







部署大型语言模型(LLMs)在本地变得越来越流行,因为它们增强了数据隐私,具有成本效益,并且不依赖网络。Ollama是一个流行的本地LLM部署工具,支持广泛的开源LLMs,并提供直观的体验,非常适合单用户、本地环境。然而,当扩展到单用户应用之外时,比如为成千上万的用户服务的聊天机器人Web应用程序,就会出现挑战。Ollama能否满足在云端扩展的要求呢?

云端LLM部署
在我们评估Ollama在云环境中的表现之前,理解云端部署LLMs的含义和涉及的关键要求非常重要。云端部署不仅仅是在云基础设施上托管和运行这些模型;它涉及与本地部署根本不同的一系列要求。
在云端运行LLM的关键要求可能包括:
-
高吞吐量和低延迟:在云环境中,LLM必须有效地处理大量请求并快速返回响应。高吞吐量确保模型可以同时处理多个请求而不出现瓶颈,而低延迟对于维护无缝的用户体验至关重要,尤其是在需要即时反馈的实时应用中,比如会话AI代理。
-
可扩展性:云的动态特性允许你根据需求上下扩展资源,从而确保成本效益。这对于预计会随着时间增长或经历不同使用模式的LLM应用尤为重要。
-
多用户支持:与可能只服务单个用户或有限群体的本地部署不同,云端部署的LLM必须能够同时支持多个用户。
理解这些要求是评估技术是否能满足云端部署需求的第一步。后面我们将看看Ollama在云环境中的表现如何。
