







(同接上篇博客[Arduino 智能机器人 按指令行走])(http://blog.csdn.net/qazwyc/article/details/56969383)
所需硬件
- 智能小车
- 树莓派3B
- 麦克风(树莓派专用)
- 耳机
环境配置
安装pycurl库
sudo apt-get install python-pycurl配置树莓派支持中文(因为要显示中文)
可参考http://shumeipai.nxez.com/2016/03/13/how-to-make-raspberry-pi-display-chinese.html
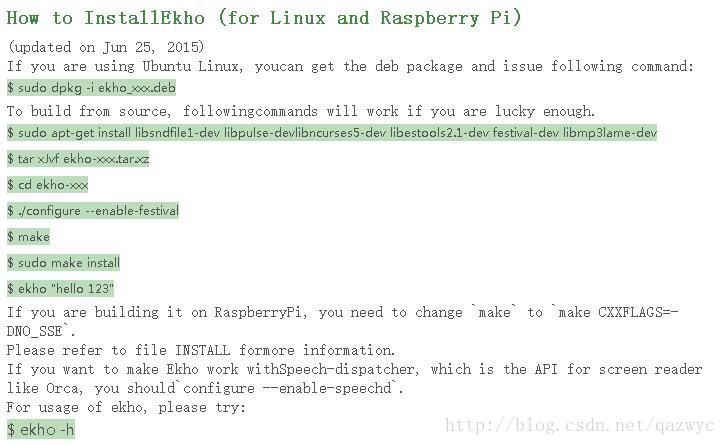
中文语音合成软件 Ekho
根据官方安装说明进行安装。关键的一句是make CXXFLAGS=-DNO_SSE
测试时给树莓派插上耳机线,把树莓派音量调到最大(这个时候不要把耳机带上,否则音量会过大)
amixer -D pulse sset Master 100%运行测试命令:
/ekho "hello 123"这个时候应该可以听到耳机发出微弱的声音。
播放器
如mplayer
sudo apt-get install mplayer
代码
# -*- coding: utf-8 -*-
import numpy as np
from datetime import datetime
import wave
import time
import urllib, urllib2, pycurl
import base64
import json
import os
import sys
import numpy as np
import zmq
import serial, time, sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
filename = '2.wav'
duihua = '1'
# connect arduino
def connect_arduino():
arduino = serial.Serial('/dev/ttyUSB0',9600,timeout=1)
arduino.close()
arduino.open()
return arduino
# 百度语音识别 #
def get_token():
apiKey = "Ll0c53MSac6GBOtpg22ZSGAU"
secretKey = "44c8af396038a24e34936227d4a19dc2"
auth_url = "https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials&client_id=" + apiKey + "&client_secret=" + secretKey;
res = urllib2.urlopen(auth_url)
json_data = res.read()
return json.loads(json_data)['access_token']
def dump_res(buf):
global duihua
print "字符串类型"
print (buf)
a = eval(buf)
print type(a)
if a['err_msg']=='success.':
# print a['result'][0]
# 语音识别结果
duihua = a['result'][0]
print duihua
def use_cloud(token):
# 这里打开文件为2.wav
fp = wave.open(filename, 'rb')
nf = fp.getnframes()
f_len = nf * 2
audio_data = fp.readframes(nf)
cuid = "7519663" #产品id
srv_url = 'http://vop.baidu.com/server_api' + '?cuid=' + cuid + '&token=' + token
http_header = [
'Content-Type: audio/pcm; rate=8000',
'Content-Length: %d' % f_len
]
c = pycurl.Curl()
c.setopt(pycurl.URL, str(srv_url)) #curl doesn't support unicode
#c.setopt(c.RETURNTRANSFER, 1)
c.setopt(c.HTTPHEADER, http_header) #must be list, not dict
c.setopt(c.POST, 1)
c.setopt(c.CONNECTTIMEOUT, 30)
c.setopt(c.TIMEOUT, 30)
# 写回调函数 dump_res
c.setopt(c.WRITEFUNCTION, dump_res)
c.setopt(c.POSTFIELDS, audio_data)
c.setopt(c.POSTFIELDSIZE, f_len)
c.perform() #pycurl.perform() has no return val
# 图灵机器人 可对话 #
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
key = '05ba411481c8cfa61b91124ef7389767'
api = 'http://www.tuling123.com/openapi/api?key=' + key + '&info='
token = get_token()
print "你好,欢迎使用智能小车语音控制系统"
# 这里在1.txt中写入"你好,欢迎使用智能小车语音控制系统",然后通过ekho进行语音合成得到1.wav,之后可直接播放
# os.system('ekho -f 1.txt -o 1.wav')
os.system('mplayer 1.wav')
while(True):
arduino = connect_arduino();
print "请指示"
# 同理这里在2.txt中写入"请指示"并生成了2.wav
os.system('ekho -f 2.txt -o 2.wav')
os.system('mplayer 2.wav')
# 录音并存储为2.wav
os.system('arecord -D "plughw:1,0" -f S16_LE -d 4 -r 8000 /home/pi/yuyinduihua/2.wav')
use_cloud(token)
print "输入内容"
# 录音识别结果
print duihua
# 识别指令控制小车行走
if duihua.find("前进") != -1:
arduino.write('1')
elif duihua.find("后退") != -1:
arduino.write('2')
elif duihua.find("左转") != -1:
arduino.write('4')
elif duihua.find("右转") != -1:
arduino.write('3')
elif duihua.find("转圈") != -1:
arduino.write('8')
#elif duihua.find("停止") != -1:
# arduino.write('9')
#elif duihua.find("加快") != -1:
# arduino.write('+')
#elif duihua.find("减慢") != -1:
# arduino.write('-')
else:
arduino.write('9')
time.sleep(1)
arduino.write('9')
# 通过图灵机器人api得到应答 a
info = duihua
duihua = ""
request = api + info
response = getHtml(request)
dic_json = json.loads(response)
print '机器人: '.decode('utf-8') + dic_json['text']
a = dic_json['text']
print type(a)
# 将a的文本存入3.txt
f=open("3.txt",'w')
f.truncate()
f.write(a)
f.close()
# 通过ekho语音合成为3.wav并播放
os.system('ekho -f 3.txt -o 3.wav')
os.system('mplayer 3.wav')
print "wait..1s"
time.sleep(1)
总结
相对来说代码并不复杂,主要是环境和软件的配置较麻烦,最终实现的功能就是:
- 运行后会听到欢迎 “你好,欢迎使用智能小车语音控制系统”
- 每次在听到”请指示“后说出自己的指令,通过语音识别被转换为文本
- 如果文本包含指令,则发送给智能小车
- 无论文本是否包含指令,都会得到图灵机器人的应答,并通过语音合成使我们能听到















 3976
3976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









