






CNN卷积神经网络 FPGA加速器实现(小型)CNN FPGA加速器实现(小型) 仿真通过,用于foga和cnn学习
通过本工程可以学习深度学习cnn算法从软件到硬件fpga的部署。
网络软件部分基于tf2实现,通过python导出权值,硬件部分verilog实现,纯手写代码,可读性高,高度参数化配置,可以针对速度或面积要求设置不同加速效果。
参数量化后存储在片上ram,基于vivado开发。
直接联系提供本项目实现中所用的所有软件( python)和硬件代码( verilog)。
ID:13200673842464141
文滔武略天下第_
标题:从软件到硬件:小型CNN卷积神经网络FPGA加速器的实现与仿真
摘要:本文介绍了一种基于FPGA的小型CNN卷积神经网络加速器的实现,并通过仿真验证其在深度学习中的应用。该加速器可用于学习深度学习CNN算法的软件到硬件部署过程。在网络软件部分,我们使用TensorFlow 2实现,并通过Python导出权值;在硬件部分,我们使用纯手写的Verilog代码,具有高可读性和高度参数化配置,可以根据速度或面积要求进行不同的加速效果设置。参数量化后,加速器存储在片上RAM中,并使用Vivado进行开发。
关键词:CNN、卷积神经网络、FPGA加速器、深度学习、软件到硬件部署、参数量化、Vivado
引言
随着深度学习的快速发展,卷积神经网络(CNN)在计算机视觉、自然语言处理等领域取得了巨大的成功。然而,由于CNN模型复杂度的增加,传统的软件实现已经无法满足实时性和低功耗的要求。因此,研究人员开始将CNN模型部署到硬件加速器上,以提高计算性能和效率。本文旨在介绍一种小型CNN卷积神经网络FPGA加速器的实现方法,通过仿真验证其在深度学习中的应用。
- 深度学习CNN算法简介
深度学习CNN算法是一种用于图像处理和模式识别的重要技术。它基于神经网络结构,通过卷积、池化和全连接等操作对输入数据进行特征提取和分类。CNN算法具有层次化、自动学习和并行计算等特点,因此在图像分类、目标检测和人脸识别等任务中有广泛的应用。
- FPGA加速器在深度学习中的应用
FPGA作为一种可编程逻辑器件,具有并行计算、低功耗和灵活性等特点,成为实现深度学习加速的重要工具。FPGA加速器通过将CNN模型的计算任务分配到硬件并行处理单元中,利用硬件的并行性加速计算过程。与传统的CPU和GPU相比,FPGA加速器具有更高的计算性能和能耗效率,适用于对计算速度和功耗要求较高的应用场景。
- 小型CNN FPGA加速器的实现
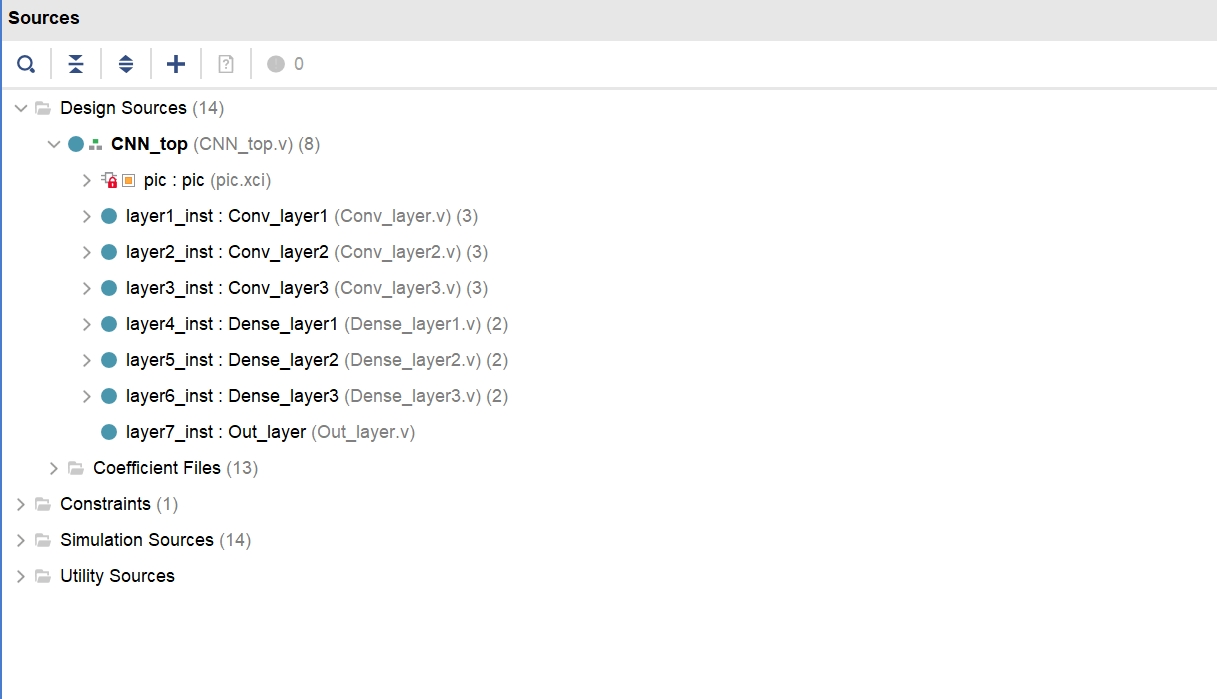
我们采用了一种小型CNN FPGA加速器的实现方法,以满足学习深度学习CNN算法的需求。该加速器分为软件部分和硬件部分。
3.1 软件部分
