进了我们控制β-桶形成结构的能力(图3a),这在酶和膜蛋白应用中很重要。随着对功能约束进行蛋白质结构操作的能力发生巨大变化,深度学习的应用见证了巨大的蛋白质设计变革。
采用类似于原始能量景观基础上的全新设计方法,学习和统计潜力可以代替基于物理的潜力来指导结构搜索,使其具有产生自然界中新结构和拓扑学的类似能力。
使用AlphaFold系统进行高度准确的蛋白质结构预测的到来,以及随后的trRosetta和RoseTTAFold的发展,为生成蛋白质开辟了新的方式。
通过学习将蛋白质序列的分布映射到结构的分布,这些方法似乎在单一的可微网络中编码了关于两者的信息。
探索这些预测模型关于结构学到了什么的努力催生了基于幻觉的方法,这些方法探索了通过优化和重新采样序列输入直到它们产生逼真的输出结构来反转结构预测网络的各种方式。这些方法以大多自动化的方式产生全新蛋白质,无需对之前设计工作进行密集的结构审查和大规模采样。这使得能够广泛且迅速地搜索蛋白质结构空间以寻找设计约束的解决方案,成功地使各种功能基序和输入到新的全新蛋白质中。

图 4
与此同时深度生成模型作为一种强大的策略浮现,用于高效地从大量数据的高维分布中采样。这些模型学习近似从一个易于采样的分布(如高斯分布)到感兴趣的数据分布的映射。
这种方法也可以应用于蛋白质设计,并提供了一种更自然的方式通过构建来生成蛋白质结构,无需对结构预测网络的输入进行修改。
在蛋白质设计中,扩散生成模型(图4)的兴起标志着一个重要的进步,这些模型在保持高样本质量的同时,提供了比其他类型的生成模型更稳定的训练和更好的多样性。这些模型从白噪声开始,并首先去噪粗略特征,然后填充细节,而不是一次性尝试合成完整的原子结构。这种归纳偏差或学习架构,很好地与蛋白质结构的层次性质相符,将结构生成问题分解为首先是高级三级结构组织,然后是局部二级结构,最后是化学细节。
这些模型展示了隐式模型拓扑和语法的能力,在这个过程中选择将蛋白质残基分配到不同类型的二级结构中。随着生成质量的提高,出现了在条件约束下进行快速结构搜索的能力,超越了基于物理和幻想的方法。扩散模型已被用来解决多样化的蛋白质设计问题,成功率比之前的方法高出几个数量级,包括支架基序、生成对称寡聚体和设计金属及蛋白质结合剂。
设计序列以指定结构和功能
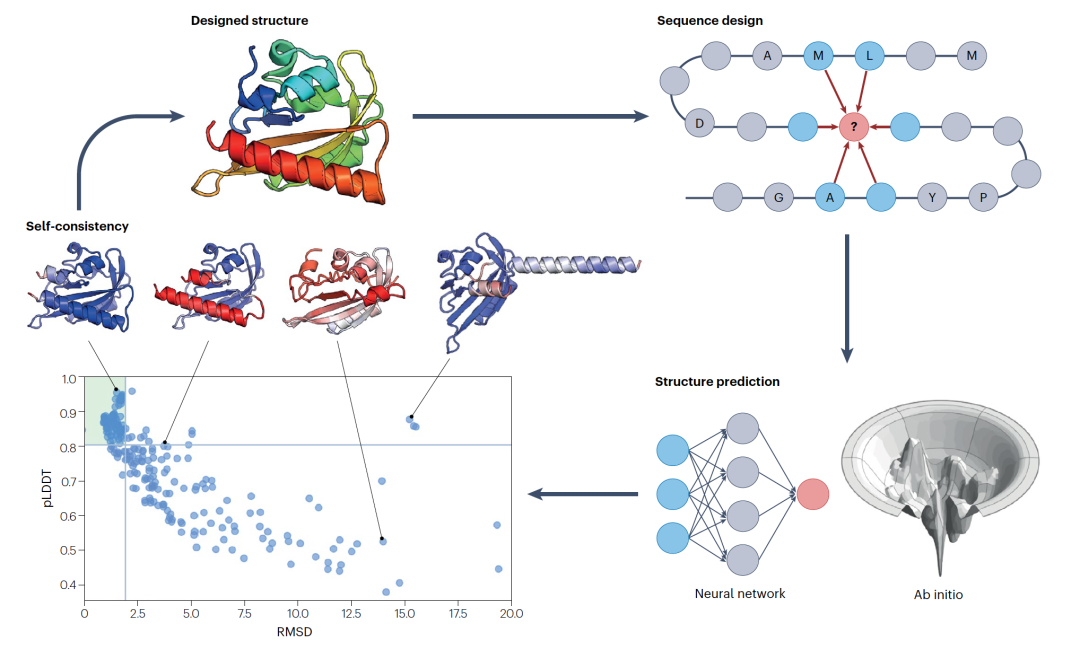
图 5
最终设计目标是只需要一个序列就可以完整描述一个蛋白质,但是一个简单的氨基酸字符串及其推导正确序列的过程,比肉眼所见的复杂得多。
当直接检查序列时,可以分析极性和疏水残基的模式以及甘氨酸和脯氨酸的策略性使用,以提供蛋白质属性的简化图像,例如其二级结构内容或它是否可以是一个膜蛋白。
然而,当与结构一起观察时,序列的每个方面包括长度、模式和氨基酸种类都与其三维结构构成了精妙的一致性。甚至可以公平地说,尽管序列是蛋白质的最终表达形式,但它是为服务于蛋白质结构的功能目的而设定的。
在定义全新蛋白质的序列时,可搜索的序列空间可能比天然蛋白质的更广泛,因为结构成为唯一的约束,不受进化要求的限制。探索局部附近序列(例如,为了改进酶的功能)也是如此。深思熟虑后的序列设计可以揭示蛋白质序列与结构之间相互作用的新见解。