在云端运行Ollama
咱们把Ollama从本地部署搬到云上,用了个A100-80G GPU实例上的Llama 3 8B模型来测试。我们特别关注了对云部署特别关键的那些性能指标。下面是我们发现的一些详细情况。
吞吐量
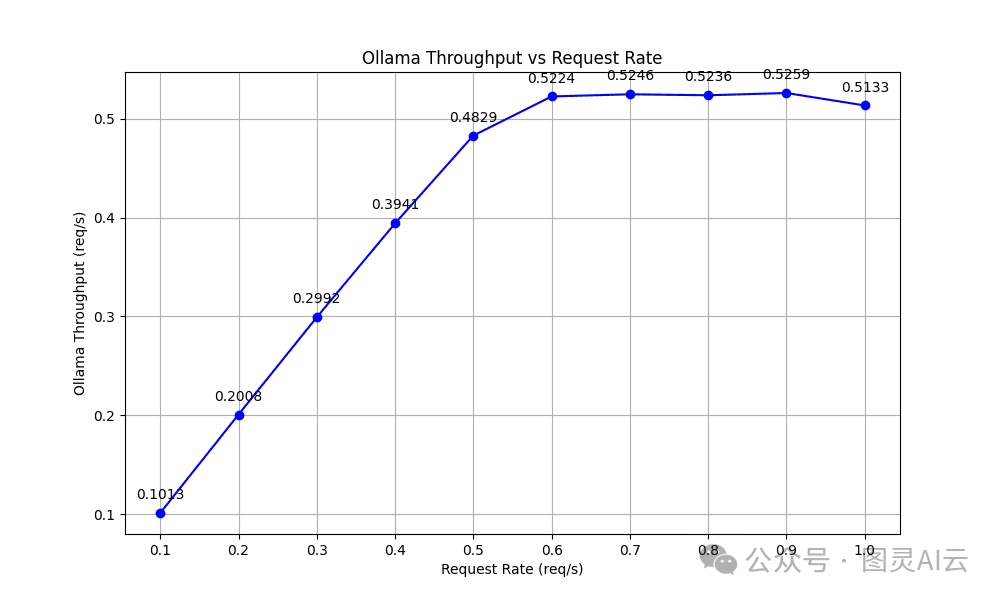
吞吐量是个挺重要的性能指标,它显示了系统处理进来的请求有多高效。我们测试发现,Ollama的吞吐量随着流量增加并没有跟着增加,而且在请求率达到0.5个请求每秒后就保持不变了。这是因为Ollama已经达到了它的最大解码能力,多余的请求就得排队等着,而不是马上处理。
首个令牌生成时间(TTFT)
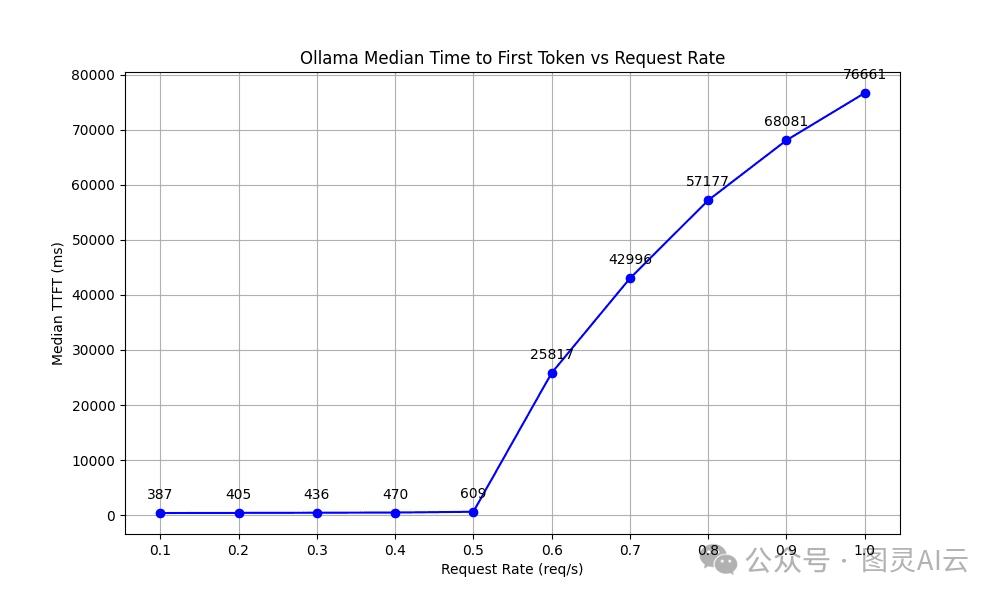
TTFT(Time to First Token)是衡量系统反应速度的一个指标,它记录了从发送请求到生成第一个令牌需要多长时间。这个指标对于那些需要即时反馈的应用来说特别重要,比如交互式的聊天机器人。
我们的测试结果显示,TTFT在0.5 req/s之前还保持得挺稳定的,但超过了这个点,因为请求排队的延迟,TTFT就显著地、无限制地增加了。
每个输出令牌的时间(TPOT)
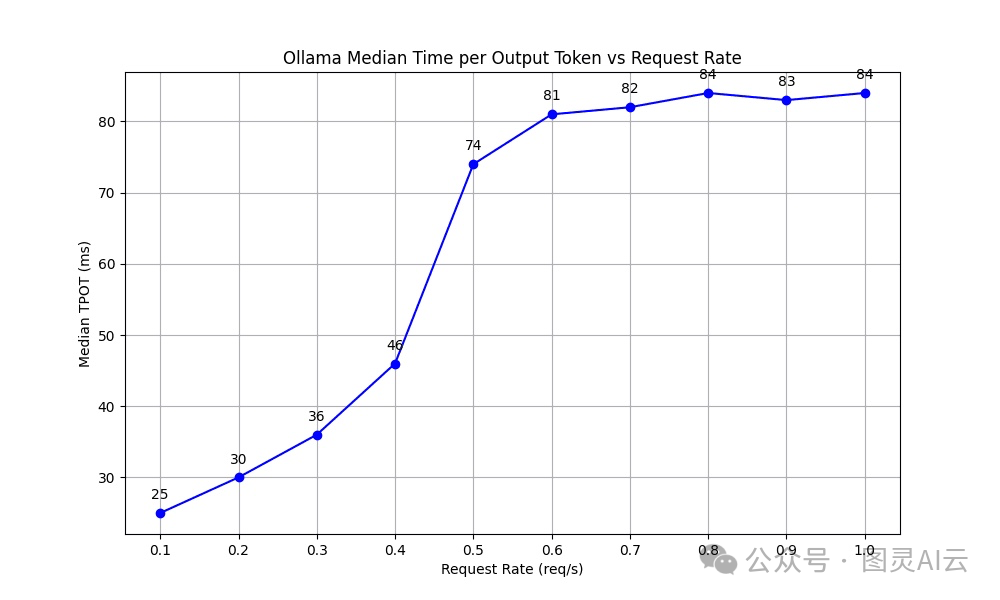