在软件部分,我们使用了TensorFlow 2作为开发框架,并基于Python实现。首先,我们在TensorFlow中搭建CNN模型,并通过训练获取模型的权值。然后,我们使用Python将训练好的权值导出,以便在硬件部分进行加载和计算。
3.2 硬件部分
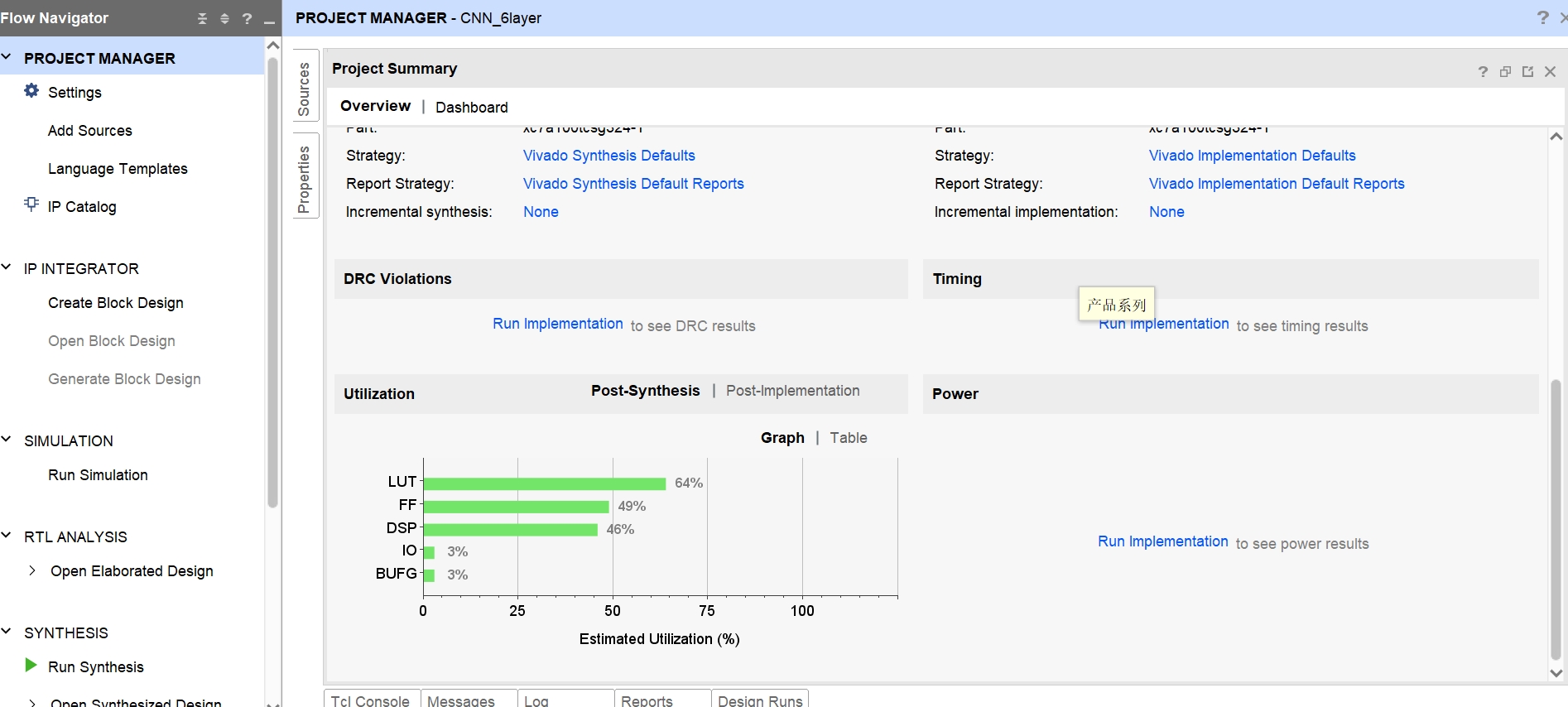
在硬件部分,我们使用纯手写的Verilog代码实现了小型CNN FPGA加速器。代码具有高可读性和高度参数化配置,可以根据应用的速度或面积要求进行不同的加速效果设置。加速器的核心功能是卷积、池化和全连接等操作的硬件实现,通过将计算任务分配到FPGA中并利用其并行计算能力实现加速。此外,为了减小存储开销,我们对参数进行量化,并将其存储在片上RAM中以提高访问速度。
- 仿真与验证
为了验证小型CNN FPGA加速器的功能和性能,我们使用了Vivado进行仿真。在仿真过程中,我们通过加载软件部分导出的权值并将输入数据送入加速器进行计算。通过对比加速器计算结果与软件实现的结果,我们可以验证加速器的正确性和加速效果。
- 结论
本文介绍了一种基于FPGA的小型CNN卷积神经网络加速器的实现方法,并通过仿真验证了其在深度学习中的应用。该加速器可以作为学习深度学习CNN算法的软件到硬件部署的参考工程。通过软件部分的TensorFlow实现和硬件部分的Verilog实现,我们可以了解深度学习CNN算法从软件到硬件的部署过程,并通过参数化配置实现不同的加速效果。通过对参数进行量化并存储在片上RAM中,我们可以减小存储开销并提高访问速度。通过Vivado的仿真验证,我们可以验证加速器的功能和性能。
备注:如需获得本项目实现中所用的所有软件(Python)和硬件代码(Verilog),请直接联系作者。
参考文献:
[1] Lecun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. nature, 521(7553), 436-444.
[2] Zhang, C., Li, P., Sun, G., Guan, J., Wang, Y., & Wang, X. (2015). Optimizing FPGA-based accelerator design for deep convolutional neural networks. ACM Transactions on Reconfigurable Technology and Systems (TRETS), 8(3), 1-18.
相关的代码,程序地址如下:http://wekup.cn/673842464141.html
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