例如对于驱动多肽链进入一个定义良好的折叠,侧链的特异性通常被认为是关键。在研究侧链突变对稳定性的影响时,Koga等人发现了一个违反直觉的结果关于疏水特异性,即在一个理想化的拓扑结构中尽管发生大规模的突变扰动,蛋白质仍然可以保持结构和热力学属性。具体来说,尽管所有埋藏的疏水残基从大到小的侧链发生了突变,蛋白质不仅能够保持折叠,而且还保持了高热稳定性和相同的折叠状态结构。
与结构设计类似,固定骨架序列设计,也称为逆向折叠,也从深度学习和数据驱动的方法中获益。序列空间的组合性质反映了蛋白质结构的特点,随着蛋白质长度的增加而爆炸性增长,可能非常难以搜索。与结构设计一样,结构预测模型提供了一个有效的手段来处理这个空间。
早期工作探索了trRosetta基于目标结构定义序列剖面的能力,引导传统方法更好地符合全局能量景观。后来,幻觉和掩蔽修复方法也被发现对从结构预测网络中提取序列有效。然而,直接在AlphaFold2下使用幻觉优化经常产生对抗性序列,即AlphaFold2高度自信预测但在湿实验室中无法表达的序列。
最有效的序列设计方法受益于目标结构的强约束,这限制了搜索空间:位置的最优氨基酸主要由其局部环境决定。这种归纳偏差被各种类型的序列设计方法大量利用,包括由基于物理或学习到的潜力引导的Gibbs和Metropolis采样算法,以及掩蔽语言和自回归模型。这些方法实现了高度自动化,快速生成高质量序列,几乎不需要或完全不需要手动干预。
过去几年中蛋白质设计最重要的成果之一是能够通过自洽性或可设计性度量来评估设计。以前,计算设计通过从头开始的结构预测进行验证,本质上是由能量函数引导的蛋白质折叠模拟,探测设计序列找到正确结构的能力。这些模拟非常有信息量,提供了关于序列中氨基酸影响的统计和结构见解。然而,它们需要大规模计算但准确度有限,并且与实验成功的相关性差。
随着如AlphaFold这样准确的结构预测方法的出现,比较设计序列的预测折叠和原始设计结构成为可能。相对快速的计算使得能够预测设计序列的折叠状态以及置信度度量(如pLDDT或pAE)。人们可能期望一个被预测以高置信度折叠回设计结构的序列(“自洽的”或“可设计的”)与设计结构更一致,因此可能更有可能在湿实验室中折叠。总的来说,这些发现显著提高了方法开发的速度和效率,因为模型和设计序列可以在计算机中更忠实地评估,无需较慢和更费力的湿实验室验证反馈(图5)。
编译 | 曾全晨
审稿 | 王建民
参考资料
Chu, A.E., Lu, T. & Huang, PS. Sparks of function by de novo protein design. Nat Biotechnol 42, 203–215 (2024).
https://doi.org/10.1038/s41587-024-02133-2
高颜值免费 SCI 在线绘图(点击图片直达)
最全植物基因组数据库IMP (点击图片直达)
往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|















































 1143
1143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