TPOT(Time per Output Token)这个指标显示了处理每个令牌的速度,这对于保持实时应用里的快速交互特别重要。我们注意到,当请求率上升到0.5个请求每秒时,TPOT稳定地增加,然后保持在81到84毫秒的一致时间里。
令牌生成率(TGR)
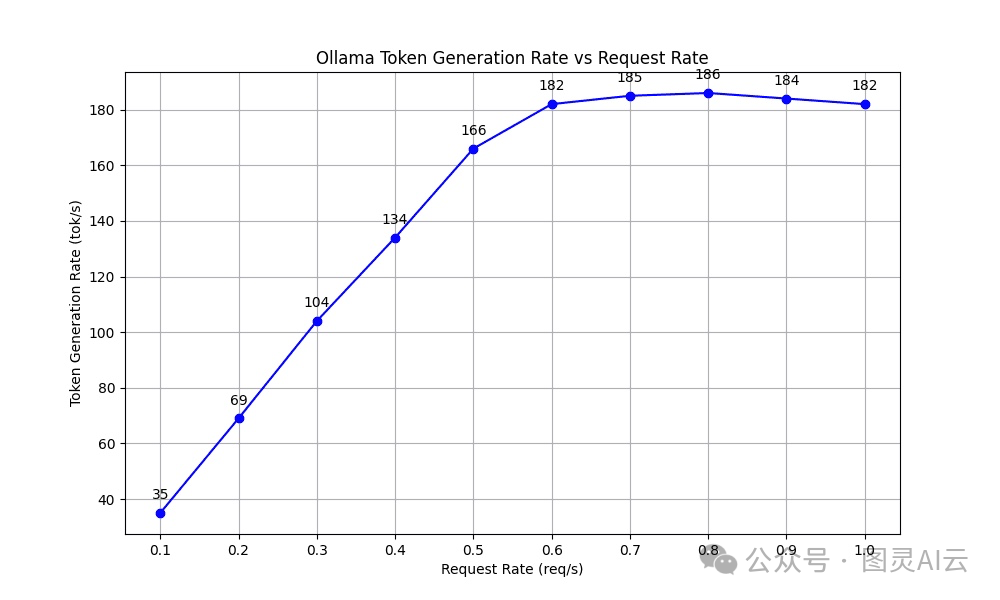
TGR(Token Generation Rate)这个指标是用来评估模型在解码过程中每秒能生成多少令牌的。我们的测试结果显示,随着请求率的上升,TGR也在稳步增加,当请求率超过0.5个请求每秒时,它稳定在大约182到186个令牌每秒。
从这些指标我们可以看出,虽然Ollama在请求率比较低的时候(达到0.6个请求每秒)表现还不错,但在云部署中典型的高负载情况下,它可能就不够用了。就像我们之前说的,云上的LLM部署需要有持续的高吞吐量、低延迟,还得能扩展,这样才能应付多个用户的请求。
这也意味着我们需要一个解决方案,它既要像Ollama那样对用户友好,又要能满足云上LLM应用对吞吐量和响应性的高要求。
OpenLLM:云上跑任何LLM
现在,开源项目OpenLLM也进行了一次大升级,变成了一个简化的工具,用来运行LLMs作为OpenAI兼容的API端点,特别注重易用性和性能。它用上了vLLM和BentoML的推理和服务优化,现在对那些需要高吞吐量的场景做了特别的优化。
下面是OpenLLM的一些关键特点:
最牛的性能
OpenLLM针对那些需要高吞吐量和低延迟的场景做了优化,这让它成为了在云上运行实时AI代理的一个超棒的工具。下面我们来看看OpenLLM和Ollama在处理单个A100-80G GPU实例上的并发请求时的性能对比:
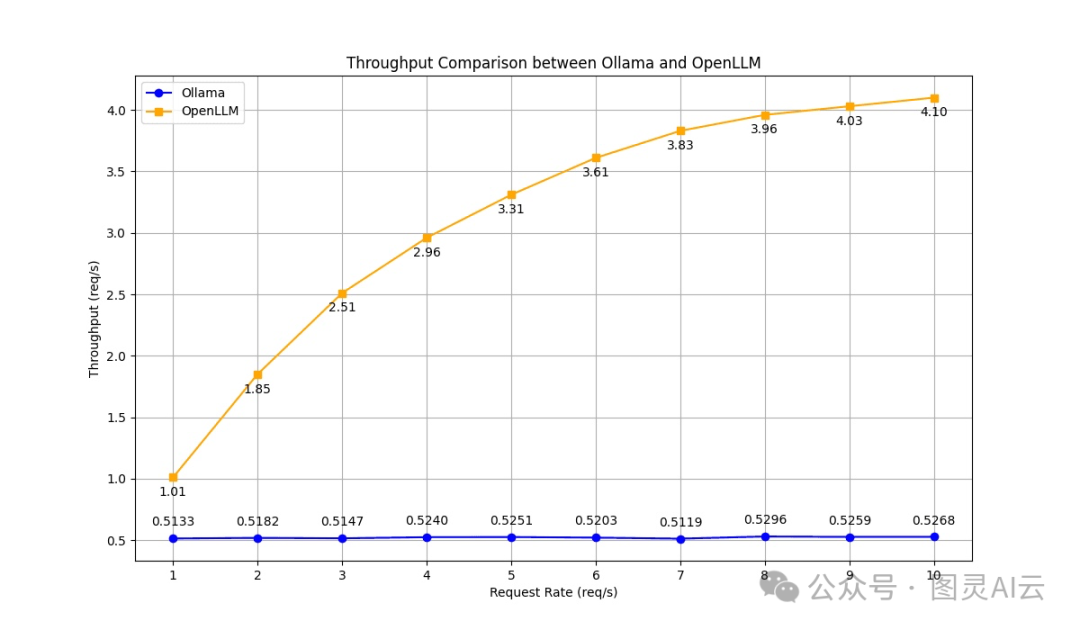
吞吐量
Ollama在测试期间的吞吐量大概保持在每秒0.5个请求,而OpenLLM展示了随着负载增加的稳定提升,达到了在每秒10个请求的负载下每秒4.1个请求,几乎是Ollama的8倍。
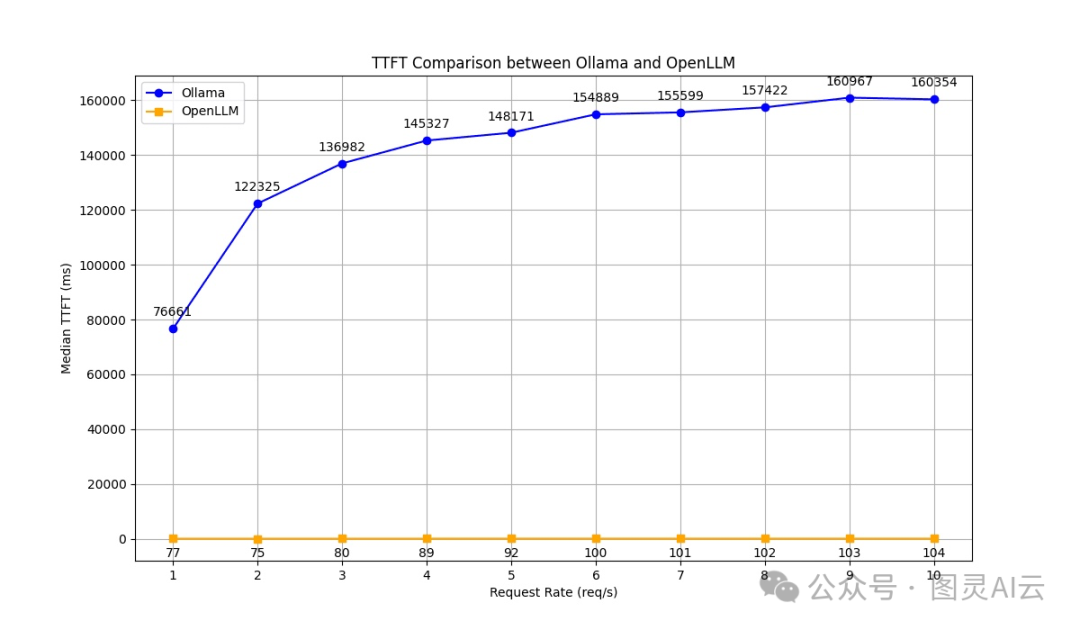
首个令牌生成时间(TTFT)
OpenLLM在所有请求率下都展现出比Ollama更低的TTFT,这说明它有更好的反应能力。
每个输出令牌的时间(TPOT)
OpenLLM在各种请求率下,都比Ollama的TPOT快得多,差不多快了4到5倍。在请求不是很多的时候,这个优势特别明显。
令牌生成率(TGR)
和Ollama比起来,OpenLLM在请求率增加的时候,TGR也在上升,而且起始的基础速率就更高(265个令牌每秒)。这说明它的效率更好,尤其是当OpenLLM达到每秒1586个令牌的高请求率时,比Ollama的速率快了8倍以上。
OpenAI兼容API
OpenLLM让你能运行各种开源LLMs,比如Llama 3、Qwen 2、Mistral和Phi3,作为OpenAI兼容的API端点。这样就能无缝、直接地用上LLMs。
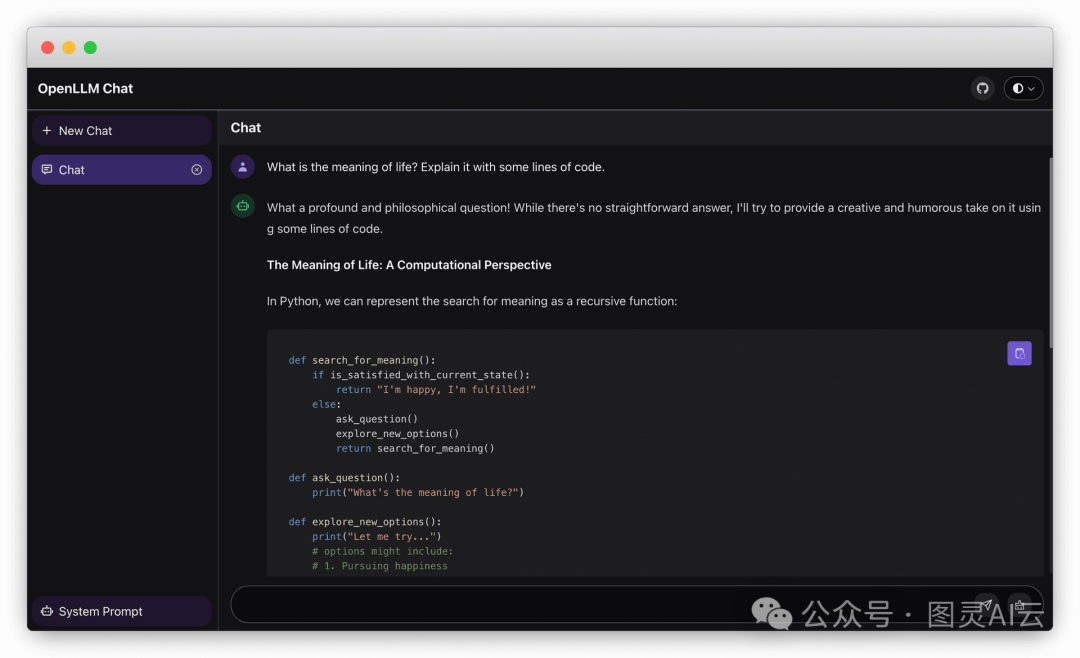
聊天UI
OpenLLM还为LLM服务器的/chat端点提供了一个内置的聊天界面。在这个界面里,你可以和模型进行多个对话。
结论
如果你想在笔记本上自己用LLM,Ollama是个不错的选择,它用起来简单,功能也很友好。但是,如果你要在云上支持很多用户的应用,就需要一个能跟着云的需求扩展的解决方案。我们的测试显示,OpenLLM在这方面做得更好。它不仅保留了Ollama的易用性,还把它扩展到了云上,快速扩展和最先进的推理性能,让它成为了对云端AI应用要求严格的理想选择。
参考资料:
-
https://github.com/bentoml/OpenLLM
-
https://github.com/ollama/ollama


















 6418
6418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









